引言Introduction
TCGA数据量大、文件多、样本注释复杂,很多人卡在第一步:不会把原始文件整理成可分析矩阵 。如果你正在做差异分析、分组比较或表达矩阵整理,掌握tcga数据导入分析 的标准流程,就能少走很多弯路。
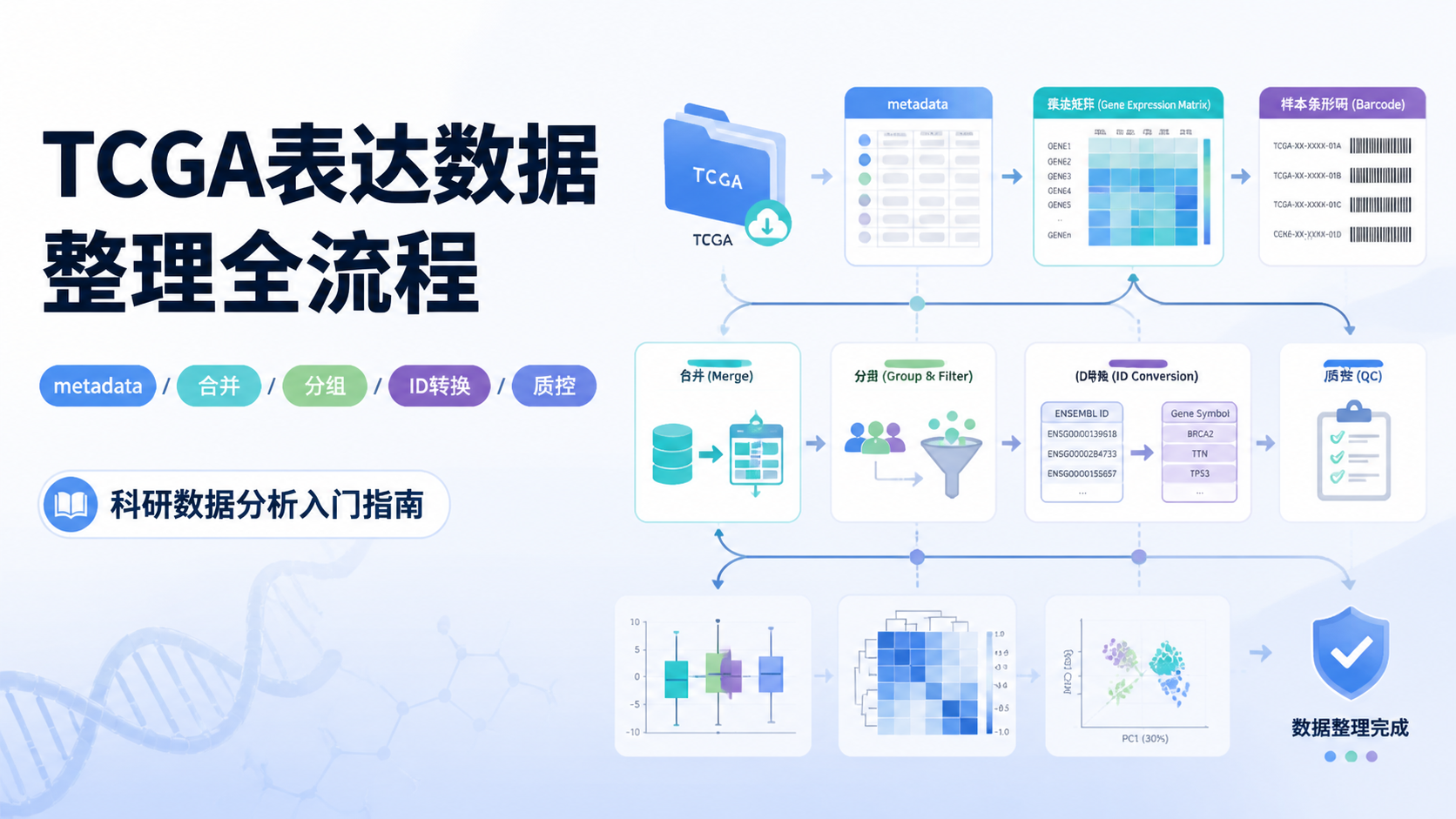
1. 先把TCGA元数据读对
1.1 为什么metadata是第一步
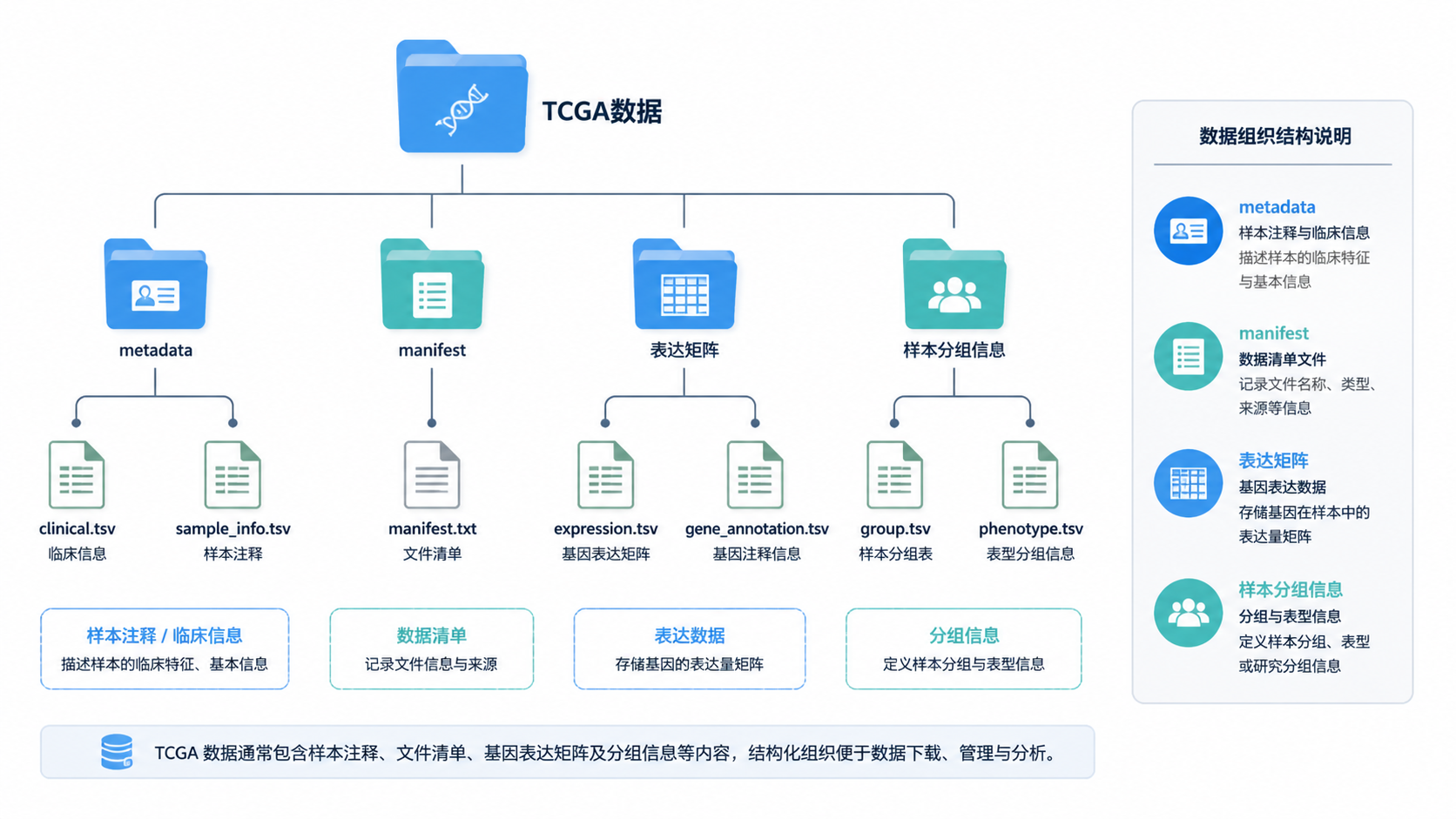
做tcga数据导入分析 ,不是先读表达矩阵,而是先读metadata。原因很简单。TCGA下载后的文件名、样本ID、MD5值、样本类型,都在metadata里。没有这一步,后面很难确认每个文件对应哪个样本。
metadata的核心作用有3个。
- 建立文件名与TCGA ID的对应关系。
- 提取患者ID、样本类型和分组信息。
- 为后续质控、合并和过滤提供依据。
1.2 barcode结构要看懂
TCGA barcode前16位通常足够用于样本整理。前12位是患者ID,第13到15位是样本类型信息。常见规则里,01通常代表原发肿瘤,11通常代表正常组织 。
这一步非常关键,因为差异分析前必须先区分 tumor 和 normal。
在实际tcga数据导入分析 中,建议先完成这几个字段整理:
- 文件名
- MD5值
- TCGA ID
- 患者ID
- 样本类型
- 分组标签
1.3 先确认文件完整性
下载完数据后,不要直接分析。先核对MD5值。
如果MD5不一致,说明文件可能损坏或下载不完整。 这会直接影响后续矩阵合并和结果可靠性。对于大规模TCGA数据,这是最基本的质控。
