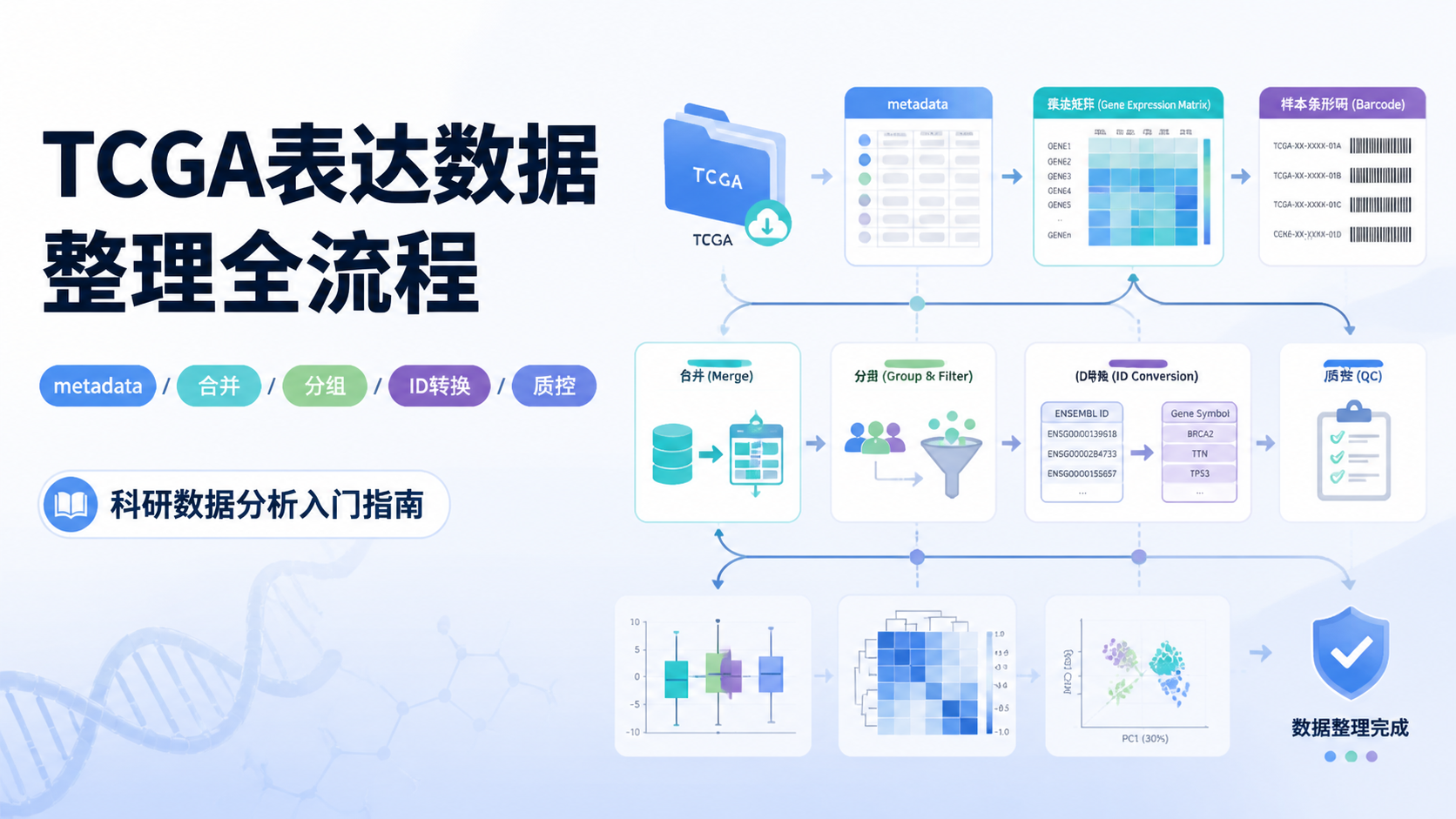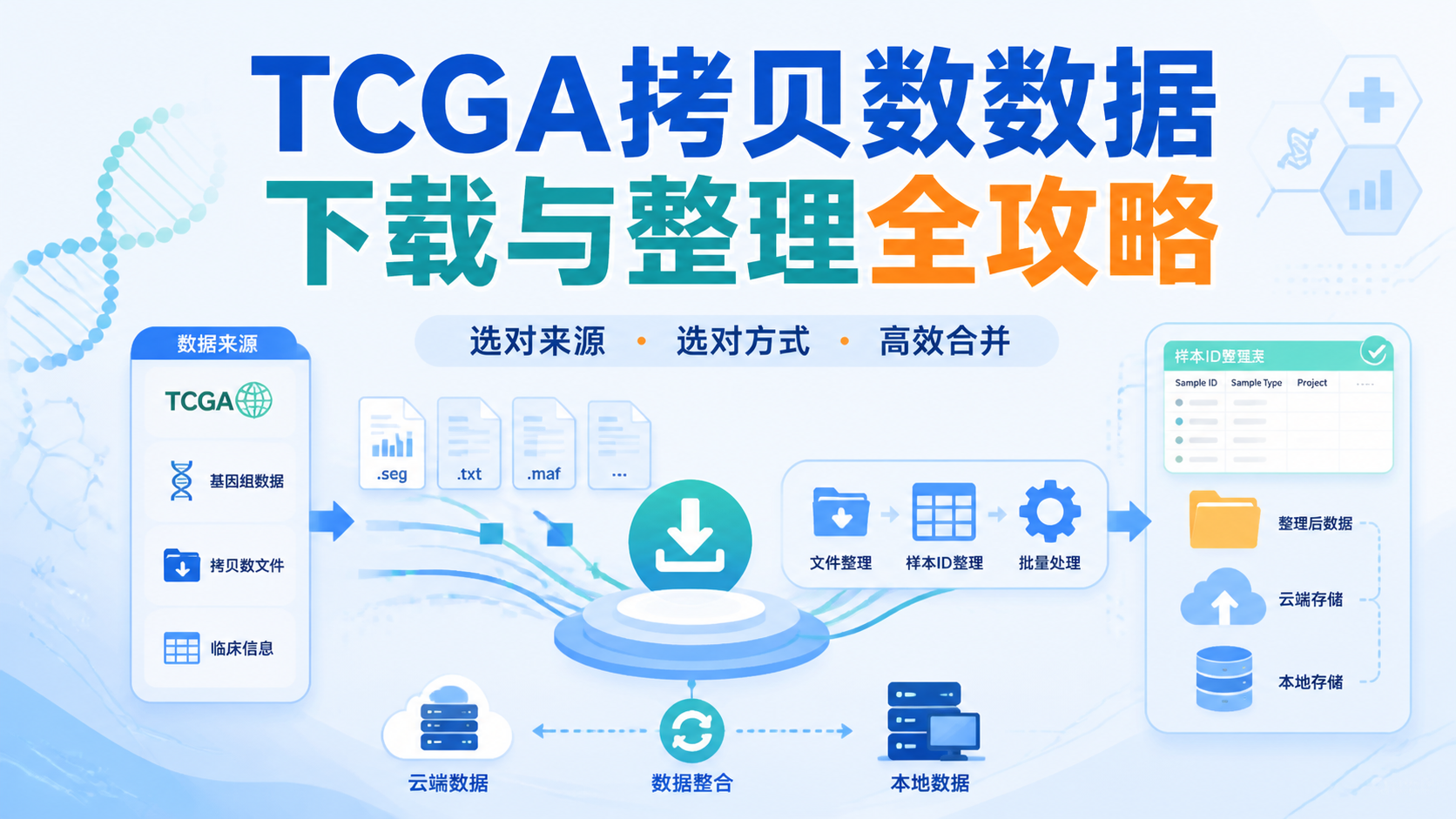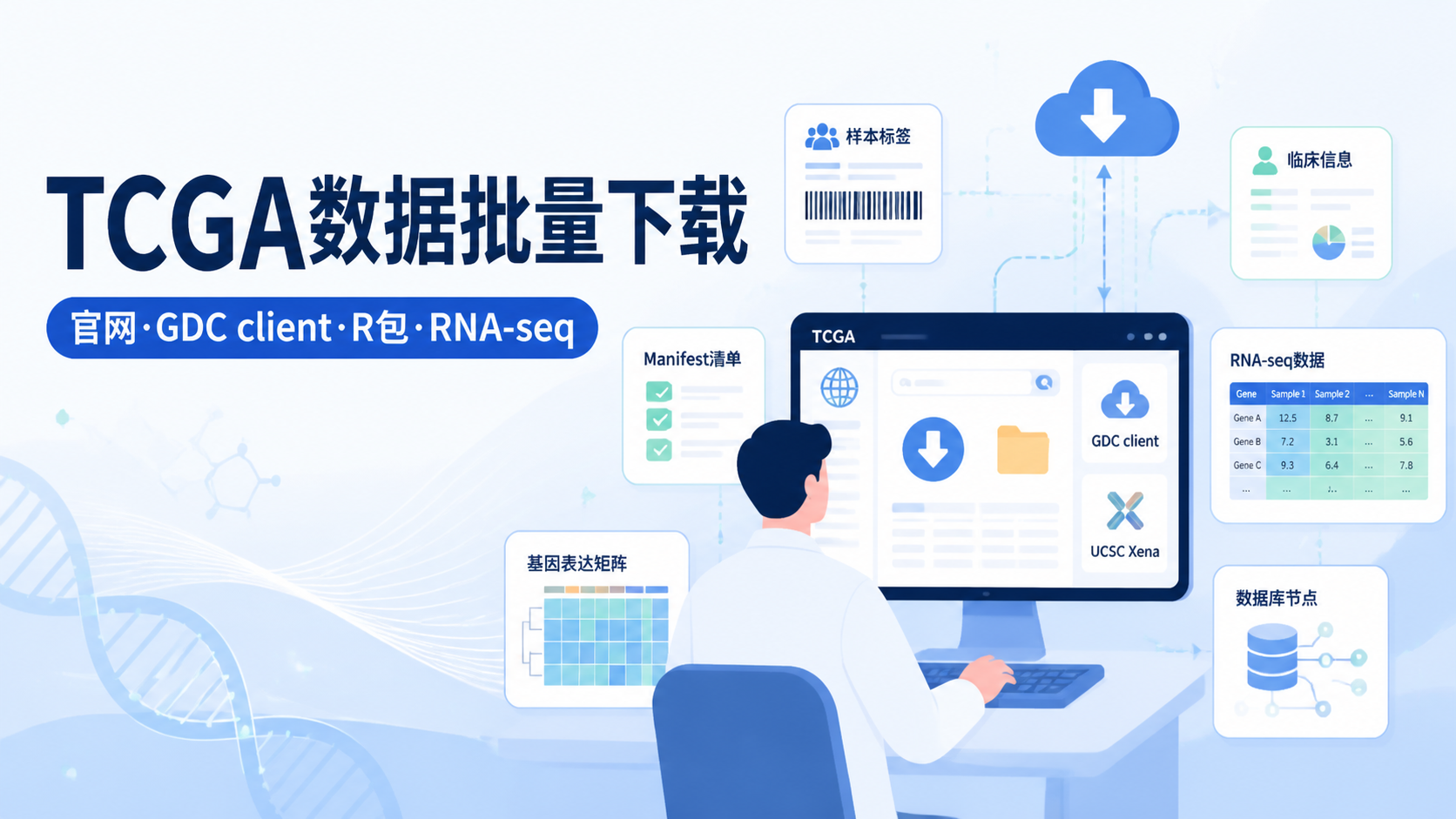
引言Introduction
TCGA数据批量下载看似简单,真正卡住人的往往是检索、格式选择和下载工具配置。对医学生、医生和科研人员来说,最常见的问题不是“有没有数据”,而是“如何快速、准确、可复现地批量拿到目标数据”。
1. 先弄清TCGA数据从哪里下
1.1 三个常用入口
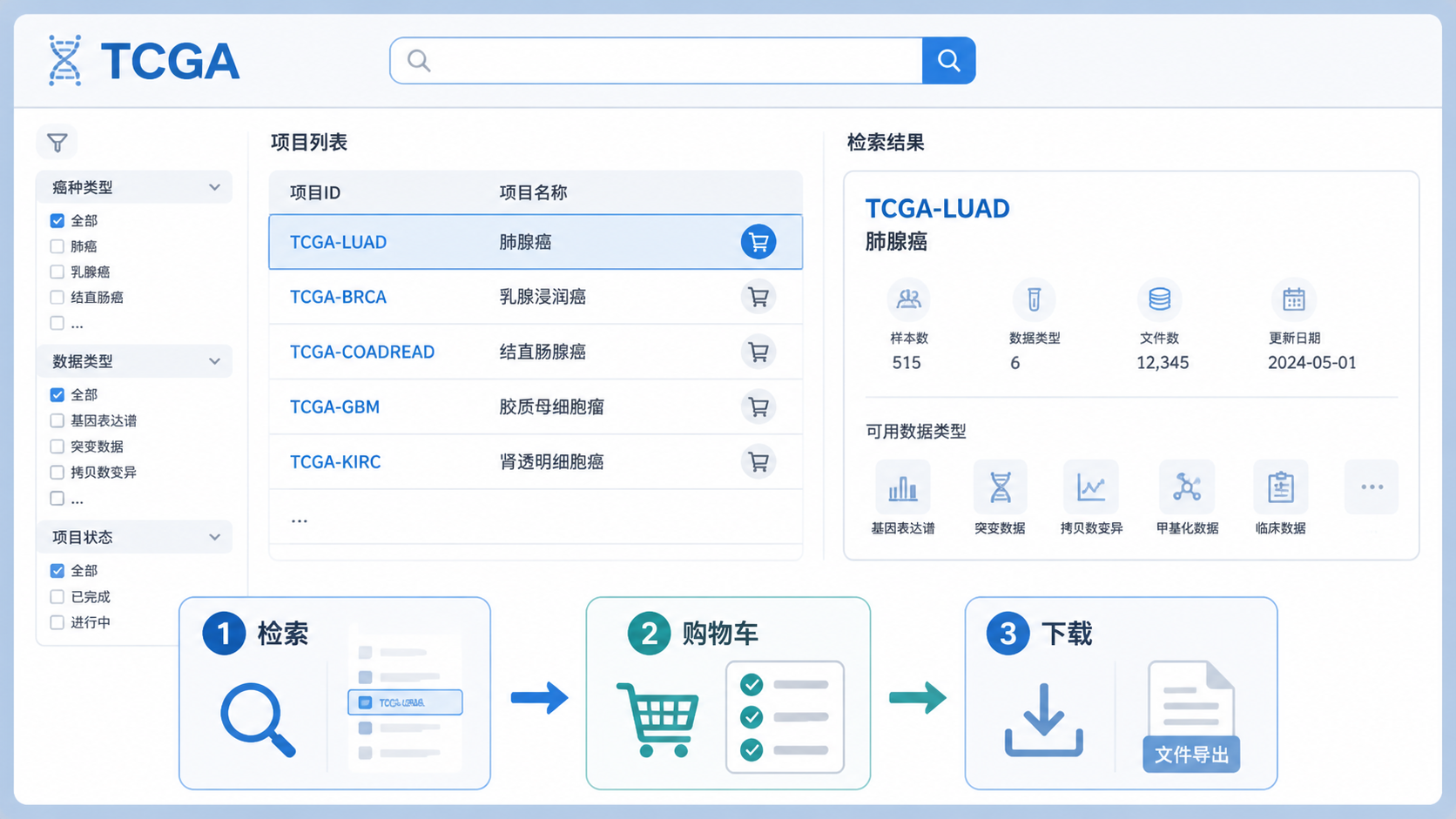
TCGA官方数据入口主要有三类检索方式,分别是project、exploration和repository。实际做TCGA数据批量下载 时,最常用的是repository模块,因为它能把不同条件组合后直接加入购物车下载。
- project:按项目、疾病类型、数据分类、实验策略筛选。
- exploration:按cases、genes、clinical、mutations检索。
- repository:按files和cases精细筛选,是最终下载入口。
如果你的目标是批量下载表达矩阵和临床信息,优先从repository开始。
1.2 TCGA能下载哪些数据
TCGA覆盖的数据类型很广,常见包括:
- 转录组测序数据
- 临床数据
- DNA甲基化数据
- 蛋白组数据
- 突变数据
- CNV数据
- microRNA数据
在课程知识库中,TCGA改版后可见67个部位肿瘤、20个项目,疾病类型约59种。对大多数下游分析而言,最常用的是RNA测序数据和临床数据。
