引言Introduction
在病例对照研究、横断面分析和Logistic回归中,比值比 OR 几乎是最常见的效应量。很多医学生和科研人员会卡在同一个问题上:OR到底代表什么,何时能解释为风险,何时不能。把OR读错,结论就会偏。
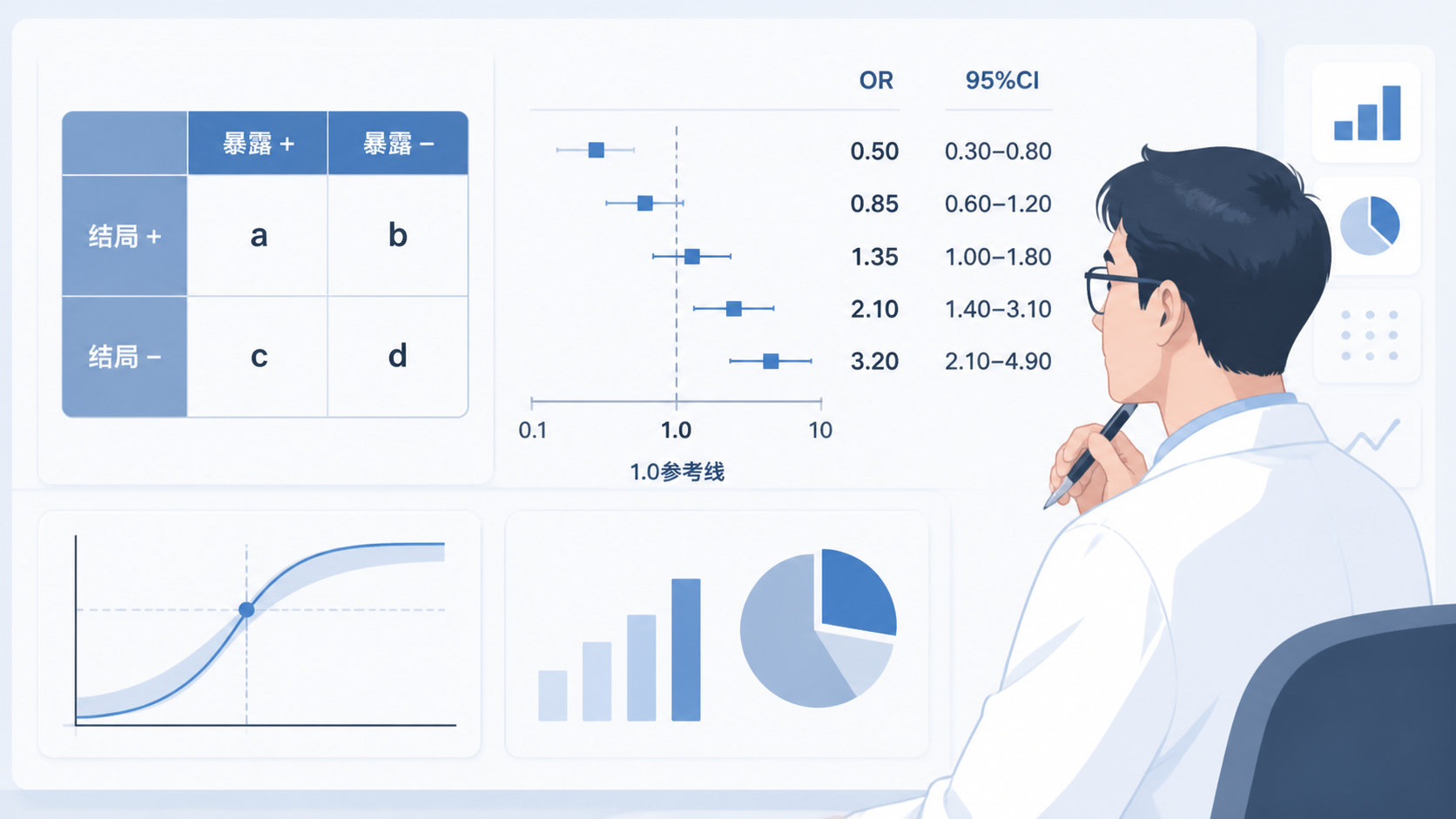
1. 为什么比值比 OR 是病例对照研究的核心指标
1.1 病例对照研究为什么不能直接用RR
病例对照研究是先按结局分组,再回溯暴露。此时通常没有暴露组和非暴露组的完整观察人数,不能直接计算发病率,也就不能直接计算RR。
这时就需要比值比 OR。它描述的是病例组与对照组中,暴露“比值”的比值。
1.2 OR的统计学定义
OR = 病例组暴露比值 ÷ 对照组暴露比值。
在四格表中,OR也可写成交叉乘积比,即 ad / bc 。
这里的“比值”不是比例,而是“发生 / 不发生”的比。这个定义非常关键。它决定了OR不能被简单读成“暴露率之比”。
1.3 为什么OR近似RR
在病例对照研究中,OR常被用来近似估计RR。对于医学论文阅读和结果报告来说,它是最标准的关联强度指标之一。
当OR=1,表示暴露与结局无关联。 这就是OR的无效值。很多后续解释,都从这里开始。
2. 比值比 OR 的第一个重要场景:判断暴露是否是危险因素
2.1 OR大于1意味着什么
在以“疾病发生”为结局的研究里,OR>1通常提示暴露与结局正相关。
也就是说,暴露者发生结局的可能性更高。此时暴露可被视为危险因素。
例如,口服避孕药与心肌梗死的病例对照研究中,病例组暴露率为25.5%,对照组为13.5%,计算得到 OR=2.2 。这表示,暴露者发生心肌梗死的可能性,是未暴露者的2.2倍。
2.2 解释OR时必须先看结局
OR的方向,取决于你把什么定义为“病例”。
如果病例是疾病结局,OR>1常提示危险因素。
但如果病例定义成“疗效好”这类正向结局,OR>1反而可能表示保护因素。
这是很多初学者最容易错的地方。先看结局,再谈OR。 不先确认分组依据,解释就可能完全相反。
2.3 读文献时要避免把OR当成绝对风险
OR不是发病率,也不是绝对危险。
它反映的是两组“比值”的相对关系。
当结局发生率不低时,OR会比RR更“夸张”。因此在论文讨论中,不能把OR直接写成“风险增加了多少百分比”,除非语境非常清楚。
3. 比值比 OR 的第二个重要场景:识别保护因素
3.1 OR小于1意味着什么
OR<1通常提示负相关。
在疾病结局研究中,它常被解释为保护因素。
例如,某暴露组的OR=0.4,说明暴露者发生结局的可能性更低。
但这句话仍然要依赖结局定义。
