引言Introduction
david数据库 是做GO、KEGG富集分析和ID转换时常用的工具。很多医学生和科研人员卡在第一步,不知道怎么上传基因列表、选物种、选分析类型。本文用3步拆解,让你快速完成一次标准分析。
1. 认识david数据库的核心用途
1.1 它能解决什么问题
david数据库 全称是 The Database for Annotation, Visualization and Integrated Discovery。它的核心价值,是把基因列表映射到生物学注释条目,再做统计富集分析。
常见用途主要有三类。
- GO富集分析。
- KEGG通路分析。
- 基因ID转换。
对于差异基因、候选基因集、家族基因列表,david数据库 都适合做初筛和功能归类。它特别适合“拿到一串基因后,不知道它们在生物学上意味着什么”的场景。
1.2 使用前先明确输入类型
上传前最重要的一点,是先确认你的基因ID类型。
如果输入的是基因符号,就要在Step2选择 OFFICIAL_GENE_SYMBOL 。
如果是芯片探针,则应按平台选择对应ID类型,比如 Affymetrix 或 Agilent 相关ID。
ID类型选错,是最常见的失败原因之一。
它会导致匹配失败、结果缺失,甚至富集不到有效条目。
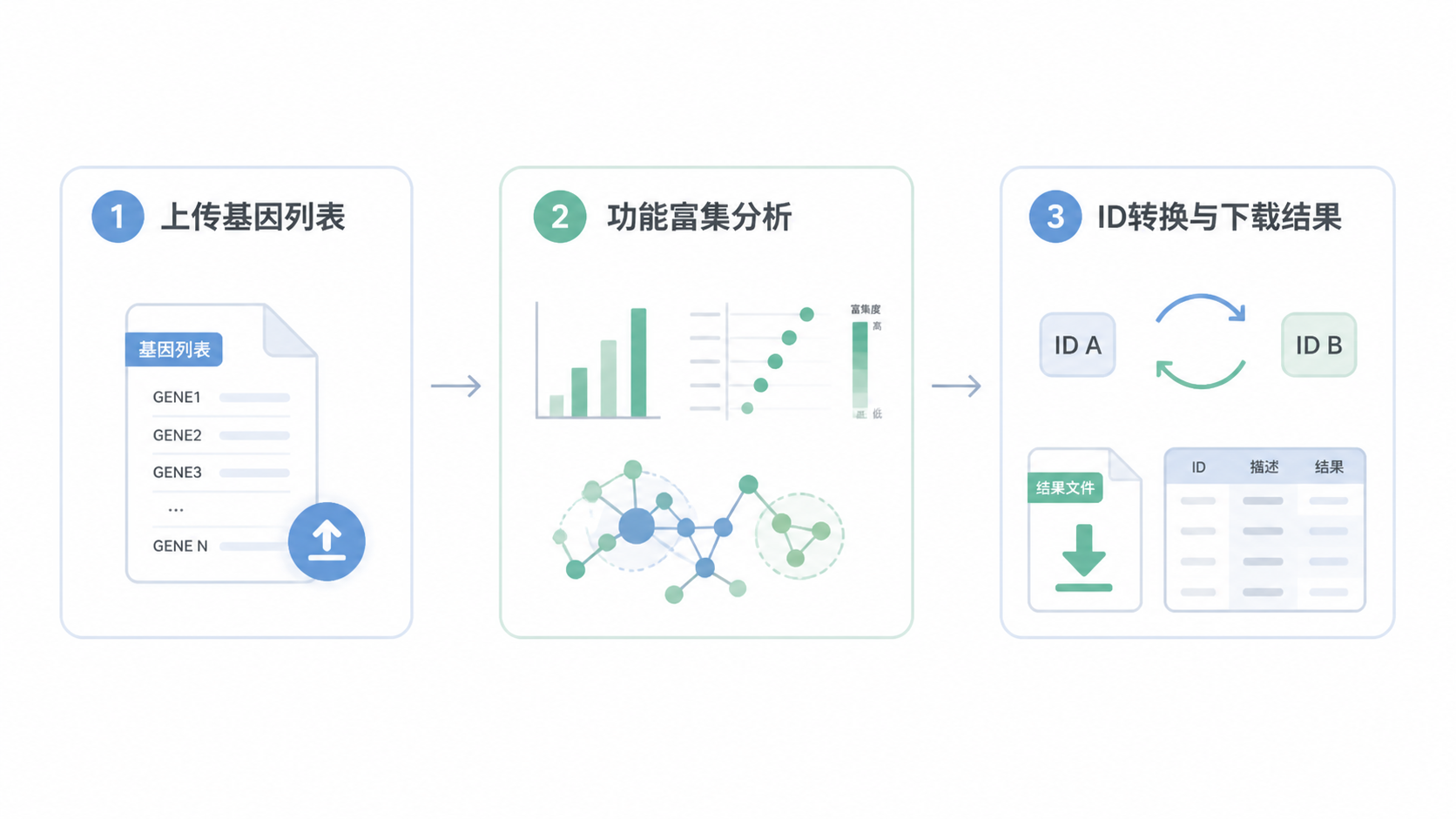
2. 第一步,上传基因列表并完成基础设置
2.1 进入分析页面
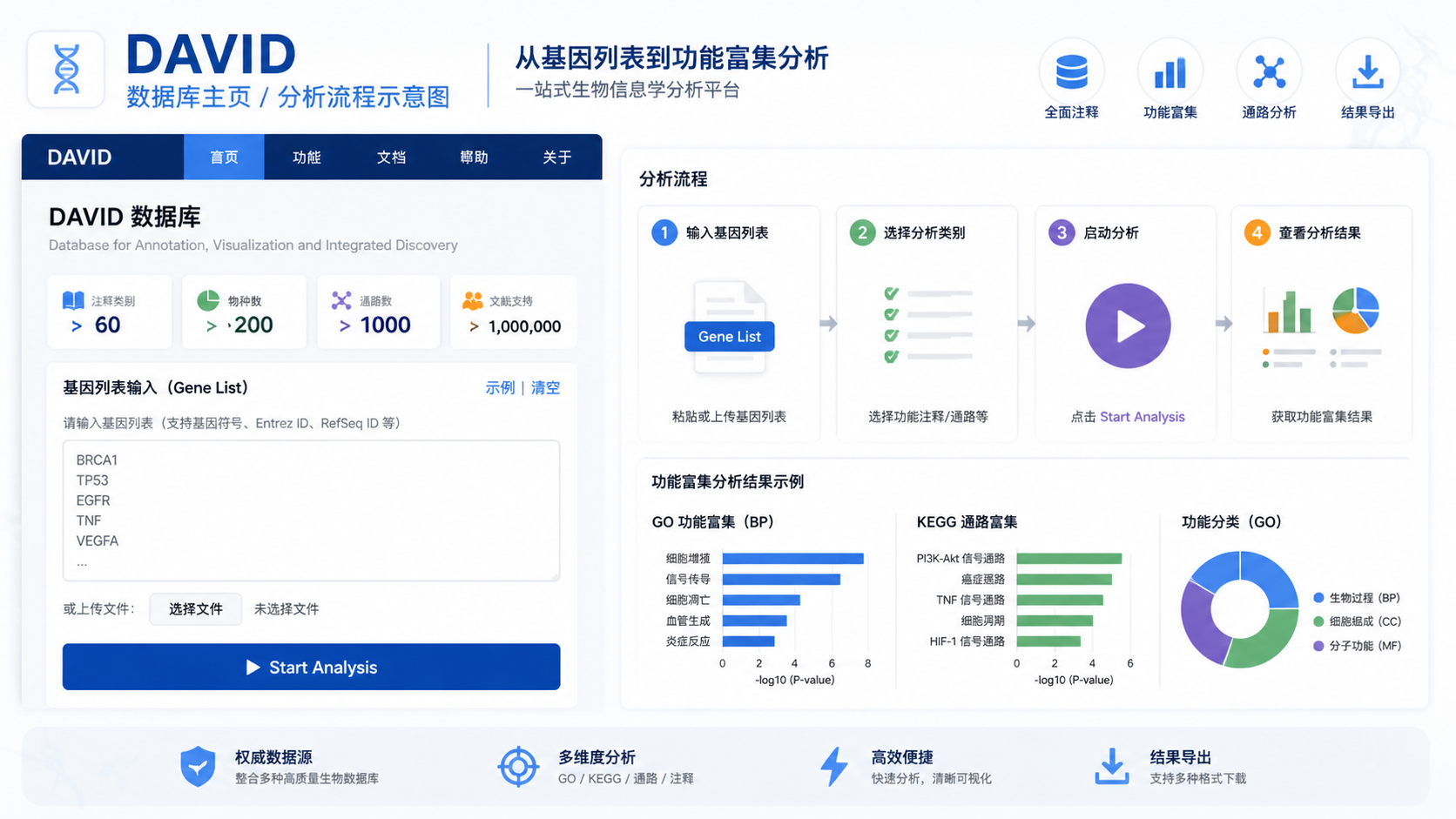
打开浏览器,输入 DAVID 官方网址。进入主页后,点击 Start Analysis 。这一步会进入数据上传页面,也是整个流程的起点。
在上传页面,你可以选择两种方式输入基因列表。
- 直接复制粘贴。
- 上传文本文件。
需要注意,文件应为制表符分隔文本。并且,DAVID默认只识别第一列数据。每行建议只放一个基因或蛋白名称。如果是复制粘贴输入,也不要只输入单个基因,因为这类输入很难得到有意义的富集结果。