1.3 数据级别要先选对
做TCGA数据批量下载 前,先区分数据层级。常见有三类:
- Level 1,原始测序数据。
- Level 2,比对后的bam文件。
- Level 3,处理并标准化后的数据。
如果目标是差异表达、生存分析、分组比较,通常优先选Level 3或已经整理好的表达矩阵。
如果要做更底层的流程复现,才考虑原始数据。
2. 用TCGA官网批量下载的标准流程
2.1 先在repository里筛选
以TCGA COAD RNA测序数据为例,可按如下思路筛选:
- Program选择TCGA。
- Primary site选择结肠。
- Experimental strategy选择RNA测序。
- 进一步查看右侧图形分布。
筛选后,可进入repository模块,选择access为open,再点击add all files to cart 。
这一步的核心不是“点下载”,而是先把条件筛到位。
否则后续下载到的文件会混杂,清洗成本很高。
2.2 购物车里看什么
进入CART后,通常会看到三类信息:
- clinical:临床信息。
- metadata:样本对应信息。
- expression或相关测序文件:实际下载主体。
对做生信分析的人来说,metadata很关键。它能帮助你把样本名、TCGA ID、临床信息对应起来。
没有这一步,后面很容易发生样本错配。
2.3 用manifest文件提高可重复性
在下载页可以看到:
- Cart:可直接下载。
- Manifest:用于GDC client批量下载。
- Metadata:样本标识映射。
