引言Introduction
TCGA突变数据下载看起来复杂,其实流程很固定。真正的难点不在“有没有数据”,而在“从哪里找、怎么筛、怎么下、下完怎么用”。如果你是医学生、医生或科研人员,先把入口和下载路径理清,后面分析会快很多。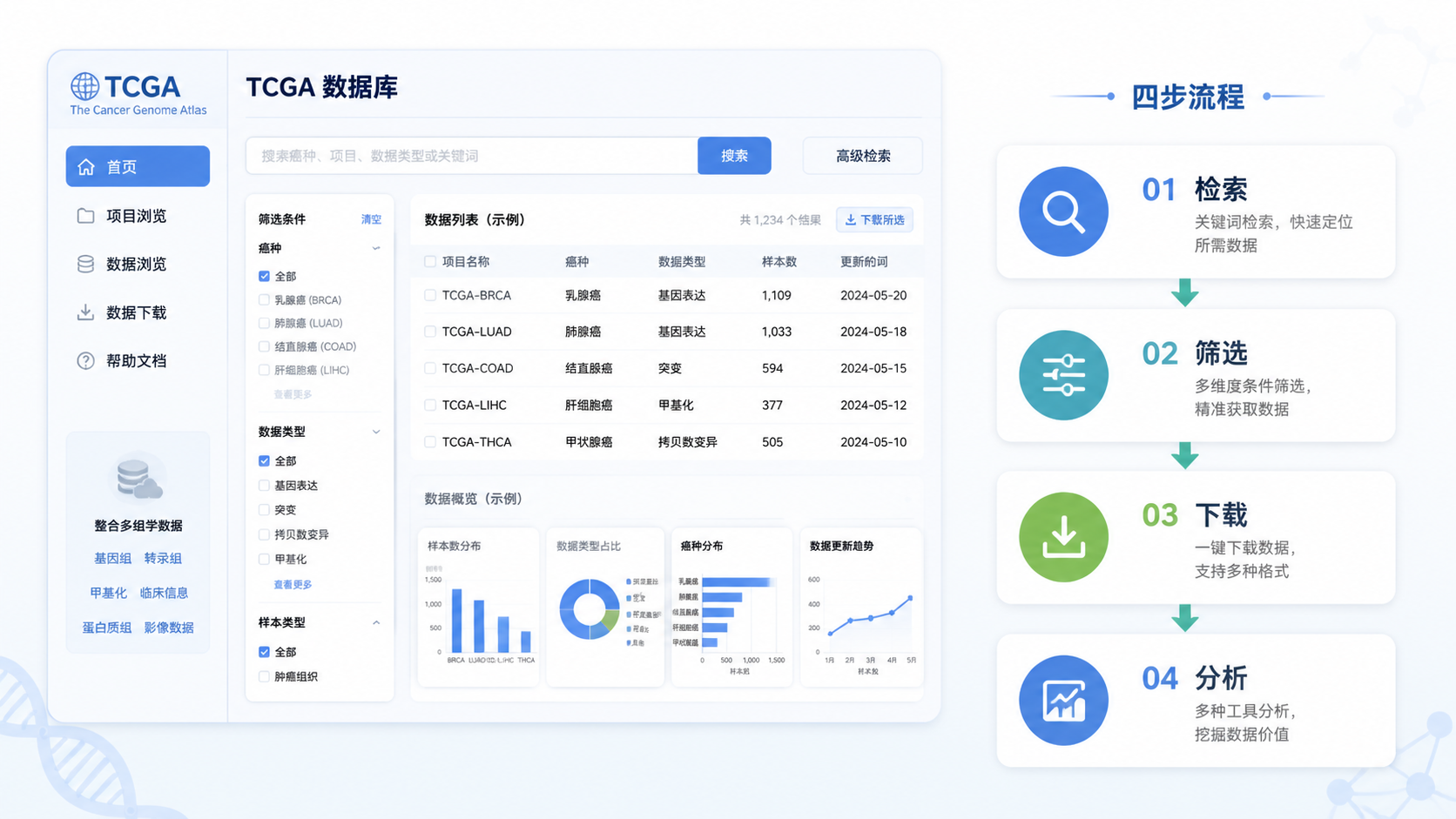
1.TCGA突变数据到底是什么
1.1 先搞清楚你要找的不是“神秘文件”
TCGA提供的是大规模癌症队列数据。和突变相关的内容,通常包括突变注释、突变位点、突变类型,以及对应样本信息。
在TCGA里,突变数据不只是“基因有没有突变”这么简单。 你还可以继续看突变后果、预测结果,甚至和临床生存信息联动分析。
TCGA目前覆盖多个肿瘤项目,数据类型也很丰富。和突变研究常配套的,还有临床数据、RNA测序、DNA甲基化、蛋白组等。这样才能做更完整的肿瘤分层和关联分析。
1.2 突变数据常用在哪些分析里
对科研人员来说,突变数据最常见的用途有三类。
- 看某个基因在肿瘤中的突变频率。
- 分析突变与生存期的关系。
- 联合临床分期、分型、种族等变量做分层比较。
如果只下载不分析,数据只是占硬盘。 如果能把突变和临床放在一起看,才更接近真正的转化研究。
2.TCGA突变数据下载的三个入口
2.1 入口一,官网检索后直接下载
TCGA官方数据库主要有三种检索方式,分别是project、exploration和repository。对突变数据来说,最实用的通常是repository模块。
在repository里,你可以按以下维度筛选:
- data category
- experimental strategy
- access
- project
- disease type
- primary site
repository模块的优势是选项最全。 而且检索到的数据最终也都从这里进入下载流程。
2.2 入口二,用GDC client批量下载
如果样本量少,网页直接下载就够了。
如果样本量大,官方更推荐用GDC client。
流程很像“先在超市挑好商品,再用购物车统一结账”。你先把文件加到cart,再用manifest文件配合GDC client批量拉取。
常见步骤是:
- 在repository中筛选目标项目和数据。
- 点击add all files to cart。
- 下载manifest文件。
- 使用GDC client根据manifest批量下载。
这套方法适合大多数正式课题。 尤其适合要下载多个样本、多个文件的场景。
2.3 入口三,R包和替代网站
如果你更习惯代码操作,也可以用R包下载。
课程中提到较常用的是TCGAbiolinks包。
另外,还有替代网站可用,比如UCSC Xena和Firehose。它们适合快速拿到已整理过的数据。
但要注意,不同平台的数据格式和预处理流程可能不同,分析前要先确认一致性。
3.怎么在TCGA里找到突变数据
3.1 用exploration检索突变相关内容
exploration模块支持按cases、genes、clinical、mutations四种方式检索。
其中和突变最直接相关的是mutations和genes。
在mutations中,你可以看到多个突变注释维度,比如:
- VEP预测模型
- SIFT预测模型
- PolyPhen预测模型
- 突变后果
- 突变类型
- 突变方法
- COSMIC ID
- dbSNP ID
这意味着TCGA突变数据下载后,不只是“拿到一串位点”。 你还能继续筛选功能影响和注释信息。
3.2 用genes查看某个基因的突变情况
如果你想看某个基因,比如TP53在某癌种中的突变情况,可以在genes里检索。
系统会列出相关基因,点击后还能进一步查看突变与生存曲线的关联。
这一步很适合做课题选题。
先看热点基因,再决定是否深入做机制或预后分析。
