引言Introduction
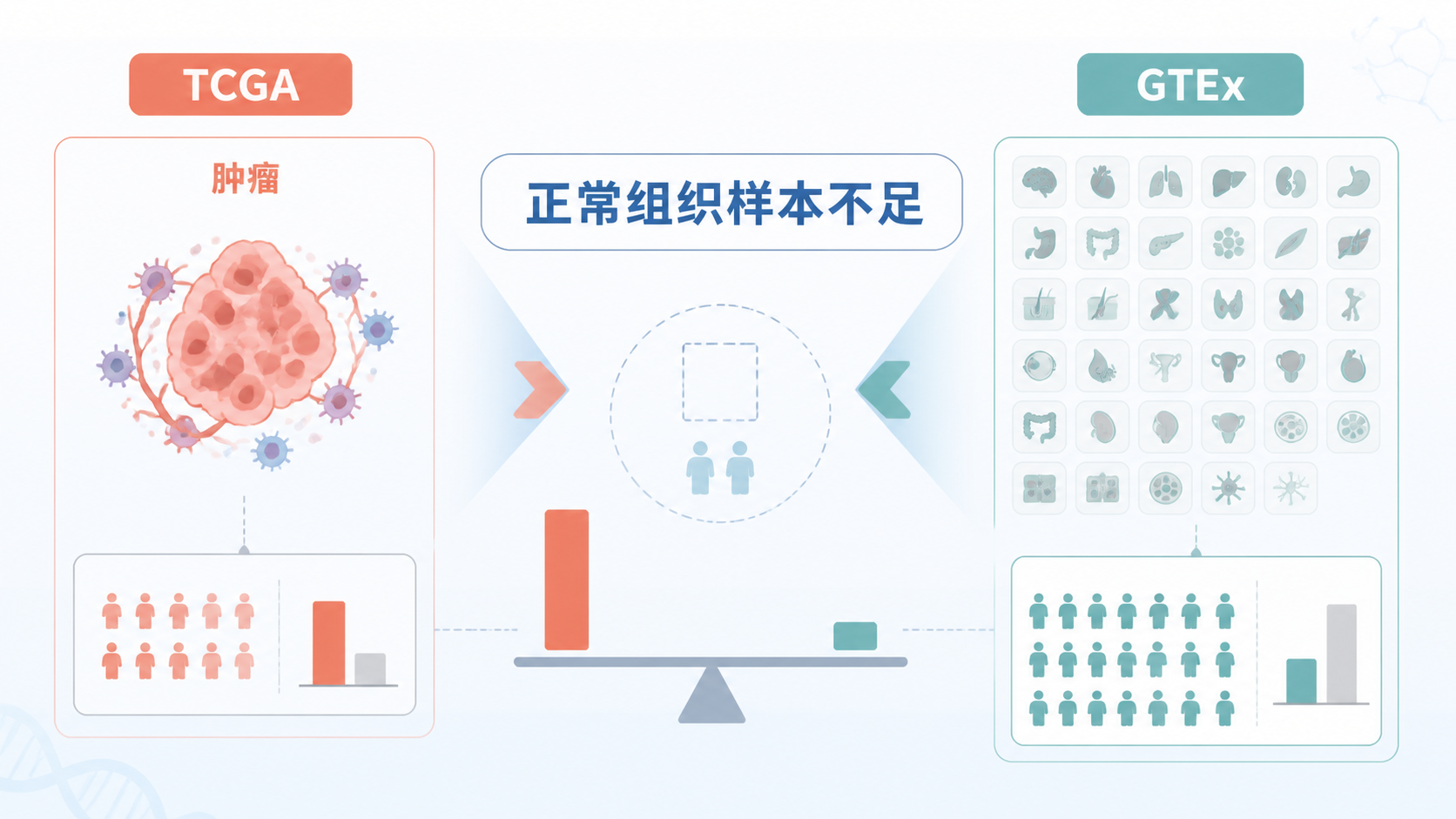
GTEx数据库是做转录组研究时绕不开的资源。当TCGA正常样本不足,尤其是某些癌种对照极少时,GTEx数据库可以有效补足正常组织表达数据。 对医学生、医生和科研人员来说,先搞清它能解决什么问题,再学会怎么用,才是高效入门的关键。
1. 先理解GTEx数据库的定位
1.1 GTEx数据库解决什么问题
GTEx全称是The Genotype-Tissue Expression project。它的核心价值,不是研究肿瘤,而是提供来自健康捐献者的多组织表达图谱 。上游知识库显示,GTEx研究联盟收集了来自449名生前健康捐献者的7000多份尸检样本,覆盖44个组织。
这意味着,在做疾病研究时,如果TCGA里正常样本太少,GTEx数据库就能成为重要补充。尤其在寻找目标基因的正常组织表达背景时,它非常有用。
1.2 为什么它适合入门
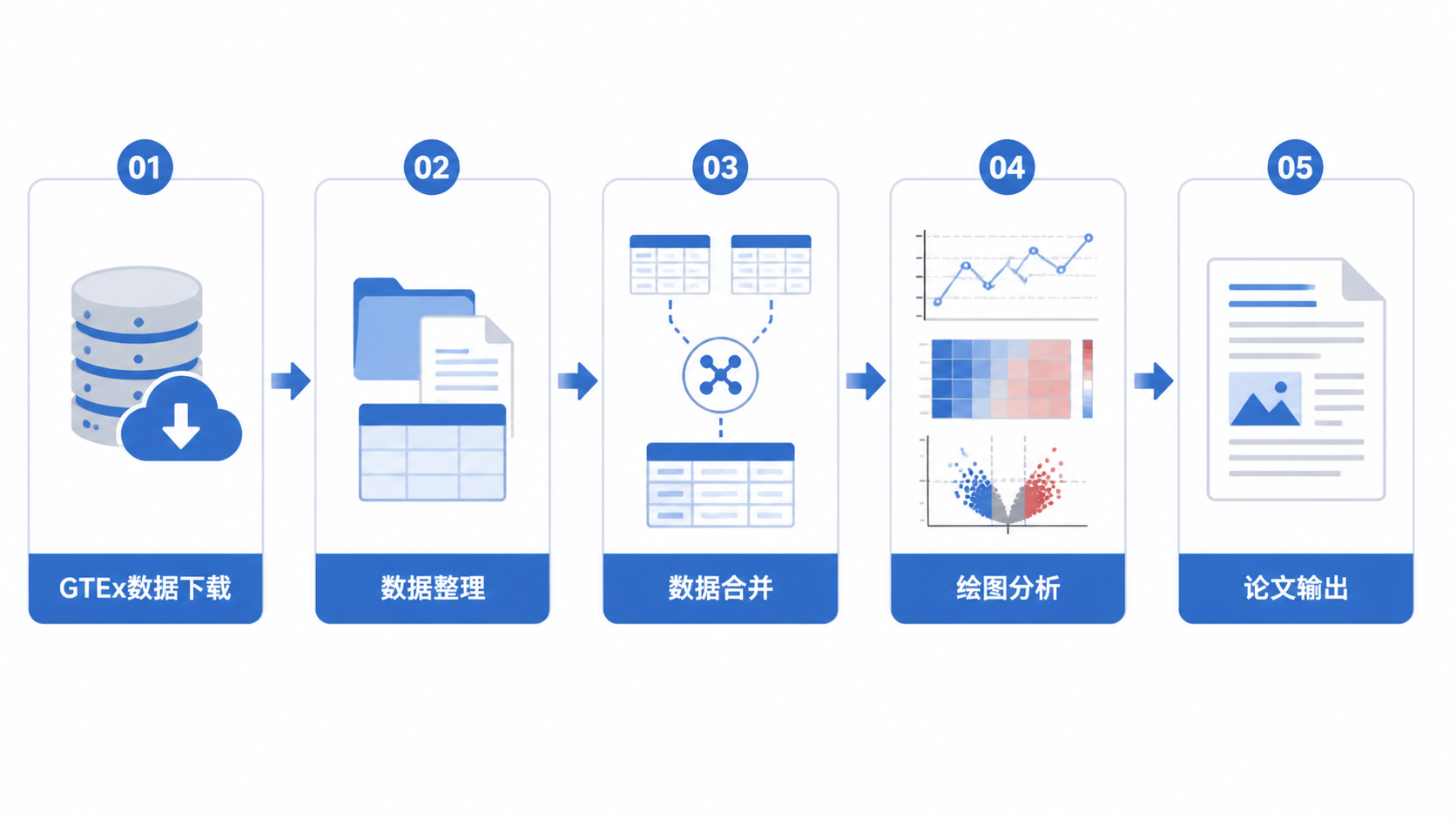
相比TCGA,GTEx数据库的下载和整理更直接。常用入门思路很清晰。
- 下载表达矩阵。
- 下载样本注释文件。
- 合并表达和组织来源信息。
- 可视化目标基因在不同组织的分布。
这种流程适合快速建立分析框架。后续无论是做非肿瘤组织表达分析,还是为肿瘤研究补正常对照,都能沿用。
2. 下载GTEx数据库的两个核心文件
2.1 表达矩阵是基础
在GTEx数据库中,最重要的是表达矩阵。上游知识库明确提到,常用的是gene read counts文件。它体积较大,约875M。后续如需FPKM或TPM,也可在此基础上转换。
对于初学者,先掌握counts矩阵最稳妥。 因为它最适合后续标准化、差异分析和建模。
2.2 样本注释文件不能少
只拿表达矩阵还不够。GTEx数据库中的样本ID是数据库自定义的,必须配合注释文件使用。课程中提到,应下载“GTEx_Analysis_v8_Annotations_SampleAttributesDS”。这个文件能把样本ID对应到组织来源。
也就是说,表达矩阵告诉你“表达多少”,注释文件告诉你“来自哪里”。两者结合,才有分析意义。
3. 读取和整理GTEx数据库数据