- Clinical:临床信息。
如果样本较少,网页直接下载也可以。
但如果是TCGA数据批量下载 ,更推荐用manifest配合GDC client。
manifest的意义在于可追踪、可复现、便于二次核查。
3. 三种批量下载方式,怎么选
3.1 方式一,官网直接下载
适合:
- 样本数少。
- 网络稳定。
- 临时验证数据可用性。
优点是上手快。
缺点是大批量时不够稳定,效率也一般。
3.2 方式二,GDC client批量下载
这是官方推荐的批量下载工具。适合:
- 文件量大。
- 需要长期复现。
- 需要按manifest批量拉取。
基本流程是:
- 下载并解压GDC client。
- 配置环境变量。
- 用CMD检查是否可用。
- 切换到manifest所在目录。
- 运行下载命令。
常用检查命令是:
GDC-client -h
如果能正常显示帮助信息,说明环境变量配置成功。
随后使用类似下面的命令下载:
GDC-client download -m manifest文件名
对于真正的TCGA数据批量下载,GDC client是最稳妥的方案。
3.3 方式三,R包下载
知识库中提到,最常用的是TCGAbiolinks。常见流程如下:
- 安装并加载TCGAbiolinks。
- 用GDCquery查询项目和数据类型。
- 用GDCdownload下载数据。
- 再整理读取成分析对象。
例如下载TCGA-LIHC的Counts数据,核心参数包括:
- project = TCGA-LIHC
- data category = Transcriptome Profiling