2. 批量读取表达文件并合并
2.1 单文件结构先看清
TCGA表达文件常见为TSV格式。每个文件通常包含两列,一列是基因ID,一列是count或FPKM数值。很多文件末尾还会带有统计行,这些行一般不参与下游分析,需要去掉。
在tcga数据导入分析 中,建议先抽查1个文件,确认:
- 列数是否符合预期
- 是否包含gene ID
- 是否存在末尾冗余行
- 数据类型是count还是FPKM
2.2 批量合并的标准思路
当样本数达到几十、几百时,不能手工合并。标准做法是批量读取每个文件,再按基因ID合并成一个大矩阵。
核心逻辑是:
- 读取文件列表。
- 批量导入每个样本文件。
- 用基因ID进行纵向对齐。
- 合并成表达矩阵。
这个过程的目标很明确:把“每个样本一个文件”变成“一个基因×样本矩阵”。
2.3 合并后还要做一次检查
合并完成后,马上检查3件事:
- 行数是否为基因数
- 列数是否与样本数一致
- 样本名是否与metadata匹配
如果样本名和metadata对不上,后面分组和差异分析都会出错。
在这一阶段,tcga数据导入分析的重点不是快,而是准。
3. 根据样本注释做分组与过滤
3.1 分组信息不能只看名字
很多人以为只要看到肿瘤样本和正常样本就行,其实不够。TCGA里还包含不同来源、不同组织类型、不同样本质量。
因此,在tcga数据导入分析 中,建议结合annotation信息一起判断,而不是只凭文件名。
常见处理包括:
- 肿瘤与正常分组
- 原发灶与转移灶区分
- 不适合做log分析的样本过滤
- 低质量样本剔除