3.1 大文件建议用fread
GTEx表达文件较大,直接读取可能很慢。上游知识库建议用R语言中的两种方式:read.table()和data.table::fread()。其中,fread()更适合大文件。
其优势很明确。
- 读取速度快。
- 对大规模文本更友好。
- 适合批量处理转录组数据。
如果文件开头有说明行,也可以通过skip参数跳过。在真实项目里,fread通常是更实用的选择。
3.2 先检查数据结构再进入分析
读取后,通常会看到第二列是基因symbol,后面是每个样本的count值。此时建议先做两件事。
- 检查行名和列名是否正确。
- 将原始矩阵保存为
.rda或类似格式,便于重复调用。
这是一个很实用的习惯。因为GTEx数据库数据量大,重复读取会显著拖慢分析。
4. 用样本注释建立组织分组
4.1 提取关键列
注释文件里信息很多,但入门阶段只需关注两列:SAMPID和SMTS。前者是样本ID,后者是组织来源。
上游知识库建议用这两个字段进行整理,并用table()查看各组织样本数量。这样你能快速知道哪些组织样本多,哪些组织样本少。
4.2 为什么分组很重要
GTEx数据库的优势在于组织覆盖广。44个组织意味着你可以比较基因在不同生理背景下的表达差异。
分组做对了,后面的图才有解释力。
比如同一个基因,在全血、皮肤、脑组织、乳腺等不同组织中,基础表达模式可能差异很大。对医学生和研究人员来说,这种背景信息非常关键。
5. 提取目标基因并做可视化
5.1 以目标基因构建分析子集
上游课程用BTK基因举例。实际操作中,先根据目标基因名提取表达子集,再和组织注释合并。常见方法包括%in%和which()。
这一步的本质是把“全量矩阵”缩小成“目标基因表达表”。这样更利于快速展示和解读。
5.2 合并后建议做对数转换
表达数据常见分布偏右,直接画图不够直观。课程中提到,合并表达和表型后进行了对数转换,再使用ggplot2和ggpubr绘图。
常见做法是:
- 合并表达值与组织来源。
- 对表达值进行log转换。
- 绘制箱线图或小提琴图。
- 旋转x轴标签,避免重叠。
这类图非常适合放在文章开篇,快速呈现目标基因的组织表达背景。
6. GTEx数据库在科研中的常见用途