- data type = Gene Expression Quantification
- workflow type = HTSeq-Counts
R包方式适合“下载加整理”一体化处理,尤其适合后续分析直接接代码。
4. RNA测序数据怎么批量下得更准
4.1 先区分Counts、FPKM和FPKM-UQ
在UCSC Xena等替代网站里,RNA数据通常可见三种形式:
- Counts
- FPKM
- FPKM-UQ
其中Counts更接近原始计数,适合常规差异分析。
FPKM和FPKM-UQ适合表达量展示或某些标准化分析场景。
选择前要先想清楚下游分析方法。
如果后续要做DESeq2或edgeR风格分析,通常优先考虑Counts。
4.2 Gene Expression Quantification包含什么
在知识库中明确提到,Gene Expression Quantification包含mRNA和lncRNA数据。
而miRNA数据需要单独选择。
这意味着你不能只看“转录组”四个字就直接下载。
数据类型和工作流类型必须同时匹配。
4.3 样本选择要和研究问题一致
举例来说,如果研究亚洲人、病理学一期和二期TCGA肝癌RNA测序数据,可以在clinical中加入限制条件:
- race选择Asian。
- HCC分期选择stage I和II。
- 再进入repository查看文件。
这类筛选能显著减少无关样本。
对临床转化研究尤其重要。
5. 替代网站也能做批量下载
5.1 UCSC Xena适合快速取数
UCSC Xena提供TCGA下载通道,且支持多个队列和数据集。以GDC TCGA Liver Cancer为例,可以下载:
