引言Introduction
TCGA表达数据处理不是简单下载count矩阵。样本ID、barcode、metadata、批次效应、ID转换、过滤标准,任何一步出错都会影响差异分析和后续结论。对医学生、医生和科研人员来说,真正的难点不是“有没有数据”,而是“数据能不能用”。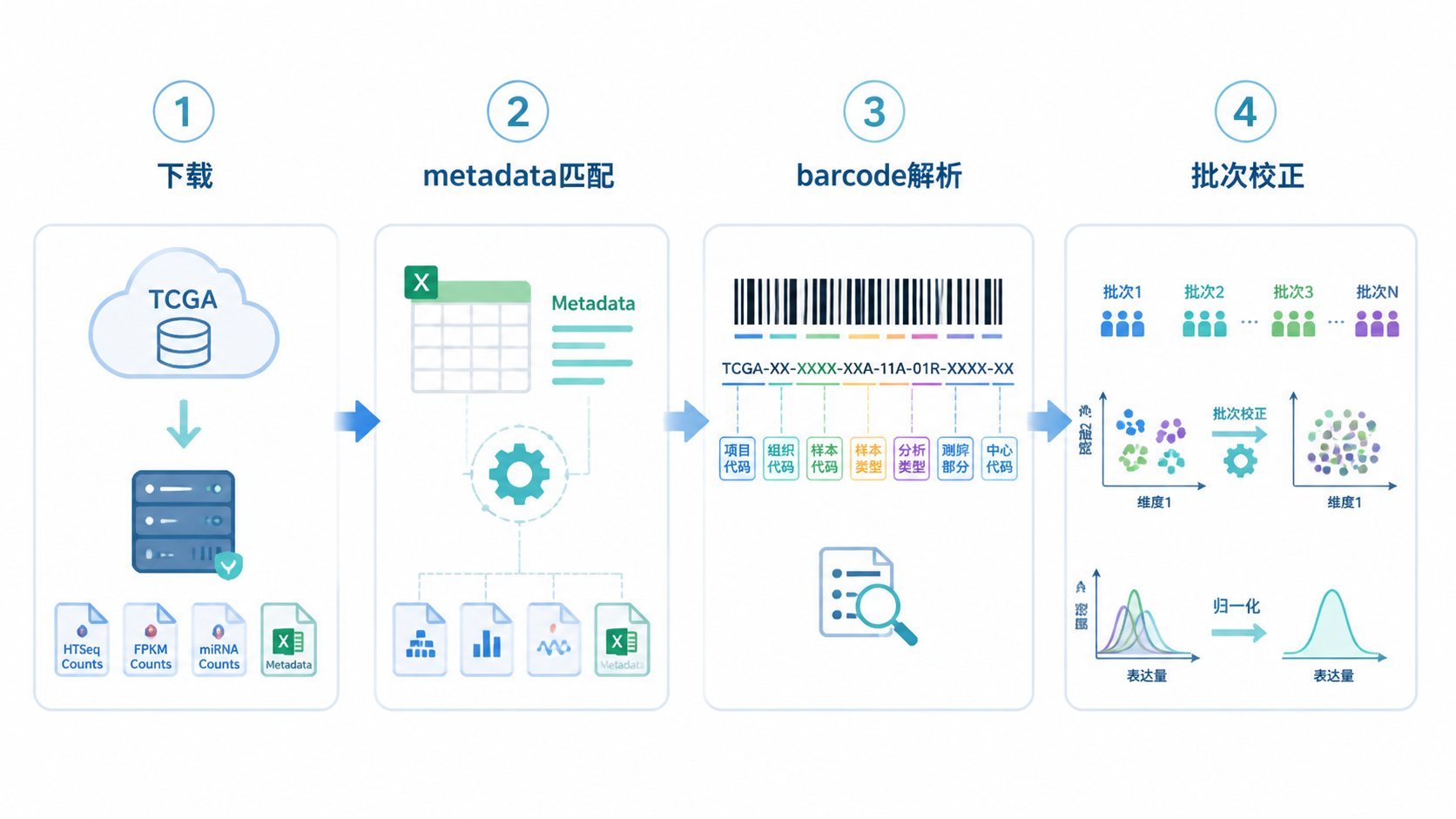
1. 为什么TCGA表达数据处理是分析起点
1.1 原始表达矩阵不等于可分析数据
TCGA下载到的表达矩阵通常只是起点。文件之间要先建立一一对应关系,再确认样本顺序、列名和临床信息是否匹配。课程中提到,很多count文件的行列结构一致,甚至第一列完全相同,说明可以用统一方式合并。但前提是先完成样本映射。
如果样本和文件名对不上,后面的所有分析都会失真。 这是TCGA表达数据处理最核心的风险。
1.2 处理目标是减少系统误差
TCGA表达数据处理的目的,不只是整理表格,而是尽量降低技术偏差和注释偏差。包括:
- 统一样本命名规则。
- 清除重复或不适合分析的样本。
- 保留可解释、可复现的数据。
- 为差异分析、分型分析和生存分析打基础。
对高通量数据来说,前处理质量往往比后续模型更关键。
2. Metadata是TCGA表达数据处理的第一把钥匙
2.1 metadata解决“文件是谁”的问题
课程中强调,metadata的作用是把原始文件名和TCGA样本ID对应起来。常见做法是下载JSON格式文件,用R的jsonlite读取,再从associated_entities中提取样本ID。这个步骤看起来简单,但它决定了表达矩阵列名是否正确。
没有metadata,表达数据就只是无名矩阵。
2.2 文件名、sample ID与临床信息必须一致
实际分析时,表达数据、临床数据、分组信息必须来自同一套样本编号。常见问题包括:
- 文件名顺序和下载顺序不一致。
- 样本ID提取位置因肿瘤类型而不同。
- 临床表和表达矩阵对应不上。
因此,TCGA表达数据处理必须先完成样本映射,再谈分组、分期和预后分析。