3.2 为什么要过滤不合适样本
有些样本在统计建模前必须排除。比如:
- 样本类型不符合研究目的
- 注释信息不完整
- 不适合后续对数转换分析
- 与目标癌种不一致的条目
过滤不是删数据,而是提升分析可信度。
这一步做好了,差异表达结果会更稳定。
3.3 统一分组标签很重要
建议把样本标签统一成简洁格式,比如:
- tumor
- normal
- group1
- group2
这样在DESeq2、limma、ggplot2等下游工具中更容易调用。
如果分组标签混乱,后面画图和建模都容易出问题。
4. 完成ID转换和表达矩阵整理
4.1 ID转换是常见痛点
TCGA表达文件里常出现Ensembl ID、转录本ID或版本号。下游分析常常需要基因符号,因此要做ID转换。
在tcga数据导入分析 里,这一步看似简单,实际最容易出错。
常见问题有:
- 一个ID对应多个基因名
- 不同版本注释不一致
- 部分ID无法映射
- 重复基因名需要去重
4.2 转换后要做去重
ID转换后,往往会出现一个基因名对应多个条目。此时不能直接保留全部重复项。
通常要先明确规则,例如:
- 取平均值
- 保留表达量最高的一条
- 只保留唯一映射项
规则要在分析前固定下来,不能中途变更。 否则结果可重复性会下降。
4.3 还要整理成标准分析格式
整理完成后,最好输出成标准表达矩阵。一般要求:
- 行是基因
- 列是样本
- 第一列为基因名或基因ID
- 第一行是样本名
这是后续差异分析、聚类、热图和机器学习建模的基础格式。
一旦格式规范,后续所有分析都会更顺。
5. 进入下游分析前的最后检查
5.1 先看数据分布