- RNA数据
- DNA甲基化数据
- 临床数据
- SNP数据
- CNV数据
- MicroRNA数据
它的优势是界面直观。
适合快速获取表达矩阵和临床表型。
如果你主要目的是快速启动项目,UCSC Xena非常实用。
5.2 Firehose也可作为补充
Firehose是Broad开发的TCGA在线分析和下载网站,可覆盖TCGA多癌种数据。知识库提示它能下载33种癌症数据。
不过部分链接有时不易打开,因此更适合作为备用方案。
批量下载时,官方GDC和TCGAbiolinks仍是主力。
替代网站更适合补充和交叉验证。
6. 批量下载后,如何避免常见坑
6.1 先核对样本数量
下载完成后,先检查样本数量是否与预期一致。
这是最基础的一步,也是最容易被跳过的一步。
建议至少核对:
- 下载文件数。
- 样本ID数。
- 临床记录数。
- 表达矩阵列名与样本对应关系。
批量下载不是结束,核对才是开始。
6.2 临床信息不要只看简版
TCGA临床数据包含很多层信息,例如:
- 人口学资料
- 诊断资料
- 治疗信息
- 暴露因素
- 生存信息
在知识库中还提到,XML格式临床信息更全面。
如果研究预后或疗效,建议逐项查看,避免漏掉关键变量。
6.3 工作目录和路径尽量英文
知识库提到,若下载失败,可尝试把工作目录设置为全英文。
这是一个很实用的经验点,尤其在Windows环境下。
路径规范化,能减少很多不必要的下载错误。
7. 用解螺旋产品把流程做得更快
7.1 你真正缺的不是数据,而是标准流程
很多人卡在TCGA数据批量下载 ,并不是不会点按钮,而是不知道该选什么、怎么下、下完怎么对齐。