3.3 clinical信息别忽略
突变研究最怕“只看基因,不看人”。
clinical里能查到的人口学和临床信息很多,包括:
- 性别、年龄、种族
- 分期、病理分期
- 淋巴结转移
- 治疗情况
- 吸烟、饮酒等暴露因素
真正有价值的分析,往往是突变和临床一起做。 比如按分期、种族、治疗方案分层,结果会更可信。
4.TCGA突变数据下载的实操流程
4.1 先筛选,再下手,别一上来就狂点下载
以常见的TCGA项目为例,先确定:
- 肿瘤项目。
- 原发部位。
- 数据类型。
- 实验策略。
- 是否开放访问。
如果你做的是肝癌相关研究,也可以先定位到TCGA LIHC,再继续挑选需要的文件。
这一步的核心不是“下载越多越好”,而是“下载得刚刚好”。
不然你会得到一堆文件,然后开始怀疑人生。
4.2 下载前先确认数据格式
下载前要先确认你拿到的是什么:
- 原始突变文件。
- 注释后的突变信息。
- 临床补充文件。
- 样本分组文件。
不同格式对应不同用途。
做下游统计前,必须先整理样本ID和临床表型。否则文件名看起来都像“亲戚”,实际对不上号。
4.3 如果用GDC client,记得先配环境
GDC client下载前,需要先完成环境变量设置。
设置成功后,可以在命令行输入 GDC-client -h 检查是否正常运行。
之后再切换到manifest文件所在目录,使用下载命令批量拉取数据。
对于大样本下载,这是最稳妥的方式。
尤其适合学生党一次性搞定,不用反复手动点网页。
5.下载后怎么处理才不翻车
5.1 先整理样本,再谈分析
TCGA数据下载完后,第一件事不是画图,而是整理。
建议按这个顺序做:
- 检查样本ID是否一致。
- 匹配临床表和突变表。
- 去除重复或缺失严重样本。
- 确认分析队列是否统一。
- 再进入统计分析。
样本对不上,后面的结果就像把病历和化验单拿错了。
图可以画得很漂亮,结论却可能站不住。
5.2 突变分析常见坑
常见问题主要有三个。
- 同一个基因有多个注释版本。
- 不同平台的数据格式不一致。
- 临床信息和突变数据样本数不完全相同。
所以,下载只是第一步。真正的工作在于整理、筛选和验证。
这也是为什么很多人“会下载,不会分析”。
6.为什么很多人最后还是会选择更省事的工具
6.1 手工下载能学流程,工具能提效率
如果你是入门阶段,手动走一遍TCGA突变数据下载流程很有必要。
这样你会知道project、repository、cart、manifest分别干什么。
但到了正式课题阶段,效率就更重要了。
这时候,成熟工具和品牌服务的价值就出来了。
6.2 解螺旋可以帮你少走弯路
如果你想更快完成TCGA突变数据下载、整理和后续分析,解螺旋的产品和资源能帮你把流程理顺。
从检索思路到数据整理,再到分析衔接,能明显减少重复劳动。
对科研人员来说,省下来的不是几分钟,而是整晚。
对临床研究者来说,少踩一个坑,就少返工一次。
总结Conclusion
TCGA突变数据下载并不玄学。核心就是先检索,再筛选,再下载,最后整理。你只要记住三件事,就能把流程跑通。第一,优先用repository定位文件。第二,大样本下载用GDC client更稳。第三,下载后一定要把突变和临床信息匹配好。
真正决定效率的,不是你点了多少次下载,而是你是否建立了清晰的数据流程。
如果你希望少折腾、快上手,可以结合解螺旋的工具和方法,把TCGA突变数据下载与后续分析串起来,直接进入更有价值的科研阶段。
- 引言Introduction
- 1.TCGA突变数据到底是什么
- 2.TCGA突变数据下载的三个入口
- 3.怎么在TCGA里找到突变数据
- 4.TCGA突变数据下载的实操流程
- 5.下载后怎么处理才不翻车
- 6.为什么很多人最后还是会选择更省事的工具
- 总结Conclusion