引言Introduction
病例对照研究变量选择,是很多医学生和科研人员最容易踩坑的环节。病例和对照怎么选,暴露怎么测,混杂怎么控,任何一步偏了,结果都可能失真。想把病例对照研究做扎实,关键不是变量越多越好,而是选对变量。
1. 先搞清病例对照研究变量选择的核心逻辑
1.1 变量不是越多越好,而是要服务研究问题
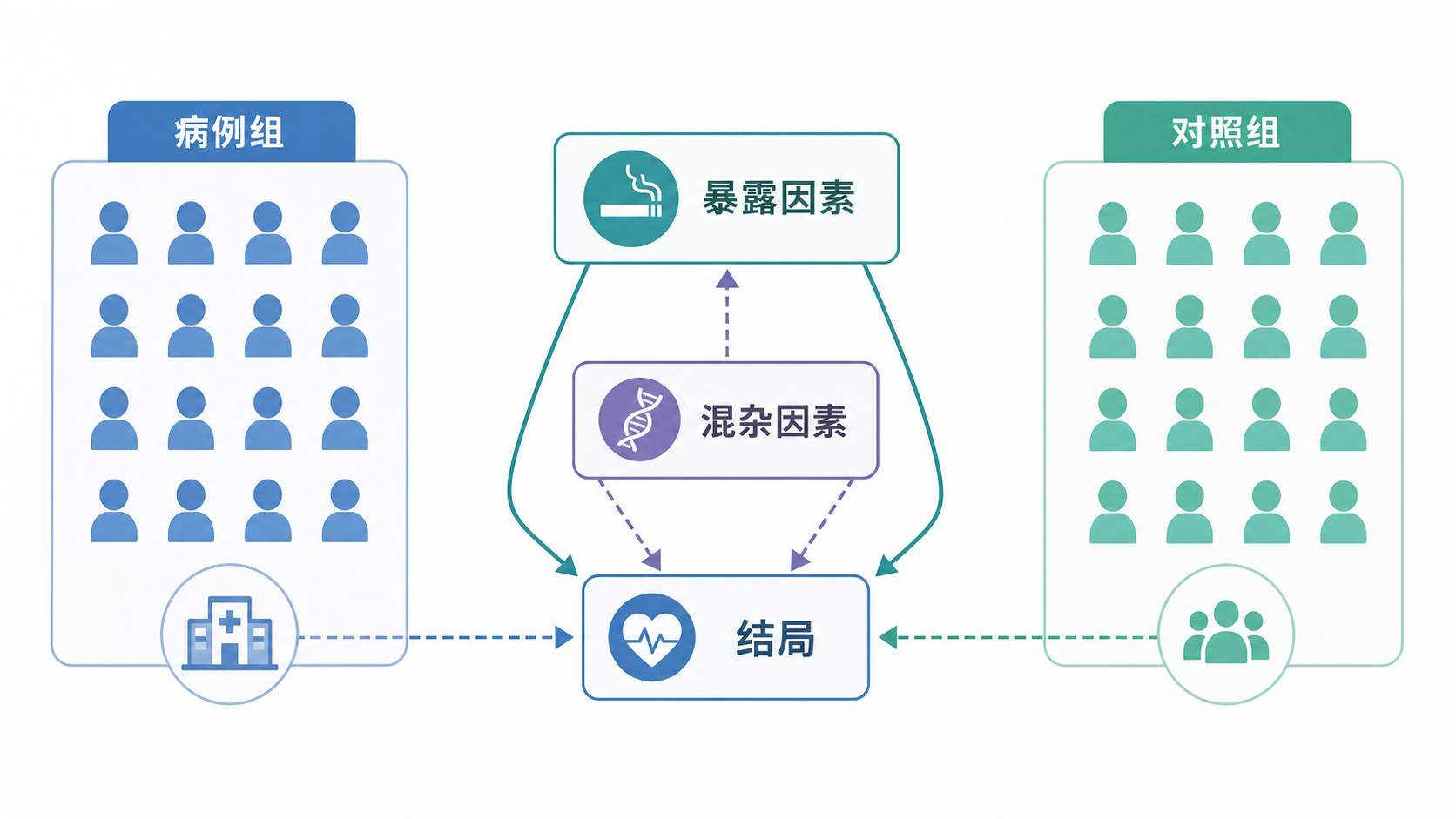
病例对照研究是由果溯因。先按结局分组,再回顾既往暴露史。因此,变量选择的第一原则是围绕研究假说展开。如果研究目的是验证某个危险因素,变量就要优先覆盖暴露、结局和主要混杂因素。
在上游知识库中,病例对照研究的核心要素包括病例选择、对照选择、暴露测量和混杂控制。变量选择本质上就是为这四个环节服务。比如研究NSAID与结肠癌风险,NSAID就是核心暴露变量,年龄、性别、基础疾病、住院原因等,则可能影响暴露分布和结局判断。
1.2 先分清三类变量
病例对照研究变量选择时,建议先按功能分类,而不是一开始就堆变量名。常见可分为三类。
- 结局变量。用于定义病例和对照。
- 暴露变量。用于检验病因假设。
- 混杂变量。用于校正偏倚,避免关联被高估或低估。
混杂变量是否纳入,不取决于“统计上显著不显著”,而取决于它是否同时影响暴露和结局。 这也是病例对照研究变量选择最常见的误区之一。
1.3 变量选择错误会直接歪曲效应值
知识库中提到,对照组选择若与暴露有关,会显著影响暴露和结局之间的关联。变量选择同样如此。若把与暴露密切相关、但与研究目的无关的变量纳入不当,可能造成过度匹配,掩盖真实关联。若漏掉关键混杂因素,又可能导致偏倚残留。
因此,病例对照研究变量选择不是“尽量全收集”,而是“尽量选关键变量”。这一步决定后续分析是否可靠。
2. 3步完成病例对照研究变量选择
2.1 第一步:锁定暴露变量和结局定义
第一步不是上来就列协变量,而是先把研究问题写清楚。也就是明确“谁是结局,谁是暴露”。
例如:
- 结局变量。是否患某病,是否发生某并发症。
- 暴露变量。既往药物使用史、环境暴露史、感染史、手术史等。
病例对照研究变量选择的起点,是让暴露变量具备时间先后顺序。 因为研究是回顾性的,暴露必须发生在结局之前,才有病因解释的意义。若变量本身难以确认时间先后,就容易引入回忆偏倚或逆向因果问题。
