引言Introduction
TCGA数据库实操 是很多医学生、医生和科研人员入门生信时最常卡住的一步。数据多、入口杂、下载慢,常常不是不会分析,而是找不到正确的数据。本文用最实用的方式拆解TCGA检索、下载和分析思路,帮助你少走弯路。

1. 先搞清TCGA数据库能做什么
1.1 TCGA的核心价值
TCGA全称是癌症基因组图谱,由美国国家癌症研究所和国家人类基因组研究所于2006年联合建立。它覆盖33种癌症类型,包含超过2万个病人的肿瘤及正常组织分子数据。总数据量超过2.5PB。
对做肿瘤相关研究的人来说,TCGA数据库实操的意义很明确。它能快速提供转录组、甲基化、拷贝数变异、SNP、临床信息等数据,适合做差异分析、预后分析、功能富集和分子互作分析。
如果你的课题需要“先找数据,再找切入点”,TCGA是最常用的起点。
1.2 常见数据类型与研究场景
TCGA常见数据类型包括:
- 基因表达数据
- microRNA表达数据
- DNA甲基化数据
- 拷贝数变异
- SNP和突变数据
- 临床结局数据
这些数据可以组合成不同研究路径。比如,转录组数据可做差异分析。临床数据可做生存分析。甲基化数据可用于机制补充。突变数据可用于解释分子异质性。
做TCGA数据库实操时,先明确“疾病类型、数据类型、分析目标”,再动手下载。
1.3 研究思路的起点
课程中强调了两个关键来源。第一,疾病领域决定研究方向。第二,问题来自文献阅读。也就是说,TCGA不是单纯“找个数据跑图”,而是围绕具体问题设计分析。
