





引言Introduction
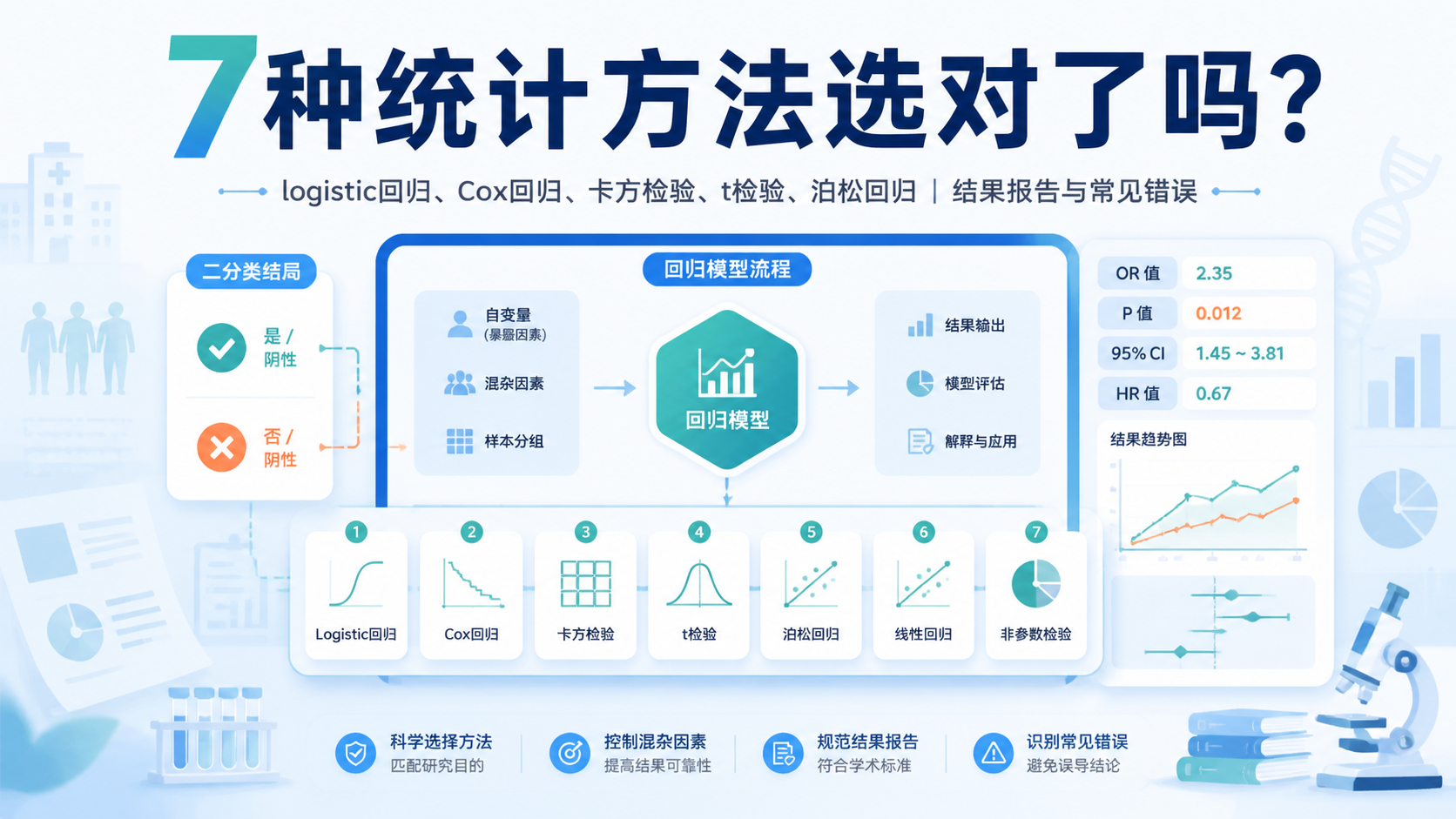
病例对照研究统计方法怎么选,是很多医学生和科研人员最常遇到的难题。变量多、混杂因素多、结果又常是二分类,若方法选错,OR值和结论都可能失真。本文按数据类型和研究目的,系统梳理病例对照研究统计方法的7种常用方案。
1. 先判断研究数据类型,再选方法
1.1 结局是二分类,优先考虑logistic回归
在病例对照研究中,结局变量通常是二分类变量,比如“有病”与“无病”。这种情况下,logistic回归是最常用的病例对照研究统计方法之一 。它适合分析暴露因素与结局之间的关联,并可同时纳入多个协变量。
单因素分析可先筛选变量。随后再进入多因素模型,控制年龄、性别、合并症等混杂因素。结果通常报告OR值、95%置信区间和P值。
1.2 先看分布,再看变量属性
如果自变量是连续型,先判断是否近似正态分布。正态分布可用均数、标准差和t检验。偏态分布可用中位数、四分位数和非参数检验。
如果自变量是分类变量,如性别、吸烟史、分层暴露史,则常用卡方检验或确切概率法。
病例对照研究统计方法不是先套模型,而是先识别数据类型。 这一步决定后续分析是否合理。
2. 7种常用统计方案
2.1 方案一,卡方检验
当你只想比较病例组和对照组某个分类变量的构成差异时,卡方检验最直接。它适用于样本量较大、理论频数满足条件的场景。
