





引言Introduction
生信数据规范 看似是流程问题,实则直接决定研究能否复现、能否发表、能否通过审稿。对医学生、医生和科研人员来说,最常见的痛点不是“没有数据”,而是数据来源混乱、分析口径不一致、结果前后冲突。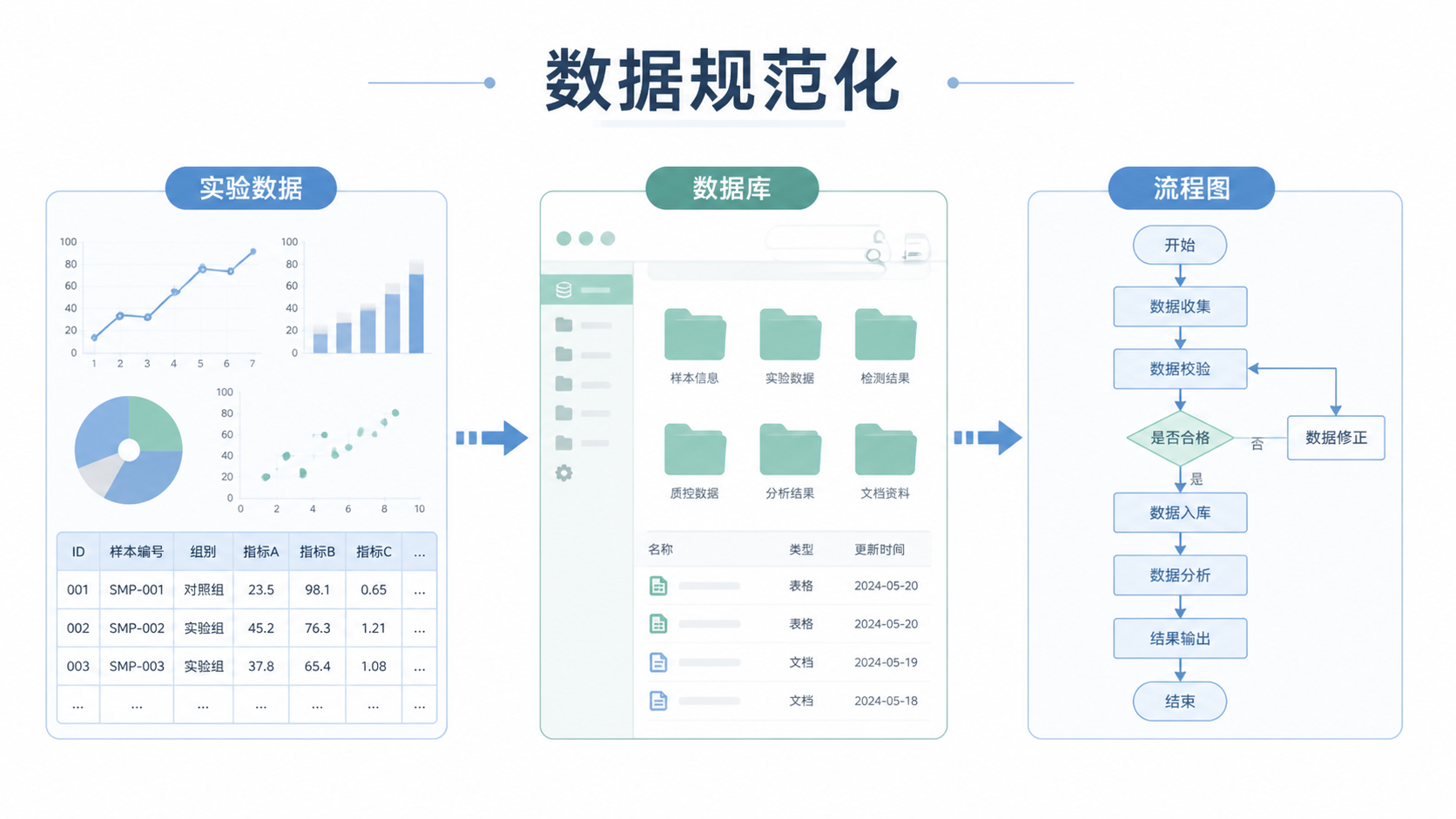
1. 生信数据规范为什么会出问题
1.1 数据来源不一致
生信研究的第一变量是数据特征,核心就包括数据来源、检测方法和分子类型。同样是疾病研究,样本来自人群、动物模型、细胞模型,结论就可能不同。
另外,内部数据和外部公开数据也不能混用后不加说明。前者来自自己的实验,后者来自已发表数据库。来源不同,样本背景、处理流程、批次效应都可能不同。
1.2 检测平台和分子类型混淆
一个技术平台可以检测不同分子,一个分子类型也可以由不同平台测得。芯片、测序、质谱对应的检测对象并不完全相同。如果不把平台和分子类型分开记录,后续分析对象就会失真。
这类问题在二次分析中尤其常见。文中写的是RNA,实际数据却来自蛋白组,或者用的是mRNA流程去处理lncRNA数据,都会影响结果解释。
1.3 分析策略口径不统一
数据之外,第二个变量是分析策略。统计方法、算法模型、筛选阈值,都会改变结果。同一份数据,用不同策略分析,结论可能完全不一样。
这也是为什么生信数据规范不是简单整理文件,而是要把“数据特征”和“分析策略”一起规范化。
2. 生信数据规范的3个核心风险
2.1 风险一,数据对象错配
这是最基础,也最致命的风险。常见表现包括样本类型选错、疾病亚型选错、组织来源不匹配。
例如,研究的目标是临床诊断,却拿了不适合临床场景的组织数据。或者本该分析血液样本,却用了病理组织样本。对象错配会让研究从一开始就偏离真实问题。
更严重的是,错配往往不是分析时报错,而是结果出来后才暴露。此时再回头修正,前面的差异分析、聚类分析、网络分析都要重做,时间成本很高。
2.2 风险二,分析口径漂移
第二个核心风险,是同一研究在不同阶段使用了不同口径。比如前期筛选阈值一个标准,后期验证又换了标准。或者不同图表用的归一化方式不一致。
口径漂移会直接破坏结果一致性。
这类问题最容易体现在以下环节:
- 差异分子列表前后不一致。
- 同一基因在不同图中方向相反。
- 训练集和验证集处理流程不统一。
- 论文图表和补充材料描述不一致。
从审稿角度看,这不是小问题。它会让人怀疑结果是否可复现,甚至怀疑数据处理是否严谨。
2.3 风险三,证据链断裂
第三个核心风险,是数据、方法、结论之间没有完整链条。也就是说,你知道“做了什么”,但说不清“为什么这样做”,更说不清“结论如何被支持”。
生信数据规范的本质,不只是存档,而是让证据链可追溯。
常见断裂点有三个:
- 数据集来源不清晰,无法复核。
- 分析步骤缺失,别人无法复现。
- 结果解释超出数据支持范围。
对于科研文章来说,这类问题会明显拉低可信度。尤其是面向医生和科研人员的研究,审稿人最在意的就是数据是否可追溯、方法是否透明、结论是否站得住。