常见分析模块有四类:
- 差异分析
- 功能聚类分析
- 分子互作分析
- 临床意义分析
这四类模块足以支撑一篇规范的生信文章框架。对于初学者,最重要的是先把数据拿对,再把分析链条理顺。
2. 掌握3种TCGA检索方式
2.1 Project模块:先定位项目
TCGA数据库实操的第一步,通常是进入Project模块。这里可以按项目、疾病类型、数据分类和实验策略筛选数据。
新版TCGA/ GDC平台覆盖范围更广,包含67个肿瘤部位、20个项目,数据类型也更完整,包括RNA测序、DNA甲基化、蛋白组测序和临床数据等。
实际操作中,如果你要找结肠癌RNA数据,可以按以下思路筛选:
- 选择项目TCGA
- 选择原发部位结肠
- 选择实验策略RNA测序
- 再进入repository下载
Project模块适合“从疾病出发”的检索。
2.2 Exploration模块:从样本、基因和临床切入
Exploration模块更适合细化检索,常见入口有四种:
- cases
- genes
- clinical
- mutations
如果你要查某个基因,比如TP53的突变情况,可以直接走genes或mutations入口。若要看临床资料,比如年龄、分期、治疗情况、暴露因素,则选clinical入口。
在实际中,cases检索样本数可能较少。此时可增加project和sample type来提高命中率。这一步的核心是从“泛检索”变成“精筛选”。
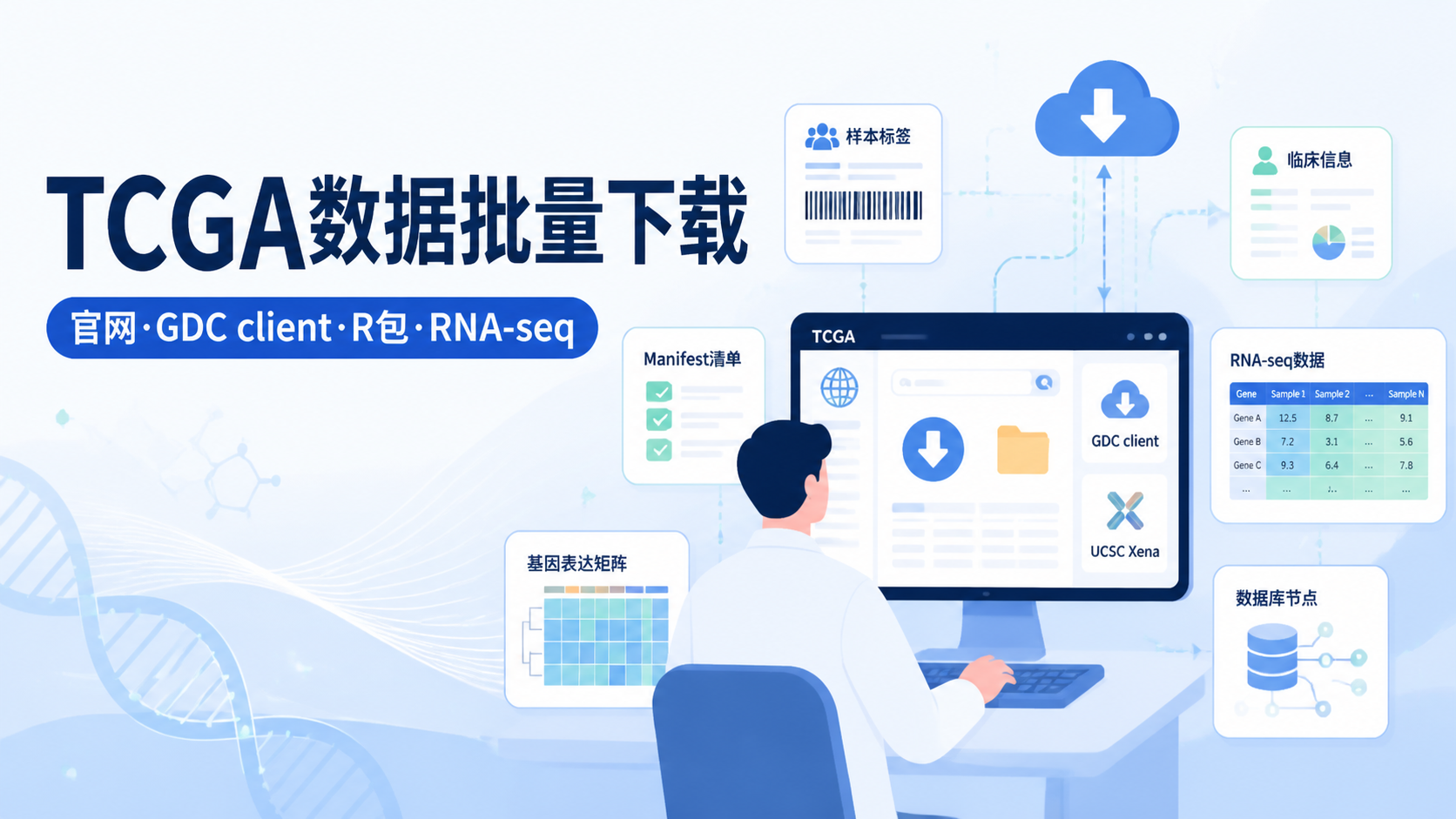
