





引言Introduction
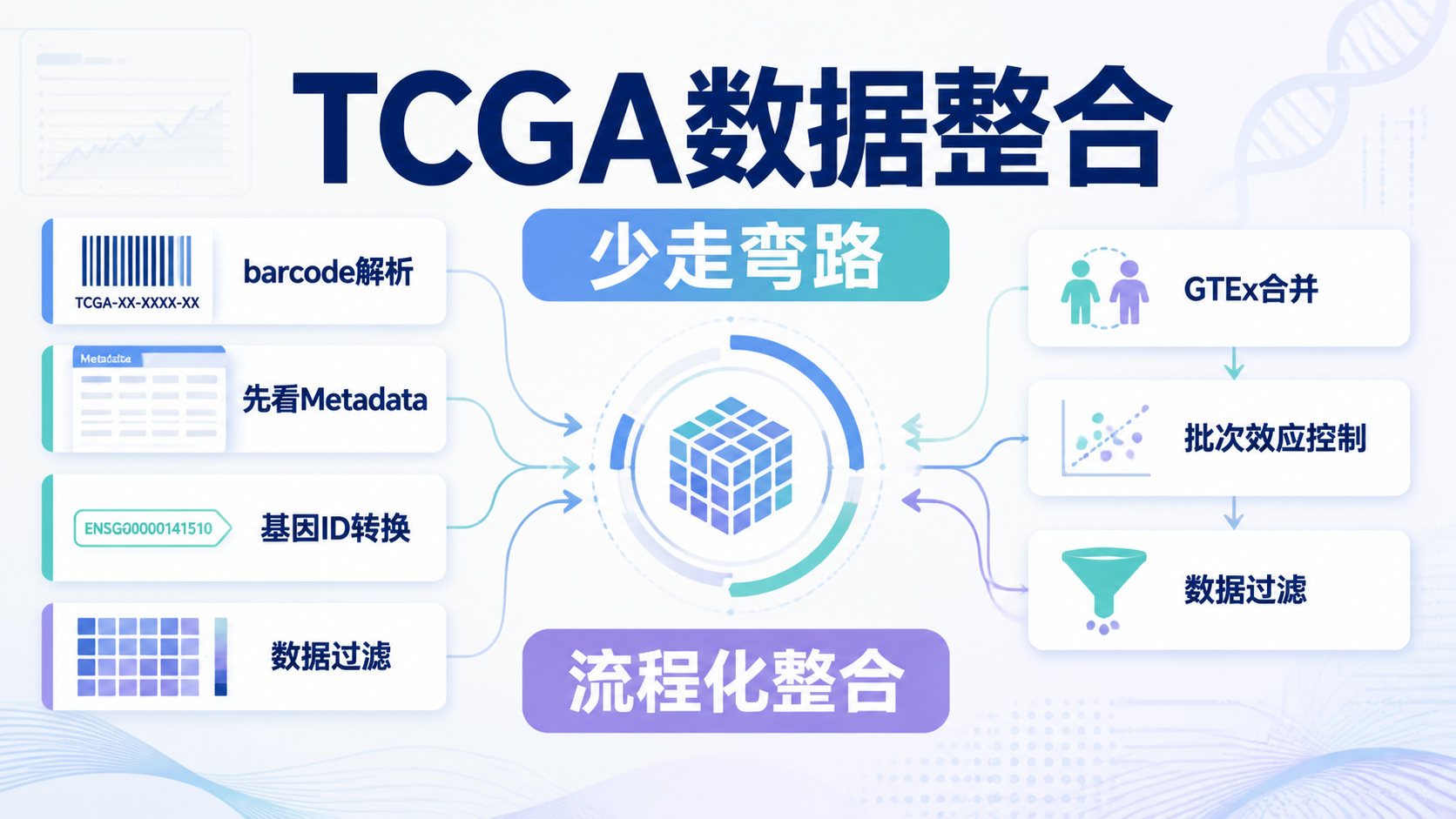
TCGA数据整合看似只是下载和合并,真正做起来却常被样本注释、barcode解析、批次效应和ID转换卡住。如果前处理做错,后面的差异分析、生存分析和模型构建都会偏。 本文结合TCGA官方数据结构,梳理5个最容易踩坑的难点,帮助你把分析起点做对。
1.TCGA数据整合为什么先看Metadata
1.1 Metadata不是附属文件,而是样本钥匙
TCGA的metadata,本质上是“描述数据的数据”。它记录了样本名、样本ID、组织类型、文件名对应关系等关键信息。没有metadata,原始文件就很难准确映射到具体样本。
在实际项目里,先下载JSON格式的metadata,再用R中的jsonlite读取,是更稳妥的做法。随后再结合manifest文件,整理样本与文件名的对应关系。这样可以减少手工匹配错误。
1.2 只看表达矩阵,常会漏掉样本身份
很多初学者直接拿表达矩阵进入分析,忽略了样本注释。结果是肿瘤、正常、转移样本混在一起。这会直接影响TCGA数据整合的可信度。
建议先确认以下信息:
- 样本ID是否唯一
- 文件名和sample ID是否一一对应
- 组织类型是否明确
- 是否存在重复下载或重复测序样本
2.TCGA barcode解析是整合核心
2.1 barcode里藏着样本来源和类型
TCGA barcode是样本识别的核心。它包含项目来源、TSS编码、患者编码、样本类型、分析类型、板号和中心代码等信息。对于RNA-seq和DNA数据,barcode还能帮助区分不同组学来源。
其中最常用的是样本类型位点。第14、15位字符常用于判断原发肿瘤和正常组织。 例如,01通常代表原发肿瘤,11通常代表正常组织。
2.2 解析不准,样本分组就会错
TCGA数据整合时,最常见的错误之一就是把样本类型分错。尤其在肝癌、结肠癌这类“肿瘤与癌旁组织”分析中,分组错误会直接改变差异基因结果。
此外,analyte也不能忽视。D代表DNA,R代表RNA。plate和center code则常用于追踪批次来源。如果同一项目不同板号、不同中心混用,就要提高对批次效应的警惕。