这一步还要统一诊断标准。知识库强调,病例应符合明确、统一的诊断标准,最好使用国际通用或国内统一标准,尽量采用金标准。只有结局定义稳定,变量比较才有意义。
2.2 第二步:筛选可能混杂结局判断的变量
第二步是围绕混杂因素做筛选。病例对照研究里,混杂控制非常关键。尤其在医院来源病例和对照中,若入组过程与暴露有关,很容易产生系统误差。
建议优先考虑以下几类变量:
- 基本人口学变量,如年龄、性别。
- 与就医行为相关的变量,如医院来源、科室来源。
- 与暴露和结局都相关的临床变量,如合并症、用药史、基础疾病。
- 与社会经济状态相关的变量,如受教育程度、职业、居住地区。
混杂变量选择的标准,是“是否可能同时影响暴露和结局”,而不是“看起来重要”。
如果研究的是带状疱疹与勃起功能障碍,年龄就可能是重要混杂因素,因为它既影响疾病发生,也可能影响暴露背景和就医机会。
这一步还要警惕选择偏倚。比如在研究NSAID与结肠癌时,若对照选成关节炎住院患者,对照组NSAID暴露比例会偏高,可能低估效应值。若选成消化性溃疡住院患者,暴露比例又可能偏低,可能高估效应值。这说明变量选择和对照选择必须一起考虑。
2.3 第三步:删掉无关变量,避免过度匹配
第三步是做减法。很多人做病例对照研究时,会把能收集到的变量全部纳入,结果反而让模型变差。
过度匹配有两个问题:
- 匹配变量过多,会掩盖暴露和结局之间真实差异。
- 有些变量本身可能是暴露路径上的中间环节,不适合直接控制。
因此,病例对照研究变量选择要坚持两条线:
- 保留真正可能混杂结果的变量。
- 删除与研究问题关系弱、且会增加噪音的变量。
如果一个变量既不影响暴露,也不影响结局,就没有必要纳入主要分析。
在样本量有限的情况下,变量越多,模型越不稳定。尤其病例数少时,更要优先保留高价值变量。
3. 变量选择落地时,最容易忽视的4个细节
3.1 病例和对照的变量标准必须一致
病例对照研究变量选择,不能只看病例组。病例和对照的暴露测量方式必须尽量一致,信息来源也要一致。否则会产生信息偏倚。
例如病例通过病历获取暴露史,对照却靠电话回忆,数据质量就不对等。同一变量,必须用同一标准采集。
3.2 优先选新发病例,减少回忆偏倚
知识库指出,新发病例通常优先于现患病例。原因是新发病例更能代表不同病情和预后,回忆暴露史也更接近真实。现患病例病程长,容易记忆偏差,也难区分暴露与发病先后。