2.3 Repository模块:真正下载数据的地方
很多人第一次做TCGA数据库实操时,会把“检索”和“下载”混淆。实际上,Repository模块才是获取原始文件的重要入口。它按files和cases分类,适合明确文件级下载需求。
以TCGA肝癌为例,检索时可设置:
- program为TCGA
- project为TCGA-LIHC
- experimental strategy为某类实验
- access为open
然后进入文件页面下载。如果你要的是标准化文件、临床补充信息或特定表达矩阵,Repository往往更直接。
3. 3种数据下载方法,按场景选择
3.1 官网直下,适合小数据量
最直接的方法是通过官网或GDC Portal下载。适用于数据量小、网络稳定、文件少的情况。
但如果样本多,文件体积大,直接浏览器下载效率很低,容易中断。此时不建议硬扛。TCGA数据库实操的关键不是“能不能下”,而是“如何稳定地下”。
3.2 GDC Client,适合正式批量下载
对于大样本数据,GDC Client更适合。它能和购物车式下载流程配合使用,适合临床数据和测序数据的批量获取。
基本流程是:
- 在GDC Portal中完成检索
- 将目标文件加入cart
- 下载manifest文件
- 用GDC Client批量下载
这套流程更适合科研场景。因为它可重复、可追踪,也更符合数据管理要求。
如果你准备做正式课题,建议把GDC Client作为标准工具。