例如比较两组吸烟率、家族史比例、药物暴露率。若频数过小,则要考虑确切概率法。卡方检验适合做初步筛查,但不能替代多因素分析 。
2.2 方案二,t检验或秩和检验
如果比较的是连续变量,比如年龄、BMI、实验室指标,可用t检验或秩和检验。
- 正态分布且方差齐,优先用t检验。
- 偏态分布或等级资料,优先用秩和检验。
这类分析常用于基线描述,也用于判断病例组和对照组是否可比。
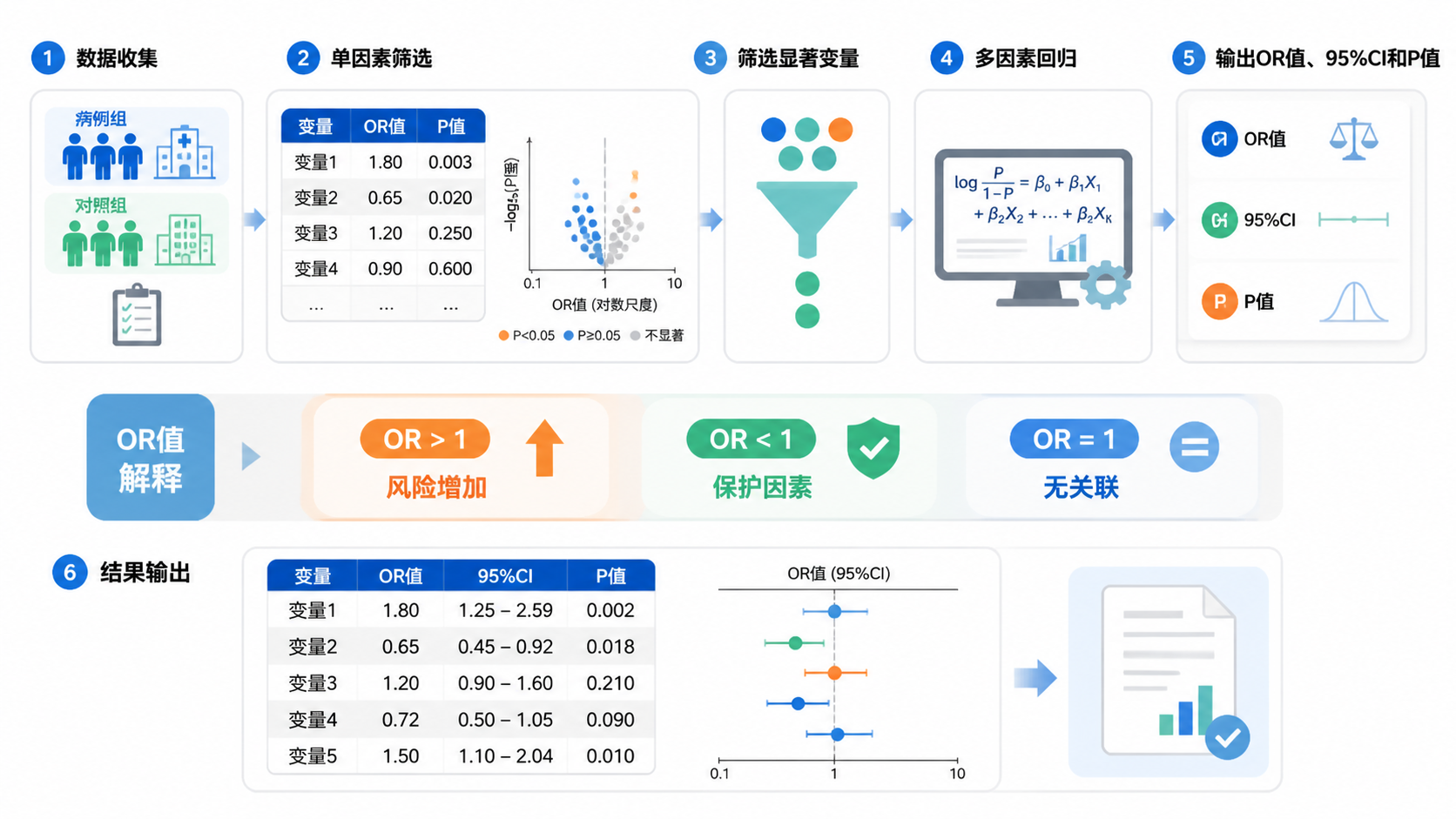
2.3 方案三,单因素logistic回归
单因素logistic回归是病例对照研究统计方法中的基础步骤。 它可以计算某个暴露因素与疾病结局之间的粗OR值。
这一步的意义在于快速识别候选因素,而不是最终定论。
在实际论文中,常先把单因素分析中P值小于0.05的变量纳入多因素模型。但这不是绝对规则。若变量有明确临床意义,即使P值不显著,也可考虑保留。
2.4 方案四,多因素logistic回归
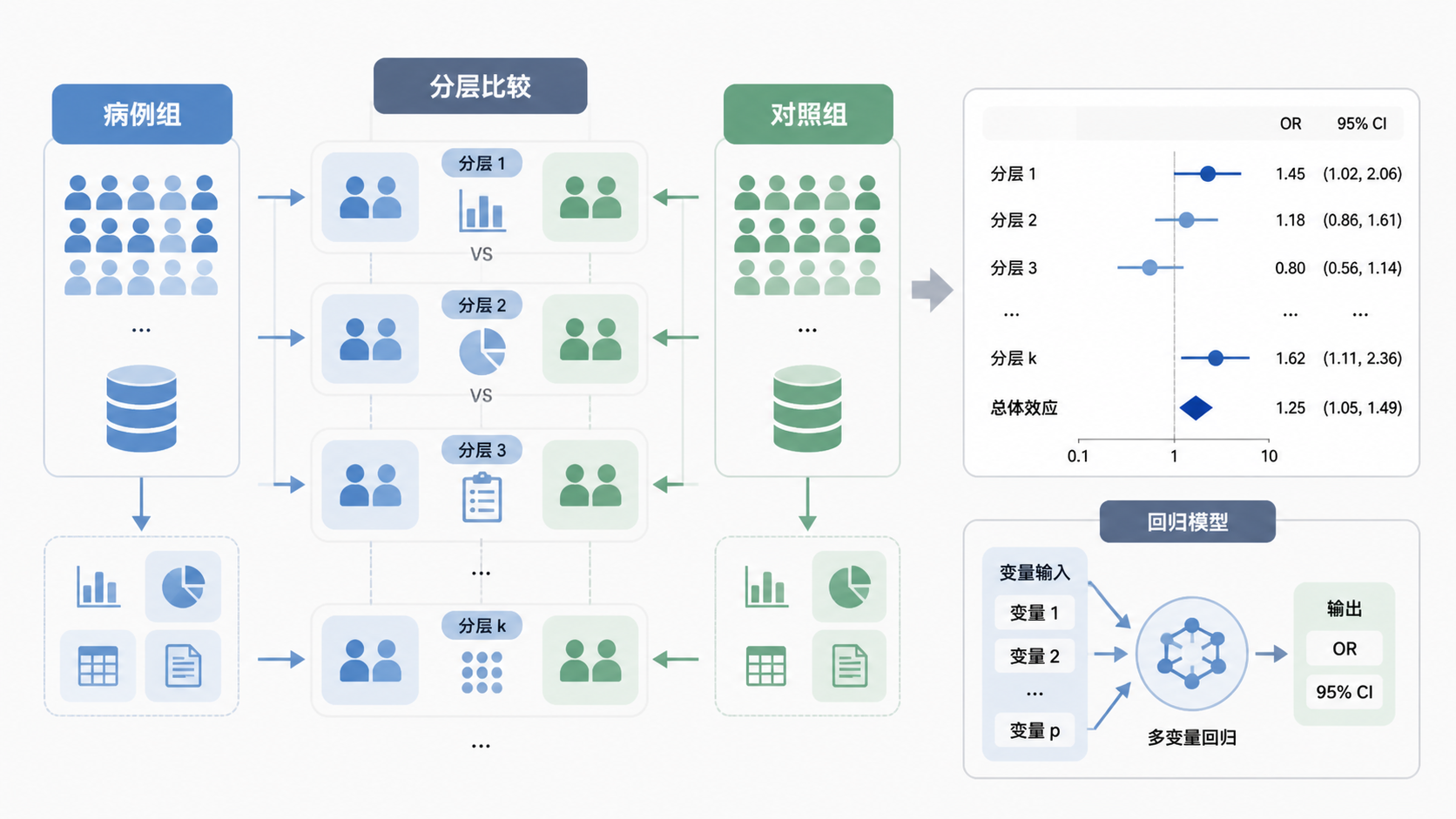
当研究中存在多个混杂因素时,必须用多因素logistic回归。它能同时校正多个变量,得到调整后的OR值。
这是病例对照研究最核心的统计方法之一。
多因素模型的价值,不只是“显著性”,而是“控制混杂后暴露与结局的真实关系”。 报告时建议写清楚回归系数、OR值、95%CI和P值。若变量很多,需注意共线性问题。
