引言Introduction
临床研究里,很多统计错误不是出在模型,而是出在数据格式标准 不统一。第一行被当成数据、分隔符选错、变量类型识别错误,都会直接影响导入、清洗和后续分析。想让数据一次导入就正确,先把格式标准化。
1. 为什么数据格式标准是分析前提?
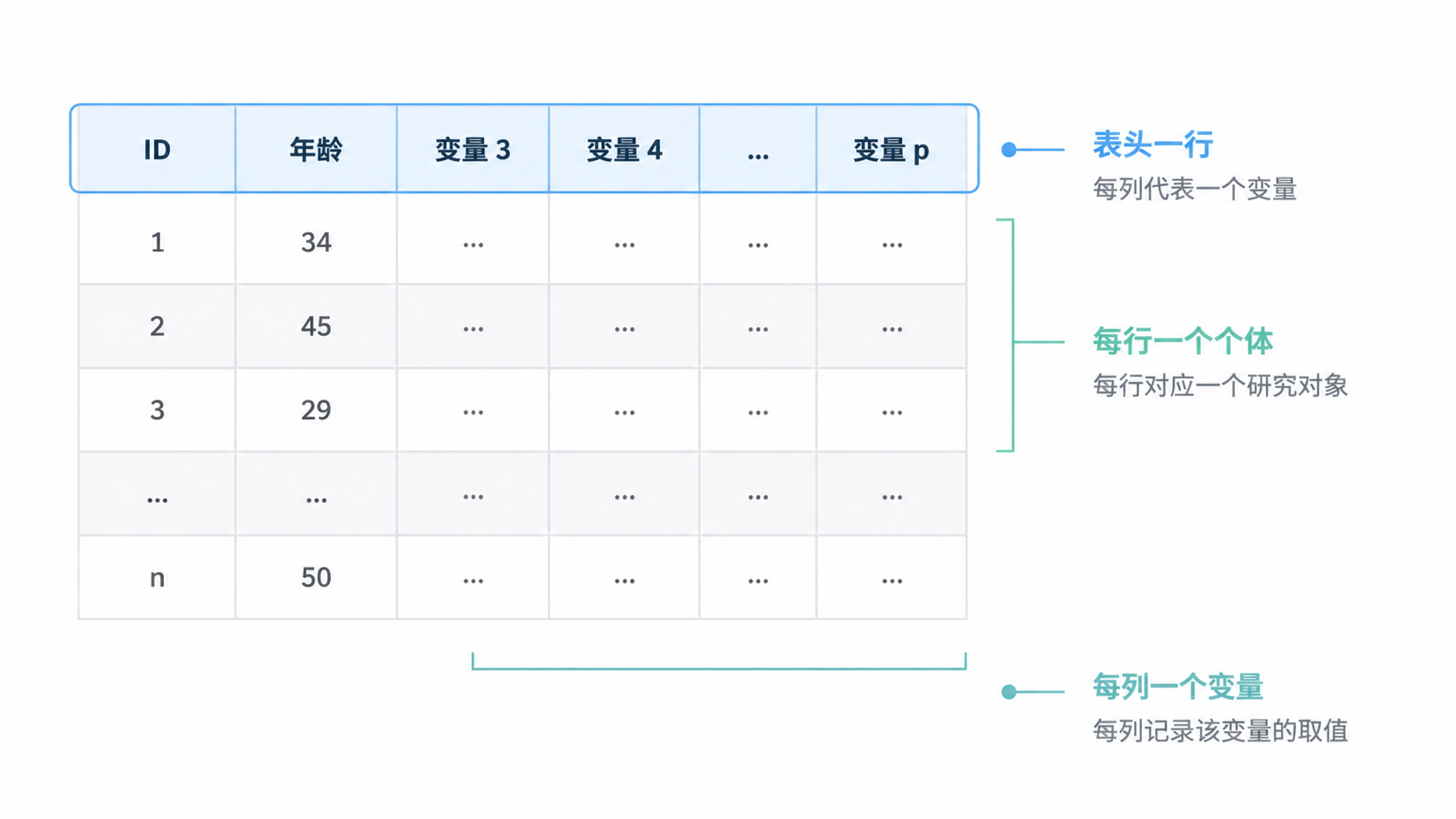
1.1 数据本质上是二维结构
在医学研究中,最常用的是二维表格数据。每一行代表一个个体,每一列代表一个变量。
这不是格式习惯,而是计算机识别和软件分析的基础。只要行列含义混乱,后续的导入、筛查、统计都会出错。
在SPSS、Excel等工具中,单元格里的每个值都同时承载两层信息。横向是变量,纵向是对象。
因此,数据格式标准的核心,不是“排得整齐”,而是让软件能准确读懂每个字段的意义。
1.2 字段命名要先统一
上游知识库明确提到,字段名建议使用英文,且不能使用空格和特殊字符 。
同时,变量名称不能重复。对于临床研究来说,这一点非常关键。
例如,时间变量如果有多个随访节点,就不能都叫Time。
更合理的做法是写成Time_1、Time_2。这样既符合数据格式标准 ,也便于后续分析和结果输出。
2. 变量命名为什么不能随意?