3.3 替代网站和R包,适合提高效率
课程中还提到两类替代方案。第一类是UCSC Xena,第二类是Firehose。它们都可作为TCGA数据的替代下载通道。
UCSC Xena支持按队列浏览。比如肝癌数据里可下载RNA、DNA甲基化、临床、SNP、CNV和MicroRNA数据。RNA测序数据还可区分Counts、FPKM和FPKM UQ。对于需要快速验证思路的人,这种方式很方便。
Firehose则可覆盖33种癌症数据。对于需要快速获取标准化表达矩阵的研究者,这是常见补充渠道。
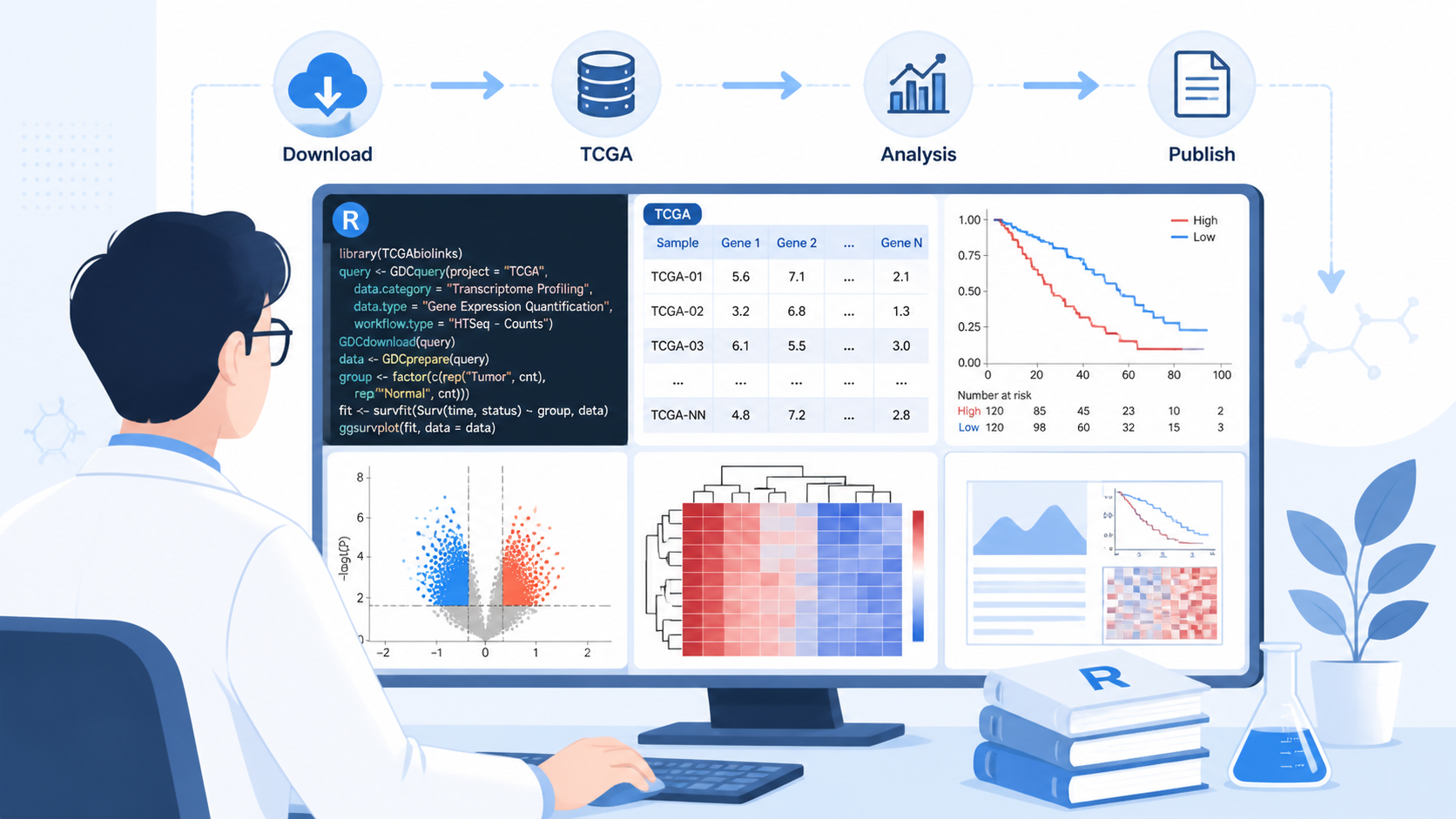
另外,R语言中的TCGAbiolinks包也可直接完成查询和下载。常用流程包括:
- GDCquery查询数据
- GDCdownload下载数据
- 读取并整理metadata
- 按样本类型提取表达矩阵
对熟悉R的人来说,TCGAbiolinks能显著提升TCGA数据库实操效率。
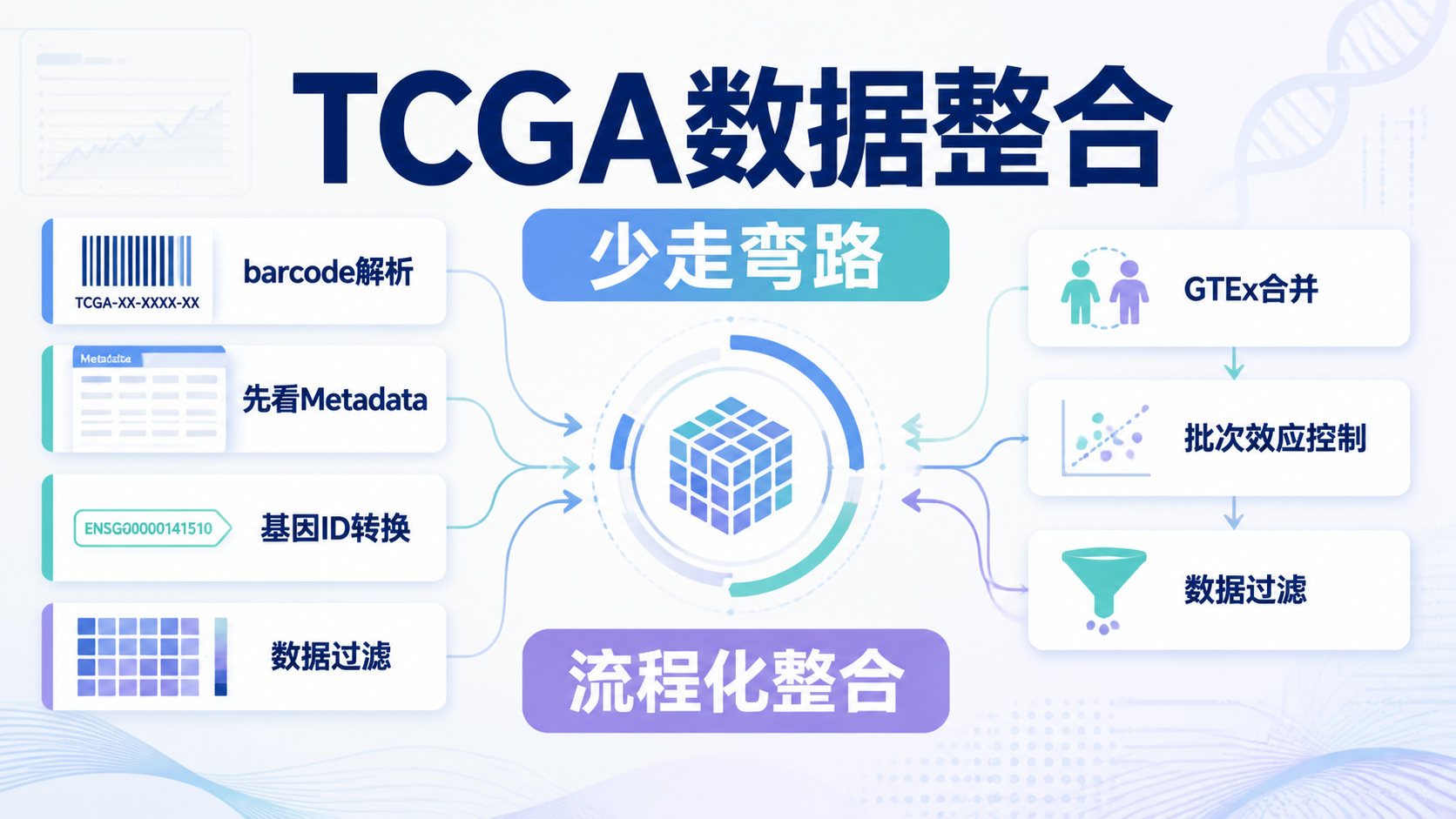
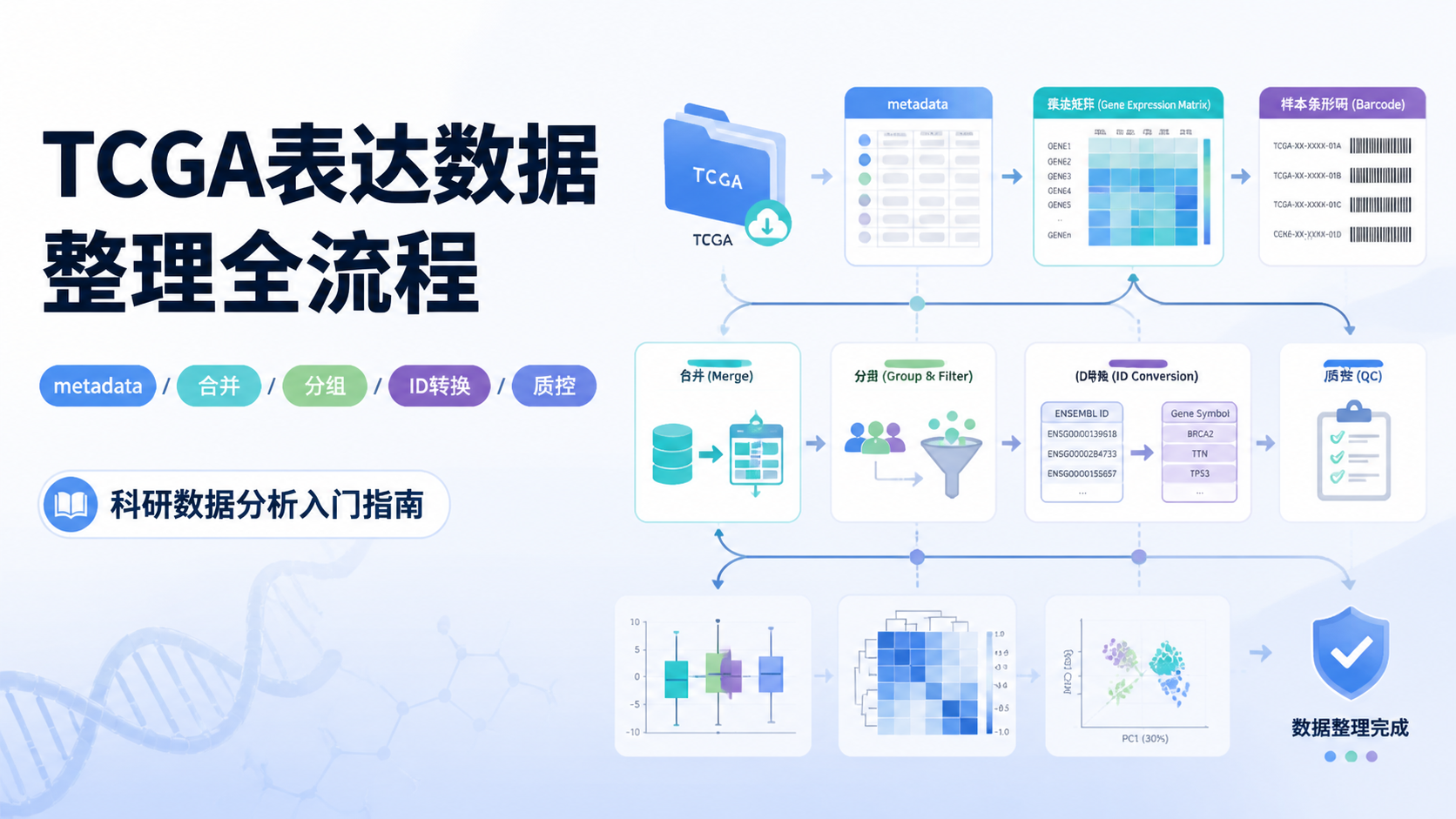
4. 数据分析前,先完成清洗与分层
4.1 数据清洗是第一道门槛
课程中明确提到,数据清洗就是把杂乱数据整理成整洁数据。这个步骤看似基础,但决定后续分析是否可靠。
常见问题包括:
- 样本信息不完整
- 表达矩阵格式不统一
- 临床变量命名混乱
- 重复样本或异常值干扰分析