2.5 方案五,条件logistic回归
如果病例和对照做了个体匹配,比如按年龄、性别、医院来源匹配,就不能直接用普通logistic回归。此时更适合用条件logistic回归。
这种方法常见于配对病例对照研究。它能保留匹配设计的优势,避免错误估计效应值。一旦研究设计用了匹配,统计分析也要匹配。 这是很多初学者最容易忽略的点。
2.6 方案六,泊松回归或广义线性模型
在部分研究中,若结局事件较少,或研究者希望直接建模发生率,可考虑泊松回归或广义线性模型。知识库中提到,结局为计数资料时也可使用泊松回归、负二项回归和零膨胀模型。
不过从病例对照研究的常规实践看,logistic回归仍是主流。 泊松回归更常见于队列研究或计数型结局分析。只有在研究设计和数据结构匹配时才建议使用。
2.7 方案七,生存分析中的Cox回归
如果病例对照研究延伸到随访结局,且结局不仅是“是否发生”,还涉及“发生时间”,则要考虑Cox回归。
Cox回归用于生存资料分析,核心输出是HR值。它适合处理时间变量,能够分析暴露因素对事件发生风险的影响。
当结局带有时间维度时,病例对照研究统计方法就不能只盯着OR值。 此时应根据研究问题切换到生存分析框架。
3. 结果怎么报告才规范
3.1 先看P值,再看效应量
统计分析时,先看P值是否小于0.05,再看效应量和置信区间。
如果P值大于0.05,说明模型或变量在统计学上不显著。
如果P值小于0.05,还要继续判断临床意义,而不能只看“显著”二字。