6.1 用于正常对照补充
这是GTEx数据库最常见的应用场景。尤其是某些癌种正常样本少,GTEx能补足对照不足的问题。上游知识库明确举例,乳腺癌和宫颈癌的正常样本都可能明显偏少。
因此,在肿瘤转录组研究中,GTEx数据库常被用于:
- 构建更完整的正常组织背景。
- 辅助表达差异展示。
- 为候选基因筛选提供参照。
6.2 用于非肿瘤研究开篇
很多人只把GTEx数据库和肿瘤联系在一起。实际上,它对非肿瘤研究同样有价值。因为样本来自健康捐献者,能直接体现基因在正常人体组织中的基础表达谱。
对于机制研究、组织特异性分析和靶点背景验证,这一点尤其重要。
7. 从入门到可复现分析的关键习惯
7.1 先规范数据,再谈统计
GTEx数据库入门不难,难的是把流程做规范。建议始终保持以下顺序。
- 下载原始文件。
- 整理表达矩阵。
- 整理样本注释。
- 统一样本ID。
- 再做合并与绘图。
这样做的好处是,后续无论换基因、换组织,还是换项目,都能快速复用。
7.2 外部验证思路也可迁移
虽然本篇重点是GTEx数据库,但上游知识库也提到ICGC数据库常用于外部验证。这个思路值得借鉴。先用GTEx建立正常组织背景,再用其他队列验证结论,是更稳妥的研究路径。
对于科研人员而言,这种组合方式能提升结果的可信度,也更符合E-E-A-T导向下对证据链完整性的要求。
总结Conclusion
GTEx数据库的核心价值很明确。它能补足正常组织表达背景,帮助研究者更准确地理解基因在不同组织中的基础表达模式。入门时只要抓住7个步骤, 即可完成从下载、整理到可视化的完整流程。对医学生、医生和科研人员来说,这是一套高频且实用的基础技能。
如果你希望更高效地复现GTEx数据库分析流程,减少数据整理的重复劳动,可以借助解螺旋品牌 提供的科研支持与方法资源,把更多时间留给真正的课题设计和结果解释。
- 引言Introduction
- 1. 先理解GTEx数据库的定位
- 2. 下载GTEx数据库的两个核心文件
- 3. 读取和整理GTEx数据库数据
- 4. 用样本注释建立组织分组
- 5. 提取目标基因并做可视化
- 6. GTEx数据库在科研中的常见用途
- 7. 从入门到可复现分析的关键习惯
- 总结Conclusion