引言Introduction
在生物医学研究中,基因列表做出来了,下一步怎么找关系、找核心分子、找互作网络,常让人卡住。string数据库 正是解决这一步的高频工具。它能快速把分子之间的关系可视化,帮助你从“很多基因”缩到“关键节点”。
1. string数据库是什么,为什么生物医学研究离不开它
1.1 从“找朋友”到“找网络”
在生信分析里,很多人第一步会做差异分析,得到一批候选基因。但基因多不等于结论强。真正决定研究深度的,是这些分子之间有没有互作关系 。
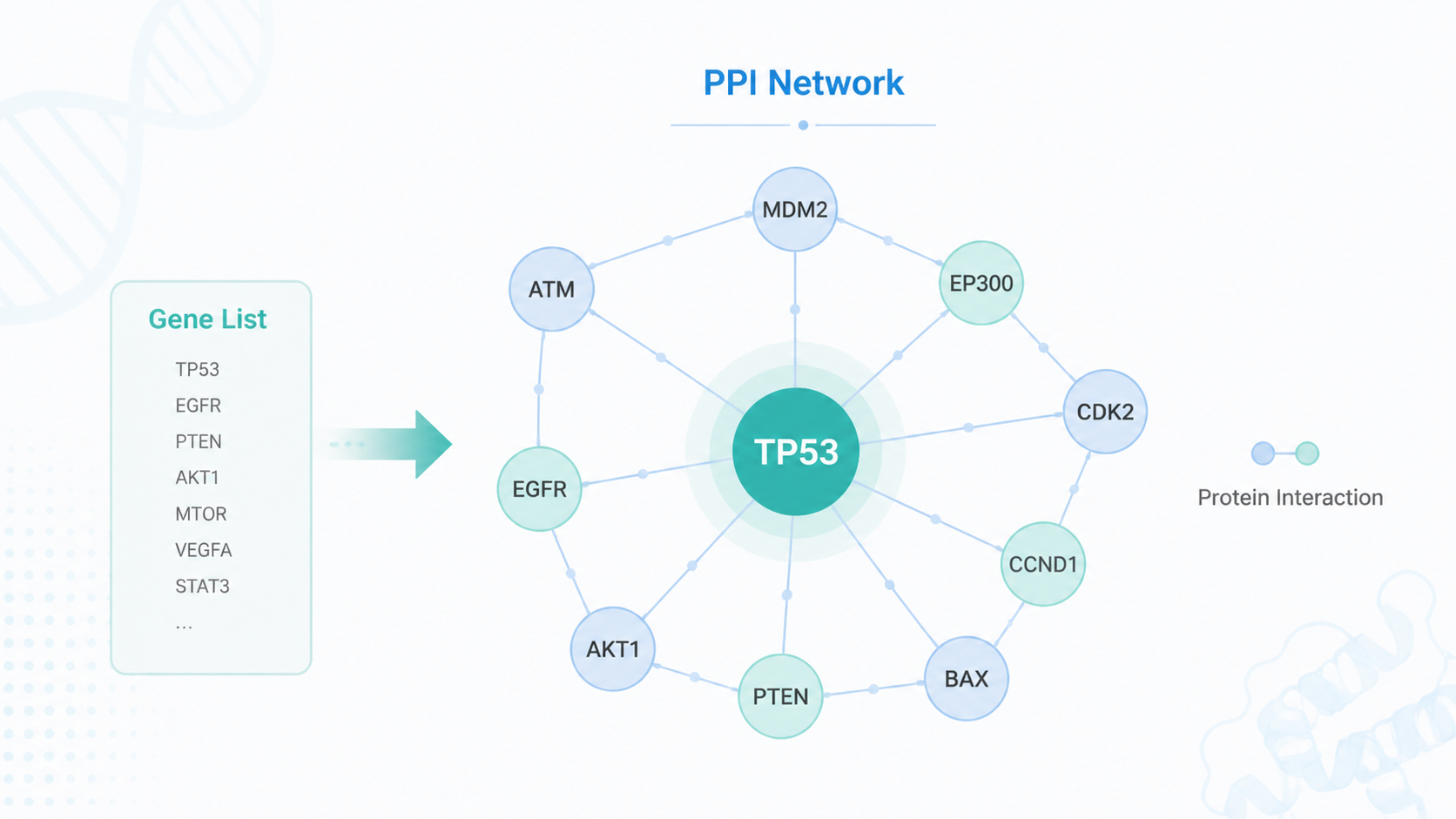
这就是 string数据库最常见的用途。它可以把蛋白之间的已知或预测互作关系整理出来,形成网络图。对研究者来说,这一步相当于把“散点信息”变成“结构信息”。
1.2 为什么它能提升效率
如果只靠人工查文献,一个基因接一个基因去找关系,效率很低。string数据库的价值在于,它能在较短时间内帮助你完成以下工作。
- 快速查看蛋白互作网络。
- 识别网络中的核心节点。
- 为后续功能富集、机制推断提供方向。
- 帮助筛选更值得深入验证的分子。
对医学生、医生和科研人员来说,这种“先筛后挖”的思路,能明显减少无效工作。
2. string数据库在分析流程中的位置
2.1 先筛选,再建网
上游知识库中强调得很明确,研究不能一开始就“无脑研究所有基因”。正确做法是先抓主要矛盾。
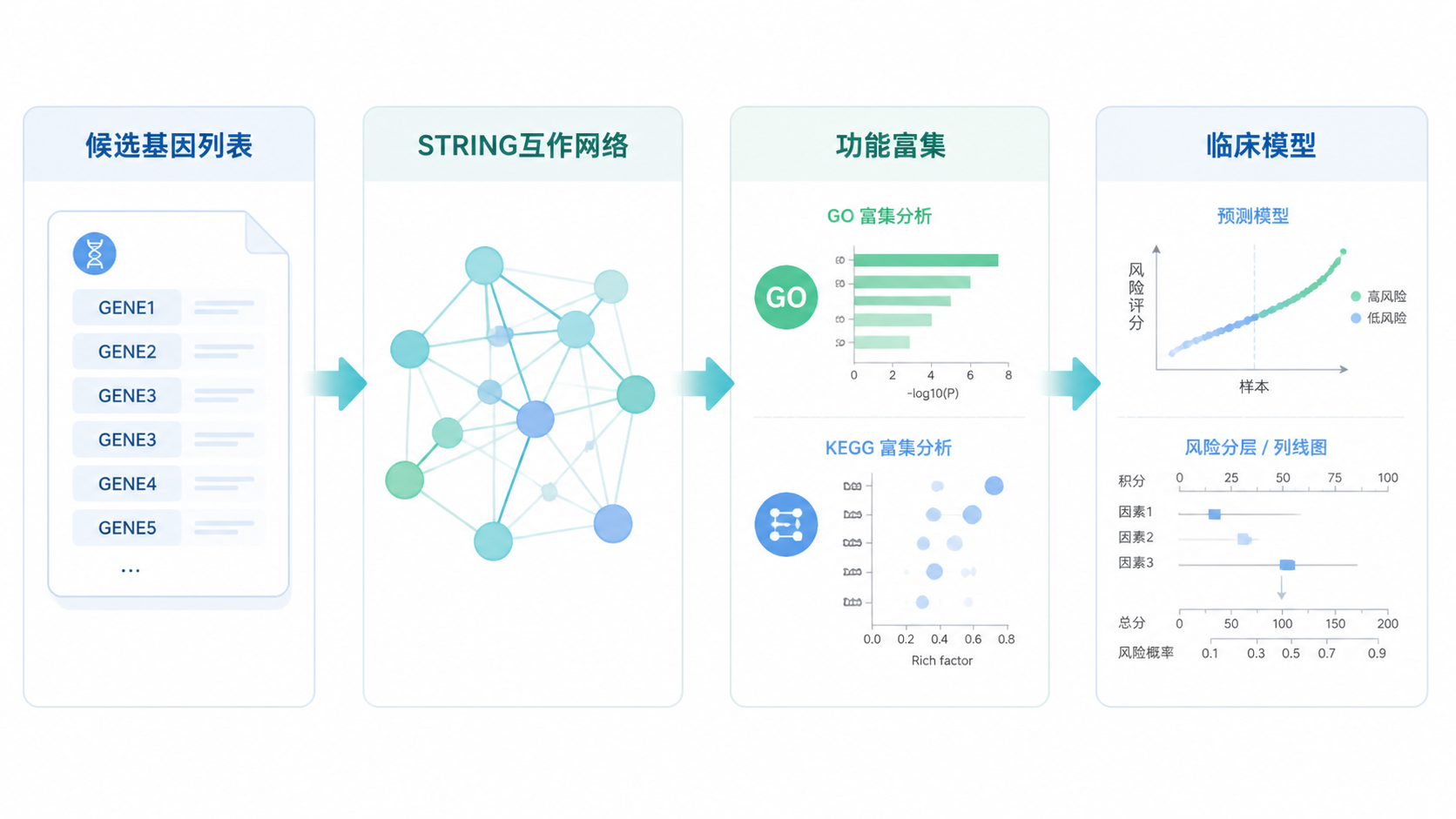
常见流程通常是:
- 先得到候选基因。
- 再看这些基因的功能归属。
- 最后用 string数据库建立互作关系。
这样做的好处是,你不会被成百上千个基因淹没,而是逐步聚焦到几十个,甚至几个关键分子。
2.2 它适合什么类型的数据
string数据库最适合已经筛出的分子集合。比如。
- 转录组差异基因。
- 蛋白组差异蛋白。
- 某个表型相关基因列表。
- 与疾病表型交集后的候选基因。
它不是用来替代差异分析的,而是用来承接差异分析之后的机制探索。
3. string数据库怎么帮助你找到核心基因
3.1 网络中心性思路很关键
在互作网络里,和更多分子发生联系的节点,往往更值得关注。知识库里用“核心基因”和“边缘基因”做了形象类比。