真正有价值的病例对照研究统计方法报告,不是只写P值,而是同时给出OR值和95%CI。
3.2 OR值要结合方向解释
OR值等于1,说明暴露与结局无关联。
OR值大于1,提示暴露可能增加结局发生概率。
OR值小于1,提示暴露可能具有保护作用。
但前提是变量编码和结局定义要正确。若结局是不良事件,且暴露编码方向明确,OR值才可按危险因素或保护因素解释。否则容易误判。
4. 设计阶段先控混杂,分析阶段再校正
4.1 限制和配对是设计层面的控制
观察性研究没有随机分组,因此混杂控制非常关键。设计阶段常用限制和配对。
限制是通过纳入排除标准缩小研究对象差异。
配对是让病例组和对照组在某些关键变量上保持一致。
这一步决定后续分析是否省力,也影响模型稳定性。
4.2 分层分析和多因素分析是分析层面的主力
在统计分析阶段,最常用的是分层分析和多因素分析。分层分析可以看不同亚组中的效应差异。多因素分析则用于校正协变量。
如果不控制混杂,病例对照研究统计方法再“高级”,结论也可能偏。
5. 常见错误,很多人都会犯
5.1 只做单因素,不做多因素
这是最常见的问题。单因素只能看粗关联,不能处理混杂。只要研究因素超过1个,就应考虑多因素模型。
5.2 匹配了,却用了错误模型
匹配病例对照研究若仍用普通logistic回归,可能低估或高估效应。应根据设计选择条件logistic回归。
5.3 只报P值,不报CI