这对病例对照研究变量选择很重要。如果病例类型本身有偏差,再好的变量也会被污染。
3.3 对照变量要独立于研究暴露
对照的选择必须独立于暴露因素。这个原则直接影响变量是否可比。比如研究某药物与疾病风险时,不应选择因该药物禁忌而住院的人群做对照,否则会系统性改变暴露分布。
因此,病例对照研究变量选择前,先问自己一个问题:这个变量会不会影响对照进入研究的概率。如果会,就要谨慎处理。
3.4 小样本研究更要精简变量
病例对照研究常用于罕见病或快速获取结果的场景。样本量往往有限。此时变量过多会导致模型不稳,甚至无法收敛。
实务上更建议:
- 先选1个主要暴露。
- 再保留少数关键混杂因素。
- 其他变量放入描述性分析或敏感性分析。
小样本研究的核心不是“变量齐全”,而是“变量精确”。
4. 一套更实用的变量选择顺序
如果你正在写开题、做数据库研究或准备论文,建议按以下顺序操作。
- 明确研究假说。先写清结局和核心暴露。
- 列出候选混杂变量。优先考虑年龄、性别、基础病、就医来源。
- 删除重复、弱相关、可能导致过度匹配的变量。
- 统一变量定义和测量方式。
- 根据样本量和研究设计决定是否做匹配。
- 在统计分析前预设主模型和调整变量。
这套顺序比“先收集再筛选”更稳,也更符合病例对照研究变量选择的逻辑。
最后,病例对照研究变量选择做得好,文章才会更接近真实因果。若你在变量定义、对照选择、混杂控制上反复纠结,说明你已经碰到病例对照研究最难的部分了。此时建议借助解螺旋的临床研究方法支持,把变量框架、研究设计和数据分析一次性理顺,减少返工,提高成稿效率。
总结Conclusion
病例对照研究变量选择的关键,不是追求数量,而是追求与研究目的的高度一致。先锁定暴露和结局,再筛选混杂因素,最后删除无关变量,才能提高研究的真实性和可解释性。抓住这3步,病例对照研究变量选择就不再混乱。
如果你正在做课题设计、数据库研究或论文写作,建议把变量框架先搭好,再进入统计分析。这样更容易得到可信结果,也更利于发表。需要更系统的研究设计支持,可以进一步了解解螺旋品牌的临床研究服务。
- 引言Introduction
- 1. 先搞清病例对照研究变量选择的核心逻辑
- 2. 3步完成病例对照研究变量选择
- 3. 变量选择落地时,最容易忽视的4个细节
- 4. 一套更实用的变量选择顺序
- 总结Conclusion