3.TCGA和GTEx整合不是简单拼接
3.1 合并的目标是补足对照,而不是制造偏差
在很多癌种中,TCGA的癌旁正常样本数量不足。此时会考虑引入GTEx正常组织。这个思路本身合理,但前提是处理方式统一。TCGA数据整合如果直接拼接原始结果,批次效应通常会非常明显。
更推荐的做法是使用统一重新分析处理后的数据源,并先提取对应组织类型,再做后续整合。比如肝癌项目中,先筛选LIHC样本,再匹配GTEx中的肝脏样本,逻辑会更清晰。
3.2 批次效应必须显式处理
TCGA与GTEx来自不同项目、平台和处理流程,批次效应几乎不可避免。常见处理方法包括RUVSeq、SVA等R包。它们的核心作用,是尽量把“技术差异”从“生物差异”中分离出来。
可操作的检查步骤包括:
- 合并前先看样本来源是否一致
- 合并后做PCA或聚类图
- 观察样本是否按平台而非生物分组
- 必要时再做批次校正
没有批次检查的TCGA数据整合,往往只是表面合并。
4.基因ID转换和版本差异不能忽略
4.1 不同参考基因组版本会影响映射
TCGA早期数据与新版GDC数据,在参考基因组和注释版本上可能存在差异。常见情况包括GRCh37与GRCh38、旧版注释与新版GTF/GFF文件不一致。看似只是版本差别,实际会影响基因坐标和注释结果。
不过从课程知识库看,新版TCGA数据通常已经完成基因注释,很多场景下不再需要额外做复杂的ID转换。 但如果你要整合历史数据、外部队列或GTEx,仍要确认版本一致性。
4.2 ID转换要先定标准,再做合并
建议在TCGA数据整合前先统一以下内容:
- 基因ID使用Ensembl还是Symbol
- 是否去掉版本号后缀
- 是否保留低表达转录本
- 外部数据与TCGA是否来自同一注释版本
一旦标准不统一,后续做交集基因、富集分析或模型构建时,就容易出现“同名不同ID”或“同ID不同注释”的问题。
5.数据过滤决定下游结果质量
5.1 样本过滤比想象中更重要
TCGA样本中,临床注释并不总是完整。需要先核查病例信息,尤其是组织学类型、病理分期和样本质量。比如胆管癌与肝癌、原发灶与转移灶,在数据库里可能会混入相近标签,必须谨慎排查。