2.3 manifest文件能帮助核对映射关系
manifest文件可以整理样本和文件名的对应关系,便于批量核对。对大规模项目而言,这一步能明显减少人工错误。对于动辄几百个样本的TCGA项目,这种核对几乎是必需的。
3. barcode解析决定样本分组是否正确
3.1 barcode里藏着样本来源信息
TCGA barcode不是普通编号,而是样本身份标签。它包含项目名称、组织来源、样本类型、分析类型、板号和中心代码。课程中明确指出,第14、15位字符尤其关键,常用于区分组织学类型。
01通常代表原发肿瘤,11通常代表正常组织。
这意味着,分组错误会直接导致肿瘤组和正常组混淆。
3.2 analyte、plate和center影响技术解释
barcode中还包含analyte、plate和center信息。
其中:
- D代表DNA。
- R代表RNA。
- plate代表测序板编号。
- center代表数据分析中心代码。
这些信息有助于识别批次来源。做TCGA表达数据处理时,不能只看表达值,还要看这些元数据是否提示了系统性偏差。
3.3 TSS和批次效应要提前识别
课程中提到,TSS编码和测序板信息可用于识别批次效应。若同一分组样本集中来自少数中心或少数板号,后续差异可能被技术差异放大。对科研论文来说,这类偏差是最容易被审稿人质疑的点之一。
4. TCGA与GTEx合并前,必须先处理批次效应
4.1 为什么癌旁不足时要合并GTEx
很多癌种缺少足够的癌旁正常组织。此时会考虑合并GTEx正常组织,以增强统计功效。但这不是简单拼表。因为两个来源的数据在测序平台、处理流程和样本注释上可能存在差异。
合并的目标不是“样本越多越好”,而是“同质性足够高”。
4.2 推荐统一使用重新分析后的数据
知识库建议,从UCSC等来源获取统一重新分析处理的数据,减少技术差异。这样做的好处是:
- 降低不同项目之间的流程差异。
- 更便于后续标准化。
- 批次效应相对更可控。
这一步对TCGA表达数据处理尤其重要,因为TCGA和GTEx一旦合并,批次问题会被放大。