正式做差异分析前,建议先看表达分布。常见检查包括:
- 样本间表达量分布
- 是否存在极端离群样本
- 是否需要log转换
- 是否存在批次效应
这一步能提前发现很多问题,避免直接跑模型后发现结果异常。
5.2 过滤低表达基因
RNA-seq差异分析前,通常要过滤低表达基因。可选标准包括:
- 去除全为0的基因
- 保留至少一半样本中表达量大于0的基因
- 保留中位数大于0的基因
过滤规则没有唯一答案,但必须与研究目的匹配。
如果过滤过松,噪音大。过滤过严,可能丢失有意义信号。
5.3 用规范流程提高可重复性
完整的tcga数据导入分析 ,本质上是一个标准化流程。它不是单纯读取文件,而是把下载、核验、合并、注释、过滤、转换串成闭环。
流程越规范,后续差异分析越稳,结果越容易复现。
总结Conclusion
TCGA数据并不难,难的是前处理是否规范。一个可靠的tcga数据导入分析 流程,通常包括5步:读metadata、批量合并文件、提取分组信息、完成ID转换、做最后过滤与检查。只要这5步走稳,后面的差异分析、富集分析和生存分析都会顺很多。
如果你希望把TCGA整理流程做得更快、更稳、更适合科研发表,解螺旋的课程和工具可以直接帮助你把数据导入、清洗和标准化分析串起来。
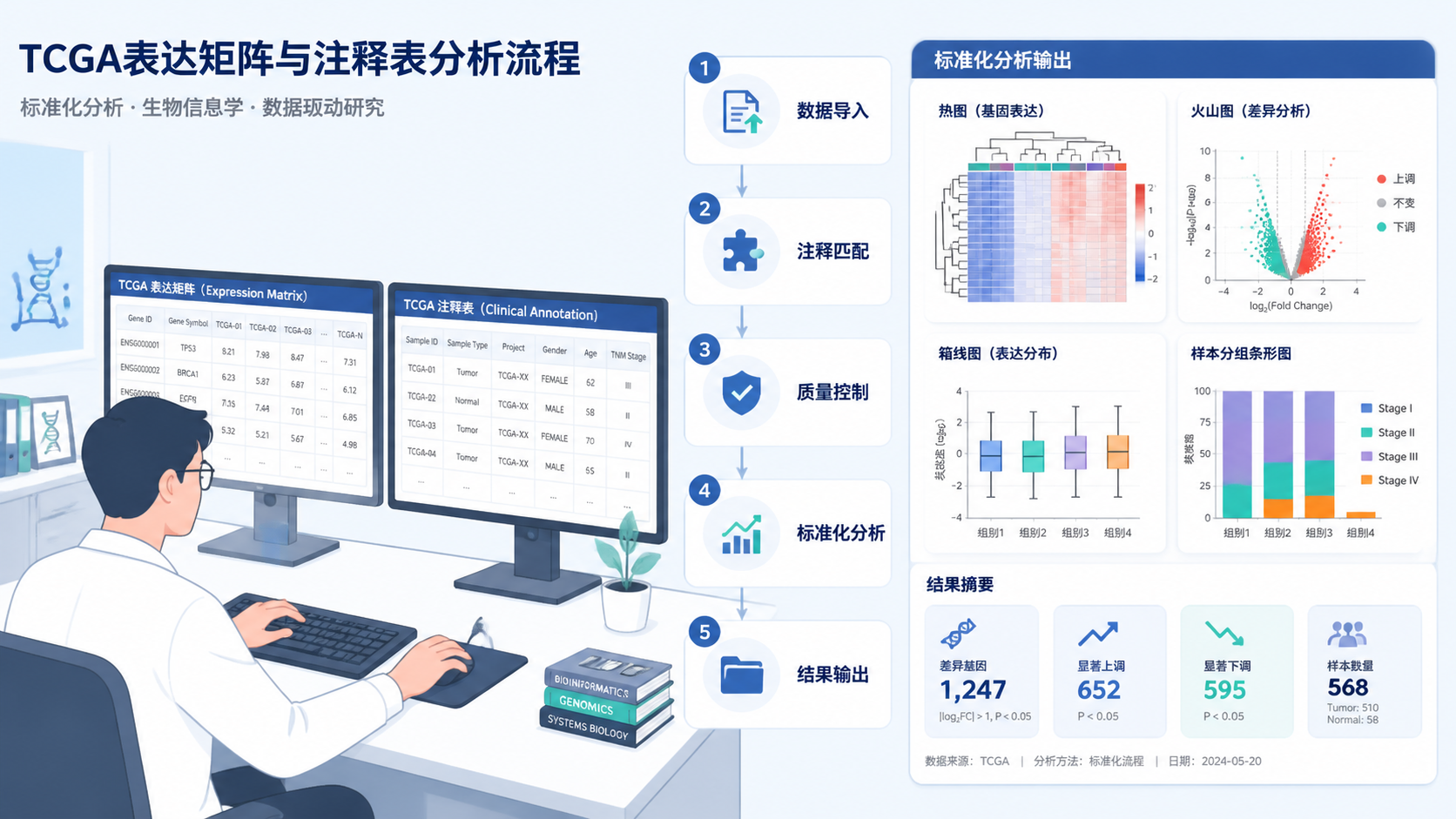
- 引言Introduction
- 1. 先把TCGA元数据读对
- 2. 批量读取表达文件并合并
- 3. 根据样本注释做分组与过滤
- 4. 完成ID转换和表达矩阵整理
- 5. 进入下游分析前的最后检查
- 总结Conclusion