在实际研究中,这种思路非常实用。因为高连接度节点更可能参与多个生物学过程,也更容易成为后续验证对象。
3.2 适合从大列表中快速缩小范围
很多项目一开始会拿到几百个候选分子。此时最怕的不是没有结果,而是结果太多。
借助 string数据库,你可以先看互作是否集中,再结合功能分析,判断哪些分子值得留下。
这一步的目标不是“看全”,而是“看准”。
3.3 与功能富集是互补关系
string数据库解决的是“分子之间怎么连”。富集分析解决的是“这些分子大概做什么”。
两者组合后,机制链条会更完整。
例如,你可以先用 string数据库观察网络结构,再结合功能富集判断是否与增殖、应激、铁死亡等过程相关。
这样写出来的结果部分,逻辑会更紧密。
4. string数据库如何服务于不同研究场景
4.1 疾病机制研究
在疾病机制研究中,string数据库常用于解释候选基因之间的协同关系。
比如某些分子可能共同参与炎症、代谢异常或细胞死亡过程。通过互作网络,你可以更快看到它们是否属于同一功能模块。
这比单看表达量更接近真实生物学过程。
4.2 生物标志物筛选
如果你的目标是做 biomarker,string数据库也很有用。
它能帮助你判断候选标志物是否处在网络关键位置。
网络中心分子通常更有潜力成为诊断或预后分析中的重点对象。
当然,是否真的可用,还要结合临床变量、ROC、回归模型等进一步判断。
4.3 组学文章的机制补强
很多纯生信文章最容易被质疑的一点,是“只停留在差异表达”。
这时,string数据库可以作为机制补强工具。
它能把你的候选分子从“表达变化”推进到“互作关系”,让论文结构更完整。
对于想提高文章完成度的研究者,这一步非常实用。
5. 使用 string数据库时,哪些地方最容易踩坑
5.1 不要把网络图当结论
string数据库给的是互作线索,不是最终因果证据。
它能提示可能的关系,但不能单独证明疾病机制。
所以写作时要避免过度解读,最好把它表述为“提示”“支持”或“提供线索”。
5.2 输入基因前要先做筛选
如果候选列表太杂,网络图会很乱,最后什么也看不清。
所以在进入 string数据库前,最好先完成基础筛选。
例如。
- 先取差异基因。
- 再与表型相关基因列表取交集。
- 再进入互作分析。
这会显著提高可解释性。