4.3 批次校正不是可选项
可用RUVSeq、SVA等R包处理批次效应。它们的作用是从表达矩阵中识别并消除非生物学变化。对于需要联合分析的项目,批次校正应当是标准步骤,而不是补救措施。
5. ID转换看似小事,实际上影响注释质量
5.1 基因组版本不同会带来注释差异
TCGA表达数据处理里,ID转换常涉及不同基因组版本。知识库提到GRCh38与早期版本存在差异,TCGA和GTEx也可能使用不同版本的注释文件。若不统一,基因ID和基因名的对应关系就可能不完全一致。
5.2 版本差异通常不一定决定结论
课程小结指出,采用不同版本的注释进行ID转换,对最终分析结果影响不大,但前提是转换逻辑一致,且注释来源清楚。对论文写作来说,这一点很重要,因为它影响方法部分是否严谨。
5.3 实操时要保留可追溯性
建议记录以下信息:
- 注释文件来源。
- GTF或GFF版本。
- 基因ID到symbol的映射规则。
- 是否丢弃多重映射基因。
可追溯性比“看起来完整”更重要。
6. 样本过滤和基因过滤决定统计稳定性
6.1 样本过滤先排除明显异常样本
课程中提到,要先查看样本的NT信息和annotation信息,核查病例类型是否正确。比如不同肿瘤之间的边界并不总是清晰,必须靠注释表确认。胆管癌和肝癌等边界模糊项目,更需要仔细核查。
6.2 基因过滤能提高差异分析敏感性
RNA-seq差异分析前,常见过滤策略包括:
- 去除表达量为0的基因。
- 保留至少一半样本中表达量大于0的基因。
- 保留中位数大于0的基因。
这些方法没有唯一标准,但原则一致。过滤低表达基因可以减少噪音,提高统计效率。
6.3 平均值过滤要谨慎使用
平均值过滤看似直观,但容易受极端值影响。相比之下,中位数或“在多数样本中表达”的规则更稳健。做TCGA表达数据处理时,过滤标准应与研究目的一致,而不是机械套用。
7. 规范的TCGA表达数据处理能直接提升论文质量
7.1 处理规范决定结果是否可信