如果清洗没做好,后面的差异分析、富集分析和生存分析都会受影响。
4.2 差异分析的标准流程
TCGA数据库实操里,差异分析通常使用R包完成,例如DESeq2、edgeR、limma。结果一般通过火山图和热图展示。
一个规范的流程通常是:
- 获取原始表达数据
- 进行样本分组
- 完成标准化和过滤
- 做差异分析
- 输出火山图、热图
对于RNA-seq数据,差异分析是最常见的起点。它不仅能筛出候选基因,还能为后续GO、KEGG、GSEA提供输入。
4.3 功能、互作和临床分析要联动
差异基因筛出来后,还要继续做功能聚类,比如GO、KEGG、GSEA。这样才能把“基因列表”转成“生物学解释”。
随后可进入分子互作分析。常用工具是Cytoscape,用于展示基因、RNA或蛋白之间的关系网络。
最后是临床意义分析。常见展示包括:
- 基线资料表
- 单因素分析表
- 多因素分析表
- 生存曲线图
- ROC曲线
TCGA数据库实操的价值,不在于拿到一张图,而在于把图串成完整证据链。
5. 把TCGA实操做成可发表的研究
5.1 先定问题,再选数据
课程反复强调,研究必须从问题出发。比如某个基因在肿瘤中是否下调,是否和预后相关,是否影响免疫浸润。这些问题都可以通过TCGA展开。
一个典型例子是肝细胞癌研究。先看目标基因在肿瘤与正常组织中的表达,再做生存分析,然后结合甲基化、免疫浸润或ceRNA网络补充机制。
这种“表达-机制-临床”的链条,是TCGA文章中最常见的组织方式。
5.2 结果图要有逻辑,不要堆图