2.2 设置物种和用途
在Step1输入你的基因列表后,进入Step2选择ID类型。随后在Step2a选择物种。
如果分析人类基因,可直接输入 Homo sapiens 或 ** 9606**,下方会自动出现候选项,选择 human 即可。
接着在Step3选择用途。
- 做GO/KEGG富集,选 Gene List 。
- 作为背景基因集,选 Background 。
如果你的目标是功能分析,绝大多数情况下都应选择 Gene List。
2.3 提交后先核对再继续
完成设置后,点击 Submit List 。页面刷新后会进入上传列表查看页面。此时先检查三件事。
- 物种是否正确。
- 基因列表是否完整。
- Step1是否显示已成功提交。
确认无误后,选中对应的列表,例如 List_1,点击 Use 。然后在Background处再次确认物种信息,最后点击 Use 。
这一步看似简单,但它决定后续分析是否基于正确的数据基础。
3. 第二步,进行GO/KEGG富集分析
3.1 打开功能注释工具
在列表确认页面,点击右侧 Functional Annotation Tool ,即可进入富集分析界面。进入后,DAVID会默认勾选部分分析项。正式分析前,建议先取消默认勾选,或直接点击 Clear All 。
这一步很关键。
因为默认选项不一定等于你真正想要的分析集合。对于论文和汇报,最好只保留你需要的条目。
3.2 勾选GO和KEGG分析项
如果你的目标是标准GO/KEGG分析,需要勾选以下内容。
- Gene_Ontology 下的 GOTERM_BP_DIRECT 。
- GOTERM_CC_DIRECT 。
- GOTERM_MF_DIRECT 。
- Pathways 下的 KEGG_PATHWAY 。
勾选后,点击 Functional Annotation Chart 。系统会输出富集结果表。
结果表里最值得关注的参数有这些。
- 条目名称。
- 命中基因数。
- 命中比例。