如果样本ID混乱、barcode解析错误、批次效应未处理、过滤标准不统一,那么差异基因、通路富集和预后模型都可能出现偏差。对临床转化研究来说,这种偏差尤其危险,因为它会影响生物标志物判断。
7.2 标准化流程有助于复现
一套完整的TCGA表达数据处理流程,通常应包含:
- 下载metadata和manifest。
- 建立文件名与样本ID映射。
- 解析barcode并区分样本类型。
- 统一注释版本并完成ID转换。
- 过滤异常样本和低表达基因。
- 必要时进行批次校正。
- 再进入差异分析和下游建模。
这套流程能显著提高复现性,也更符合E-E-A-T要求中的专业性与可信度。
7.3 用解螺旋工具能减少重复劳动
如果你希望把更多时间放在生物学问题而不是反复清洗表格上,解螺旋 提供的生信课程和方法体系能帮助你更快建立标准化流程。对于TCGA表达数据处理来说,关键不是做更多步骤,而是把每一步做对。借助成熟的方法框架,能更高效完成metadata匹配、barcode解析、过滤和批次校正,减少人为失误,提高分析效率。
总结Conclusion
TCGA表达数据处理之所以重要,是因为它决定了样本是否正确、分组是否可靠、批次是否可控、注释是否一致,以及最终结论是否可信。对医学生、医生和科研人员来说,前处理不是附属工作,而是研究质量的核心。先把数据处理标准化,后续分析才有意义。
如果你正在做TCGA表达数据处理,建议直接建立规范流程,必要时借助解螺旋 的专业内容和实战方法,少走弯路,更快产出可发表、可复现的结果。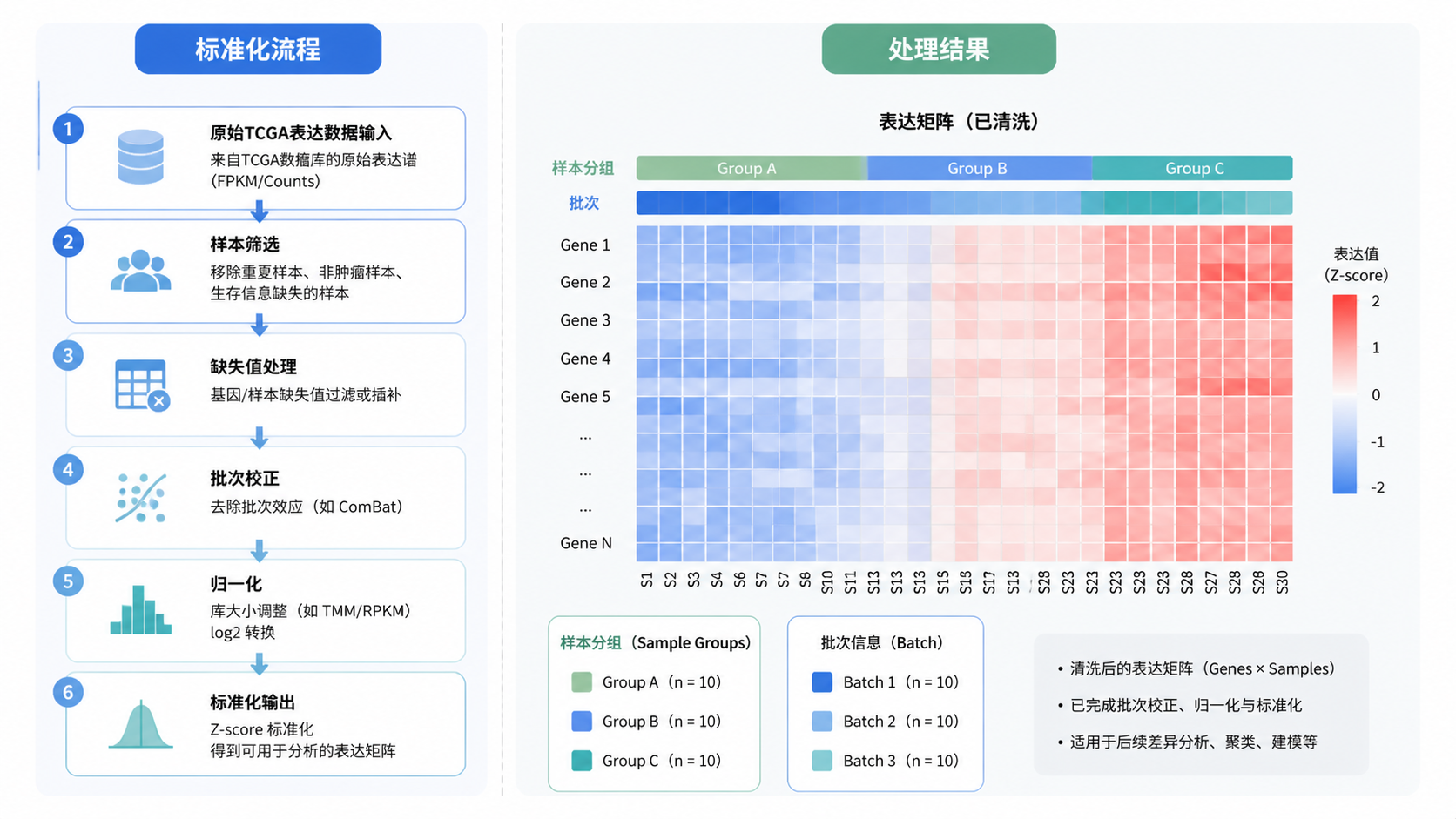
- 引言Introduction
- 1. 为什么TCGA表达数据处理是分析起点
- 2. Metadata是TCGA表达数据处理的第一把钥匙
- 3. barcode解析决定样本分组是否正确
- 4. TCGA与GTEx合并前,必须先处理批次效应
- 5. ID转换看似小事,实际上影响注释质量
- 6. 样本过滤和基因过滤决定统计稳定性
- 7. 规范的TCGA表达数据处理能直接提升论文质量
- 总结Conclusion