如果前面检索条件不统一,后面分析就会反复返工。
7.2 解螺旋能帮你把下载思路落地
如果你希望更快搭建TCGA下载与整理流程,可以结合解螺旋的课程、代码模板和实战路径,直接把以下环节串起来:
- 数据检索。
- Manifest批量下载。
- 临床数据整理。
- 表达矩阵读取。
- 样本匹配与清洗。
这类标准化工具的价值,不是替你思考,而是帮你少走重复弯路。
7.3 从下载到分析,越早标准化越省时间
对科研人员来说,真正影响效率的往往不是算法,而是数据入口。
当你把下载、筛选、整理流程标准化后,后续差异分析、生存分析、机器学习建模都会更顺。
把TCGA数据批量下载做规范,等于把整个项目的地基打稳。
这也是解螺旋这类工具最适合介入的环节。
总结Conclusion
TCGA数据批量下载并不复杂,但前提是选对入口、选对数据类型、选对下载方式。官方GDC适合规范化批量获取,UCSC Xena适合快速下载,TCGAbiolinks适合下载与整理一体化。对医学生、医生和科研人员来说,最重要的是把样本筛选、manifest下载和临床匹配做准确。

如果你想把TCGA数据批量下载 真正变成可复制的工作流,可以进一步借助解螺旋的实战内容和工具支持,让下载、整理、分析一步接一步,少试错,更高效。
- 引言Introduction
- 1. 先弄清TCGA数据从哪里下
- 2. 用TCGA官网批量下载的标准流程
- 3. 三种批量下载方式,怎么选
- 4. RNA测序数据怎么批量下得更准
- 5. 替代网站也能做批量下载
- 6. 批量下载后,如何避免常见坑
- 7. 用解螺旋产品把流程做得更快
- 总结Conclusion