对于临床分期,课程知识库强调应优先关注pathological stage,而不是只看clinical stage。这对预后分析尤其重要。
5.2 基因过滤要服务于分析目的
RNA-seq差异分析前,基因过滤能减少噪音。常见标准包括:
- 去除表达量为0的基因
- 保留至少一半样本中表达量大于0的基因
- 保留中位数大于0的基因
这类规则没有绝对统一答案,关键是与研究目的匹配。过滤过松,会增加多重检验负担。过滤过严,又可能丢掉低表达但有生物学意义的基因。
6.把TCGA数据整合做对,关键是流程化
6.1 真正稳妥的整合流程
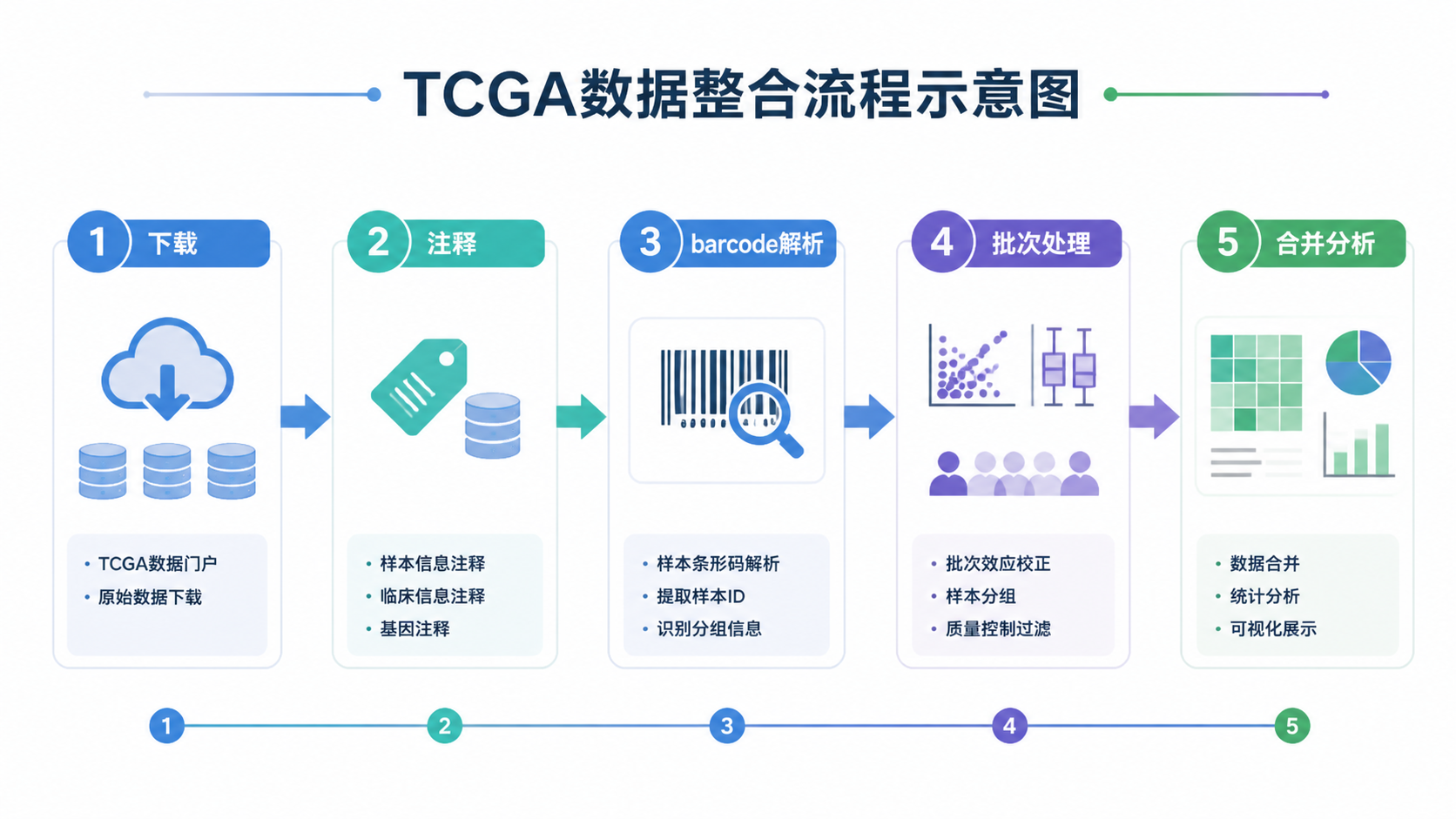
结合上述难点,比较稳妥的流程是:
- 先下载metadata和manifest
- 再解析barcode和样本类型
- 核对临床与组织学信息
- 统一基因注释版本
- 做批次评估和校正
- 最后再进入差异分析和生存分析
这个顺序的价值在于,把错误尽量拦在前处理阶段。 这比后期补救更高效,也更符合可复现研究的要求。
6.2 解螺旋如何帮助你少走弯路
如果你在TCGA数据整合中反复遇到样本匹配、barcode解析、批次效应和过滤标准不统一的问题,说明流程已经到了需要系统化整理的阶段。解螺旋相关课程把TCGA下载、注释提取、合并策略和清洗步骤拆得很细,适合医学生、医生和科研人员直接按步骤复现。用标准化流程替代零散试错,能显著提升分析效率和结果可靠性。
总结Conclusion
TCGA数据整合不是简单的“把数据放到一起”。真正的难点在于metadata、barcode、批次效应、版本差异和过滤标准。只要前处理不严谨,后续的差异分析和模型构建都会受到影响。
把样本身份、注释规则和批次控制做扎实,才是TCGA数据整合成功的前提。 如果你希望把这些步骤系统学会,可以进一步了解解螺旋的TCGA数据分析课程,用更规范的流程提升科研产出。
- 引言Introduction
- 1.TCGA数据整合为什么先看Metadata
- 2.TCGA barcode解析是整合核心
- 3.TCGA和GTEx整合不是简单拼接
- 4.基因ID转换和版本差异不能忽略
- 5.数据过滤决定下游结果质量
- 6.把TCGA数据整合做对,关键是流程化
- 总结Conclusion