在生信文章中,图不是越多越好。更重要的是顺序合理。通常可按以下顺序组织:
- 差异表达图
- 富集分析图
- 互作网络图
- 临床生存图
- 机制补充图
这样读者更容易理解你的研究主线。审稿人也更容易看出你是否真正掌握了数据。
5.3 用工具提高效率,而不是重复造轮子
很多科研人员卡在TCGA数据库实操,不是因为不会分析,而是因为重复做基础流程太耗时。下载、整理、匹配临床信息、提取表达矩阵,这些环节最消耗精力。
这也是为什么越来越多研究者会选择标准化工具和课程支持。像解螺旋这类品牌,提供的价值就在于把复杂流程标准化,把可复用步骤整理出来,帮助你更快完成数据检索、下载和分析前处理。对于要赶课题、论文或毕业的研究者,这种效率提升很关键。
总结Conclusion
TCGA数据库实操的核心,可以概括为三点:先明确研究问题,再选对检索模块,最后用合适工具完成下载和清洗。只要这三步打通,后面的差异分析、富集分析和临床分析就会顺畅很多。
对于医学生、医生和科研人员来说,真正难的不是“有没有TCGA数据”,而是“能不能把数据变成可发表的结论”。 如果你希望更快掌握规范流程,可以借助解螺旋的标准化课程与分析支持,把TCGA数据库实操变成可复用的研究能力。
- 引言Introduction
- 1. 先搞清TCGA数据库能做什么
- 2. 掌握3种TCGA检索方式
- 3. 3种数据下载方法,按场景选择
- 4. 数据分析前,先完成清洗与分层
- 5. 把TCGA实操做成可发表的研究
- 总结Conclusion