如果你的病例是“疗效好”,那么OR<1未必是坏结果。方向性解释必须和研究结局一致。
3.2 不要只看大小,还要看参照组
OR的解释永远离不开参照组。
在Logistic回归中,输出的OR通常是“某一类别相对于参考组”的结果。
比如“曾经吸烟”相对于“从不吸烟”的OR=2.36,含义是:曾经吸烟者发生结局的可能性,是从不吸烟者的2.36倍。
3.3 临床研究中最常见的误区
很多文章只写“OR=0.8”,却不说明参照组和结局方向。
这样的结果几乎无法解读。
没有参照组,OR没有临床意义。
4. 比值比 OR 的第三个重要场景:判断统计学意义
4.1 95%CI是否包含1,比OR本身更重要
OR后面通常会跟95%置信区间。
如果95%CI不包括1,结果通常提示有统计学意义。
如果95%CI包含1,则说明该OR可能只是抽样误差造成,关联不稳定。
例如,OR=1.6,95%CI为1.2到2.0,不包含1,提示有统计学意义。
再如,OR=0.8,95%CI为0.7到1.2,包含1,则不能直接下结论说有保护作用。
4.2 为什么1是关键值
因为OR=1代表暴露与非暴露的结局比值相同。
也就是说,两组没有可检测的关联差异。
这也是为什么在论文写作和审稿中,OR的解释必须和95%CI一起出现。
4.3 只报OR不报CI是不完整的
在临床研究中,单独一个OR数值信息有限。
它只能告诉你效应方向和强度。
95%CI则告诉你这个结果稳不稳定。
对于科研人员来说,二者必须一起读。
5. 比值比 OR 的第四个重要场景:Logistic回归建模
5.1 OR是Logistic回归最常见的输出
在分析性横断面研究和很多病因学研究中,结局变量是二分类变量。
这时常用Logistic回归。
模型的核心结果通常就是OR。
在这个框架下,OR可近似理解为:自变量每变化一个单位,结局发生比值改变多少倍。
如果自变量是二分类变量,比如“有无高血压”,那解释会更直接。
5.2 分类变量一定要设置参照组
这是Logistic回归里最容易忽略的问题。
如果变量本质上是分类变量,却没有正确设定参考组,软件可能按连续变量处理。这样输出的OR就会失真。
分类变量、参照组、结局方向,三者必须同时确认。
5.3 多因素模型里的OR更接近真实关联
单因素OR容易受混杂影响。
多因素Logistic回归可以调整年龄、性别、吸烟、基础病等混杂因素。
这时得到的是调整后的OR,更适合用于论文主结果描述。
它不是“简单比一下”,而是“在控制其他变量后”的关联强度估计。
6. 比值比 OR 的第五个重要场景:分层分析与混杂控制
6.1 OR可用于看不同亚组的效应差异
病例对照研究不只是算一个总OR。
还可以做分层分析。