- EASE分数,也就是改良后的 Fisher 精确检验 p 值。
- Benjamini校正后的 p 值。
通常优先关注校正后的显著性,而不是只看原始p值。
这对多重比较尤其重要。
3.3 如何读懂结果表
DAVID返回的表格可以帮助你快速判断基因集的功能倾向。比如某一通路里命中基因较多,且校正后p值显著,就说明该通路可能与输入基因集高度相关。
你还可以进一步查看。
- 每个富集条目包含哪些基因。
- 富集条目的来源。
- 是否还能继续查看相关条目。
如果你需要发表级别作图,建议把结果下载后再用 Excel、GraphPad Prism 或 R 进行整理和可视化。DAVID负责发现富集信号,后续软件负责完成规范化展示。
4. 第三步,做ID转换并导出结果
4.1 什么时候需要ID转换
很多数据来源不统一。RNA-seq结果可能是gene symbol,芯片数据可能是探针ID,蛋白组又可能是不同命名体系。
这时就需要用 david数据库 的 Gene ID Conversion Tool 先统一ID。
在列表上传成功后,点击右侧 Gene ID Conversion Tool 。系统默认会尝试转换为 ENTREZ_GENE_ID 。你也可以按研究需要选择其他类型。
然后再次确认物种,点击 Submit to Conversion Tool 。
4.2 重点看哪些转换信息
转换结果页会显示多个关键信息。
- 输入ID总数。
- 是否被DAVID收录。
- 转换是否成功。
- 是否存在模糊匹配。
- 转换后的ID。
- DAVID收录的基因名称。
如果显示 Successful ,说明转换成功。
如果是 Pending ,表示匹配结果不够明确,需要进一步确认ID类型。
如果是 None ,则说明该ID没有成功映射。
对于批量分析,先统一ID再做富集,是最稳妥的流程。
这能减少因命名不一致带来的漏检。
4.3 下载并保存结果
在结果页点击 Download Files ,右键选择链接另存为,即可把结果保存为文本文件。