2.1 多层表头会导致软件误读
很多人习惯在Excel里做漂亮表格,合并单元格、两行表头、分层标题。
但在统计软件看来,这会制造歧义。软件无法判断,字段名到底是上层标题,还是下层标题。
例如,“1st follow”与“Time”被放在两行,软件可能无法准确识别。
如果变量名重复,还会直接影响导入结果。这类问题本质上都是数据格式标准不清晰。
2.2 正确做法是“一行表头”
规范的数据表应该满足三个条件:
- 表头只占一行。
- 每个字段名唯一。
- 字段名简洁、可识别、可复用。
如果遇到多次随访、多个时间点,建议用下划线区分。
这样不仅符合软件导入规则,也方便后续做重复测量分析、队列随访分析和亚组整理。
3. 导入数据时最容易出错的3个环节是什么?
3.1 第一行是否是变量名
导入CSV或其他文本文件时,最常见的错误之一,就是把第一行标题当成普通数据。
在知识库案例里,如果不勾选“第一行反映的是变量名”,ID、年龄、性别这些信息就会被误读进正文。
这一步看起来很小,但对数据格式标准影响极大。
一旦识别错误,后面再修正会很麻烦,甚至需要重新导入。
3.2 分隔符是否正确
不同文件的分隔方式并不一致。标准CSV通常用制表符,但也可能是逗号或其他符号。
如果分隔符选错,预览窗口会立刻显示异常,比如列错位、数据粘连、字段断开。
建议导入前先看预览。只要预览不整齐,说明格式还没对。
真正合格的数据格式标准,必须保证每一列都能被软件准确分开。
3.3 变量类型是否识别正确
导入时还要设置变量类型。
例如,ID通常是数值型,但性别可以是字符串或分类变量。时间变量则更要谨慎,类型选错可能影响日期运算和时间顺序判断。
知识库也提醒,变量类型这一步虽然不是每次都必须调整,但对时间变量特别重要。
因此,导入后要立刻检查变量视图,确认每一列是否被正确识别。
4. 重复个案为什么必须先清理?
4.1 重复录入会直接污染分析结果
临床数据常来自多人录入。只要流程不严,就可能出现同一病例被录入两次。
这会带来样本量虚高、事件数重复、偏倚加重等问题。
知识库中的例子很典型。系统以ID为唯一标识进行查找后,发现有重复个案,并在最后一列生成了标识变量。
如果ID重复,后续统计前必须处理。
4.2 识别重复个案的标准要明确
最理想的方式,是给每个研究对象设置唯一ID。
如果没有ID,也可以用多个条件组合判断,比如年龄、性别等,但这会增加误判风险。
所以在研究设计阶段,就应该把数据格式标准 和唯一标识规则一起定好。
这比事后补救更稳妥,也更符合临床研究的数据管理规范。
5. 规范数据整理时,最该注意哪些细节?
5.1 避免“半开放”编码混乱
知识库中提到,像治疗方案中的“9”如果表示“其他”,就不能简单把它当成独立且稳定的一类。
因为不同受试者的“其他”可能含义不同,后续统计会出现分类混乱。