比如按性别、年龄、是否吸烟分层,观察OR是否变化。
如果各层OR相近,提示关联较稳定。
如果某一层OR明显改变,就要考虑效应修饰或混杂偏倚。
6.2 OR帮助研究者识别偏倚
病例对照研究最怕混杂。
比如口服避孕药与心肌梗死的关联,可能受到年龄、吸烟、血脂等因素影响。
通过分层分析或多因素分析,OR可以帮助控制这类偏倚。
这也是OR在方法学上的价值,不只是结果数字。
6.3 论文讨论中要写清楚“调整前后”
如果文章同时报告粗OR和调整后OR,审稿人通常会先看调整后结果。
因为它更接近独立关联。
调整前后差异明显时,说明混杂影响不能忽略。
7. 比值比 OR 的第六个重要场景:论文解读与写作规范
7.1 OR要写完整
标准写法至少包括三部分。
- OR值。
- 95%CI。
- P值或统计学判断。
例如,OR=2.20,95%CI 1.25-3.75。 这种写法比单写“OR=2.2”更符合论文规范。
7.2 解读时要回到研究问题
如果你的研究问题是“暴露是否增加疾病风险”,OR>1通常意味着危险因素。
如果你的研究问题是“某干预是否改善结局”,OR>1可能意味着治疗获益。
OR本身没有褒贬,关键在结局定义。
7.3 最后再看临床意义
统计学显著,不等于临床上重要。
一个OR虽然显著,但如果绝对风险变化很小,临床价值可能有限。
所以论文里最好同时考虑效应量、CI范围、样本来源和临床背景。
这才符合E-E-A-T要求下的严谨解读。
总结Conclusion
比值比 OR 之所以重要,是因为它几乎贯穿病例对照研究、分析性横断面研究和Logistic回归。 它能帮助研究者判断关联方向、比较效应强度、识别混杂,并通过95%CI判断结果是否稳定。
如果你正在写临床研究、读文献或做统计分析,建议把OR的解释建立在三个前提上。先看结局,再看参照组,最后看95%CI。 这样才能避免把OR读反、读偏、读漏。
如果你希望把病例对照研究、Logistic回归和OR解读做成更高效的科研写作流程,可以进一步使用解螺旋品牌 的临床研究学习与内容支持工具,帮助你更快完成文献解读、结果表述和论文表达。
- 引言Introduction
- 1. 为什么比值比 OR 是病例对照研究的核心指标
- 2. 比值比 OR 的第一个重要场景:判断暴露是否是危险因素
- 3. 比值比 OR 的第二个重要场景:识别保护因素
- 4. 比值比 OR 的第三个重要场景:判断统计学意义
- 5. 比值比 OR 的第四个重要场景:Logistic回归建模
- 6. 比值比 OR 的第五个重要场景:分层分析与混杂控制
- 7. 比值比 OR 的第六个重要场景:论文解读与写作规范
- 总结Conclusion