3. 如何建立可执行的生信数据规范
3.1 先把四个基础信息写清楚
生信数据规范的第一步,不是上来就跑分析,而是先确认四件事:
- 疾病问题是什么。
- 数据来源是什么。
- 检测方法是什么。
- 分子类型是什么。
这四项信息写不清,后面的分析就没有统一起点。
建议在项目开始时就建立数据登记表,至少包含样本来源、平台名称、版本号、纳入排除标准和分析目的。
3.2 再统一分析流程
分析流程要尽量固定。特别是差异分析、功能聚类、交互网络和临床意义分析,最好形成模板。
这样做的好处是,后续换数据时,只替换数据特征,不随意改动主流程。流程固定,结果才更容易比较。
如果做的是内部数据和外部数据联合分析,还要提前定义:
- 哪一套数据用于建模。
- 哪一套数据用于验证。
- 哪一步做标准化。
- 哪一步允许调整参数。
3.3 最后做版本管理和复核
真正成熟的生信数据规范 ,一定包含版本控制。因为数据会更新,注释会变化,数据库也会迭代。
建议保留以下内容:
- 原始数据文件。
- 清洗后的数据文件。
- 分析脚本或软件参数。
- 图表输出版本。
- 最终用于写作的结果版本。
复核机制比“做过一次”更重要。
在投稿前,至少要检查一次疾病名称、样本类型、图表编号、补充材料对应关系和统计口径是否一致。
4. 为什么规范化会直接影响文章质量
4.1 规范化决定可重复性
生信研究本质上依赖数据。数据一旦不规范,后续再复杂的模型都只是“建立在沙地上”。
规范化越好,文章的可重复性越强。
对于临床和科研场景,这意味着结果更可信,也更容易通过同行评议。
4.2 规范化决定选题扩展能力
同一疾病、同一问题,如果数据特征不同,研究切入点就不同。
你可以做不同来源的数据,可以换平台,可以换分子类型,也可以更换分析策略。规范化之后,课题扩展才有基础。
4.3 规范化决定项目效率
很多科研卡点,不是不会分析,而是前期规范没做好,导致后期反复返工。
把数据来源、检测方法、分子类型和分析策略提前固定,能明显减少返工。对临床科研团队来说,这比单纯追求复杂算法更重要。
总结Conclusion
生信数据规范的3个核心风险,分别是数据对象错配、分析口径漂移和证据链断裂。 它们看起来是技术细节,实际上决定了研究能否复现、能否投稿、能否站得住。
对医学生、医生和科研人员来说,真正高效的做法不是“边做边改”,而是从一开始就把数据来源、平台、分子类型和分析流程规范起来。
如果你希望更系统地处理这些问题,减少返工,提高文章质量,可以借助解螺旋 的生信科研方法与工具,把数据管理、分析模板和结果输出统一起来,让研究更稳、更快、更可发表。【结尾配图Closing】
- 引言Introduction
- 1. 生信数据规范为什么会出问题
- 2. 生信数据规范的3个核心风险
- 3. 如何建立可执行的生信数据规范
- 4. 为什么规范化会直接影响文章质量
- 总结Conclusion