5.3 结果要和上下游分析联动
单独一个网络图不够。
更稳妥的做法是把 string数据库结果和以下分析联起来。
- 功能富集。
- 临床相关性分析。
- 预测模型。
- 关键基因验证。
只有形成闭环,文章才更像完整研究,而不是工具拼接。
6. string数据库与解螺旋式分析思路的结合
6.1 从“会用工具”到“用对工具”
上游知识库反复强调,真正重要的不是把所有数据库都点一遍,而是知道在什么时候用什么工具。
string数据库适合做的,是候选分子的互作关系梳理。
当你已经完成分子筛选、功能归类后,它能迅速把结果整理成可视化网络,减少重复劳动。
6.2 对科研效率的实际帮助
如果一个课题从头到尾都靠人工查文献,不仅慢,而且容易遗漏关键关系。
而把 string数据库纳入标准流程后,你可以更快完成。
- 候选分子网络梳理。
- 核心节点识别。
- 机制假设生成。
- 论文结果图优化。
这对赶时间发文、做课题申报、准备返修,都有现实价值。
6.3 适合和解螺旋的产品化服务配合
如果你在项目中已经有候选基因集,但缺少分析框架,解螺旋的相关生信服务可以帮助你把思路串起来。
从筛基因,到做互作网络,再到临床相关和模型构建,流程更清晰,产出更稳定。
这类产品化支持,特别适合需要高效率推进课题的医学生、临床医生和科研人员。
总结Conclusion
总体来看,string数据库 的核心价值,不只是画出一个漂亮的互作网络,而是帮助研究者更快完成从“候选分子”到“关键机制”的过渡。它能提升筛选效率,减少无效探索,并为功能富集、临床分析和预测模型提供更稳的基础。
对于追求高质量科研产出的团队来说,合理使用 string数据库,是提升分析效率的实用路径。若你希望把候选基因快速转化为可发表的机制结果,不妨结合解螺旋 的专业支持,让分析流程更清楚,项目推进更高效。
- 引言Introduction
- 1. string数据库是什么,为什么生物医学研究离不开它
- 2. string数据库在分析流程中的位置
- 3. string数据库怎么帮助你找到核心基因
- 4. string数据库如何服务于不同研究场景
- 5. 使用 string数据库时,哪些地方最容易踩坑
- 6. string数据库与解螺旋式分析思路的结合
- 总结Conclusion