更好的方法是配套变量说明表。
主数据用统一编码,说明表补充含义。这样既利于录入,也利于统计合并。这也是数据格式标准的重要组成部分。
5.2 多选题不能用字符串拼接
如饮食习惯这类多选题,如果把选项写成123、235、78,计算机很难处理。
知识库建议使用多重二分类法,也就是把每个选项拆成独立变量,选中记1,未选记0。
这种方法虽然变量数更多,但每个变量只表达一个信息。
对于医学研究,这种结构更稳定,也更利于建模、描述和回归分析。
5.3 分组变量不要拆成多个表
实验组和对照组最好放在同一张表里。
如果分散在多个表中,后期合并容易失败,尤其在跨表分析时更容易出现字段不一致。
建议在同一张表中增加分组变量。
例如用0表示手术组,1表示对照组。这样既满足数据格式标准,也方便后续统计比较。
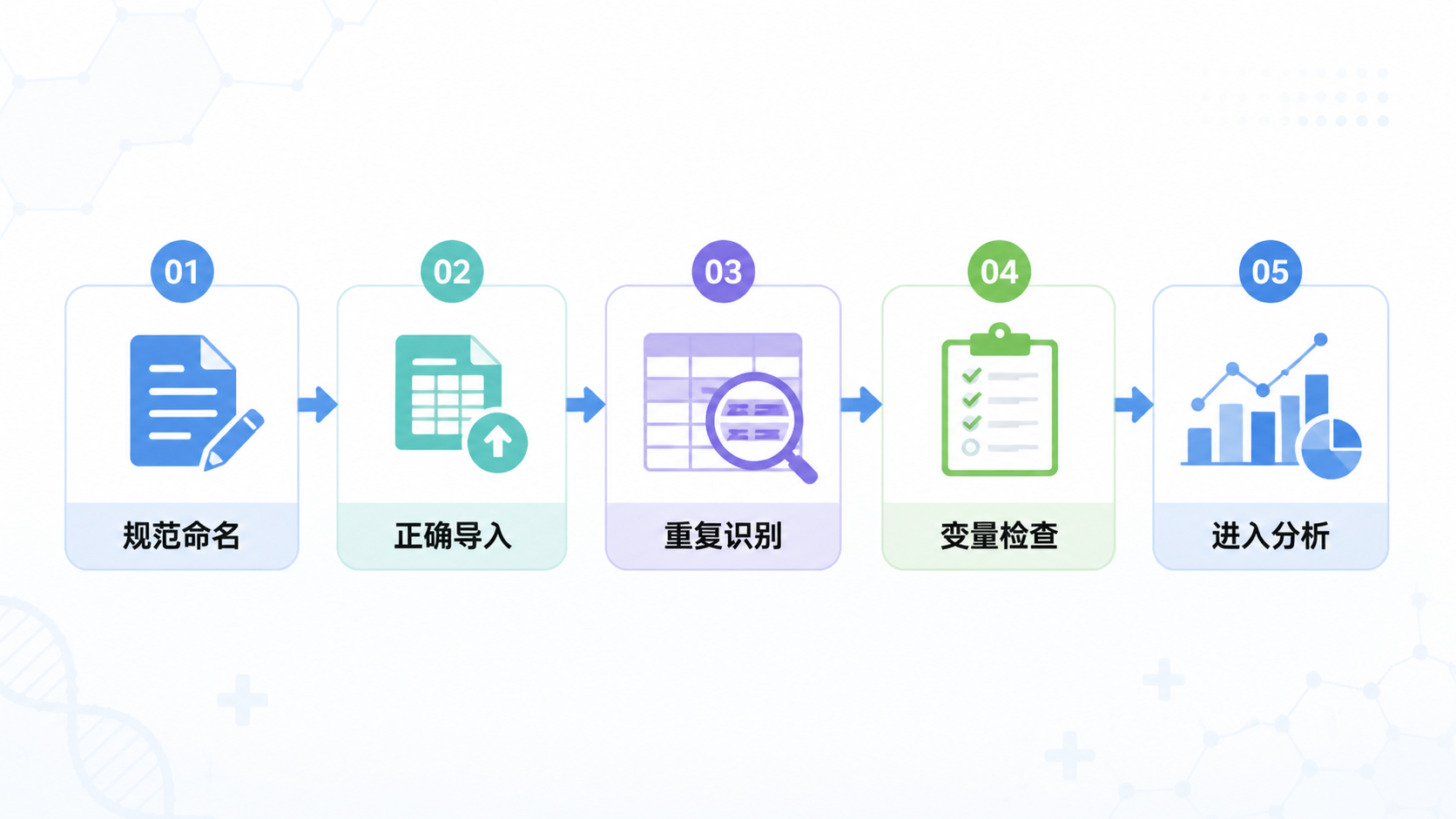
6. 临床研究中如何快速建立可分析的数据表?
6.1 先统一规则,再开始录入
规范的数据表,通常先定字段名,再定编码,再定变量类型,最后再录入。
这个顺序不能反。先录再改,往往会增加返工成本。
建议在正式录入前先完成三件事:
- 明确每一列代表什么。
- 明确每个变量的取值规则。
- 明确缺失值、重复值和异常值的处理原则。
这一步做得越早,后面越省时间。
6.2 用预览窗口做第一轮质控
无论是SPSS还是其他软件,导入时的预览窗口都非常重要。
它能快速告诉你,表头、分隔符、变量类型是否正确。
如果预览都不对,说明数据格式标准还没建立好。
不要急着完成导入。先检查,再确认,再继续下一步。
6.3 导入后立即检查重复和类型
导入完成后,不要直接进入统计分析。
先看变量视图,再查重复个案,再确认是否存在异常编码。
这三个动作可以显著降低后续错误率。
对于研究生、临床医生和科研人员来说,养成这套习惯,比单纯会跑模型更重要。
因为高质量分析,始于高质量数据。
总结Conclusion
数据格式标准不是形式问题,而是临床研究能否顺利分析的基础。
从表头、变量命名、分隔符,到变量类型、重复个案和编码方式,每一步都决定了数据是否可读、可分析、可复用。
如果你正在处理临床数据,建议把规范流程前置。先统一表结构,再完成导入和清洗。
借助解螺旋品牌的临床研究工具和规范化方法,可以更高效地完成数据整理、格式检查和基础质控,减少返工,提升分析效率。
- 引言Introduction
- 1. 为什么数据格式标准是分析前提?
- 2. 变量命名为什么不能随意?
- 3. 导入数据时最容易出错的3个环节是什么?
- 4. 重复个案为什么必须先清理?
- 5. 规范数据整理时,最该注意哪些细节?
- 6. 临床研究中如何快速建立可分析的数据表?
- 总结Conclusion