P值只能说明统计学意义。95%CI更能体现估计的不确定性和临床解释价值。 论文投稿时,这一点非常重要。
6. 论文写作中如何落地
6.1 方法部分要写清楚
建议方法部分明确写出:
- 研究设计类型。
- 病例和对照的选择方式。
- 变量类型和统计检验方法。
- 是否进行了匹配。
- 是否使用单因素和多因素回归。
- 效应量指标是OR值还是HR值。
6.2 结果部分要结构化呈现
结果部分建议按顺序写:
- 基线特征描述。
- 组间差异比较。
- 单因素分析。
- 多因素分析。
- 效应量、95%CI、P值。
这种写法最符合审稿人阅读习惯,也最利于体现病例对照研究统计方法的规范性。
总结Conclusion
病例对照研究统计方法的选择,核心不是“哪个最强”,而是“哪个最匹配数据和设计”。二分类结局优先考虑logistic回归,匹配设计用条件logistic回归,时间结局再考虑Cox回归。分类变量用卡方检验,连续变量用t检验或秩和检验,复杂结局可结合广义线性模型。
如果你正在整理病例对照研究的统计方案,建议用解螺旋的研究设计与论文写作框架,把变量筛选、混杂控制、模型选择和结果报告一次做规范。
- 引言Introduction
- 1. 先判断研究数据类型,再选方法
- 2. 7种常用统计方案
- 3. 结果怎么报告才规范
- 4. 设计阶段先控混杂,分析阶段再校正
- 5. 常见错误,很多人都会犯
- 6. 论文写作中如何落地
- 总结Conclusion