下载后用 Excel 打开,可以直接看到转换前后ID、物种信息,以及DAVID数据库收录名称。
这一步适合做两类工作。
- 备份分析过程。
- 方便后续复核和制图。
5. 实操建议,提升david数据库分析可靠性
5.1 先检查输入质量
david数据库 对输入质量很敏感。建议在上传前先统一命名规则,去掉重复项,并确认物种一致。
如果是人类数据,就不要混入其他物种基因。
如果是家族基因分析,例如CASP家族,先确认列表完整,再上传。
5.2 富集分析要控制阈值
DAVID允许调整富集阈值和显示参数。分析时不要只追求“结果多”,而要追求“结果稳”。
建议重点看以下几类结果。
- 经过多重校正后仍显著的条目。
- 与研究主题高度相关的通路。
- 命中基因较集中、逻辑链条清晰的条目。
显著不等于有生物学意义,必须结合课题背景解释。
5.3 结果展示要回到研究问题
如果你是做机制研究,GO可帮助你概括功能方向。
如果你是做通路研究,KEGG更适合讲清信号轴。
如果你是做转化或临床关联,建议把富集结果和表型、分组信息结合分析。
david数据库的价值,不只是出结果,而是帮助你形成可解释的研究假设。
总结Conclusion
david数据库 的上手逻辑很清晰。先上传基因列表,再做GO/KEGG富集,最后按需完成ID转换和结果导出。只要把ID类型、物种和分析用途选对,大多数常规分析都能快速完成。
如果你希望把 DAVID 分析流程做得更高效、更规范,建议结合 解螺旋 的数据库与科研工具内容,进一步提升数据整理、富集解读和结果展示效率。对于医学生、医生和科研人员来说,这会直接节省重复试错时间。
下一步,就从一次规范的 dvid数据库分析开始。
- 引言Introduction
- 1. 认识david数据库的核心用途
- 2. 第一步,上传基因列表并完成基础设置
- 3. 第二步,进行GO/KEGG富集分析
- 4. 第三步,做ID转换并导出结果
- 5. 实操建议,提升david数据库分析可靠性
- 总结Conclusion