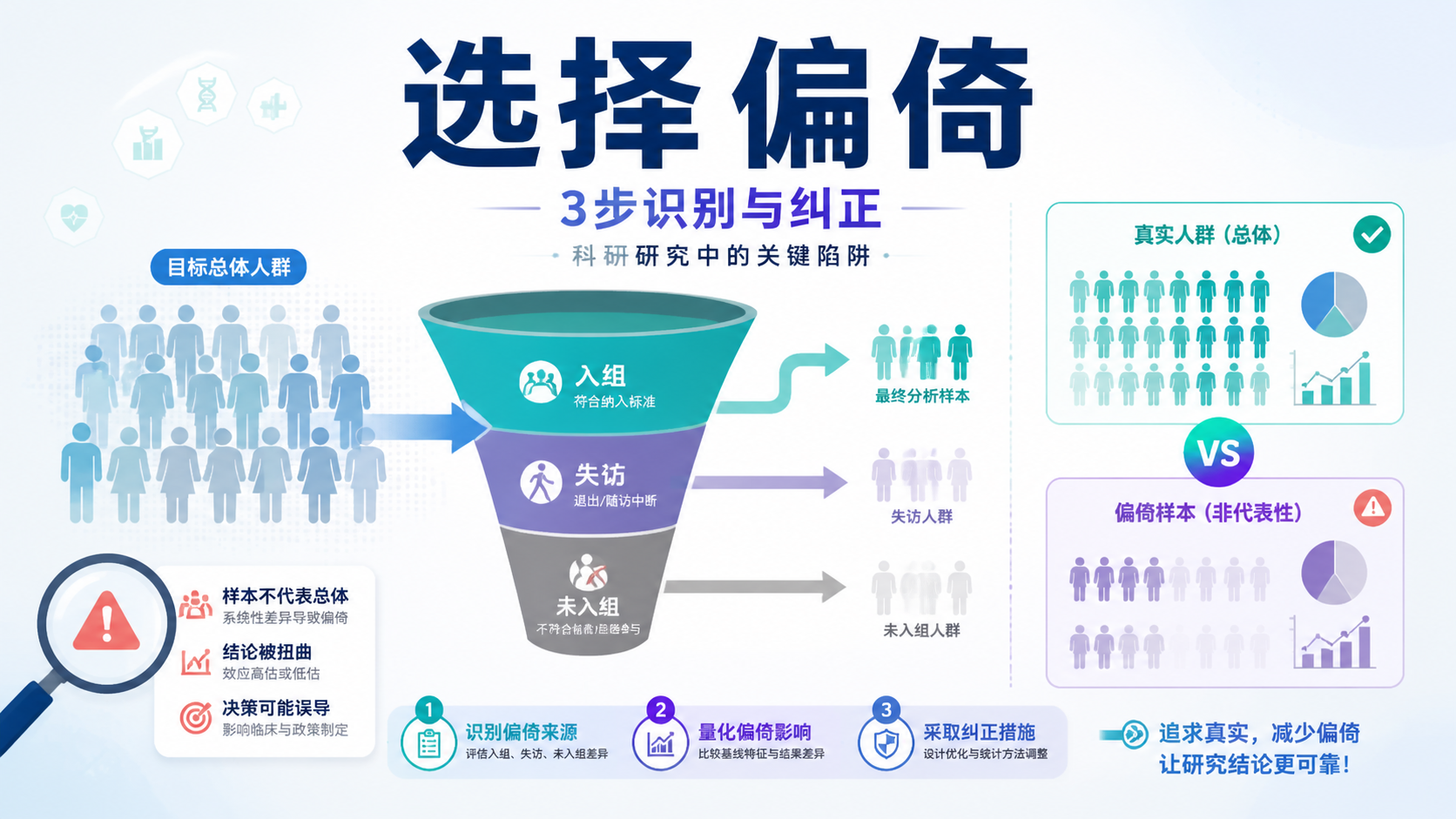
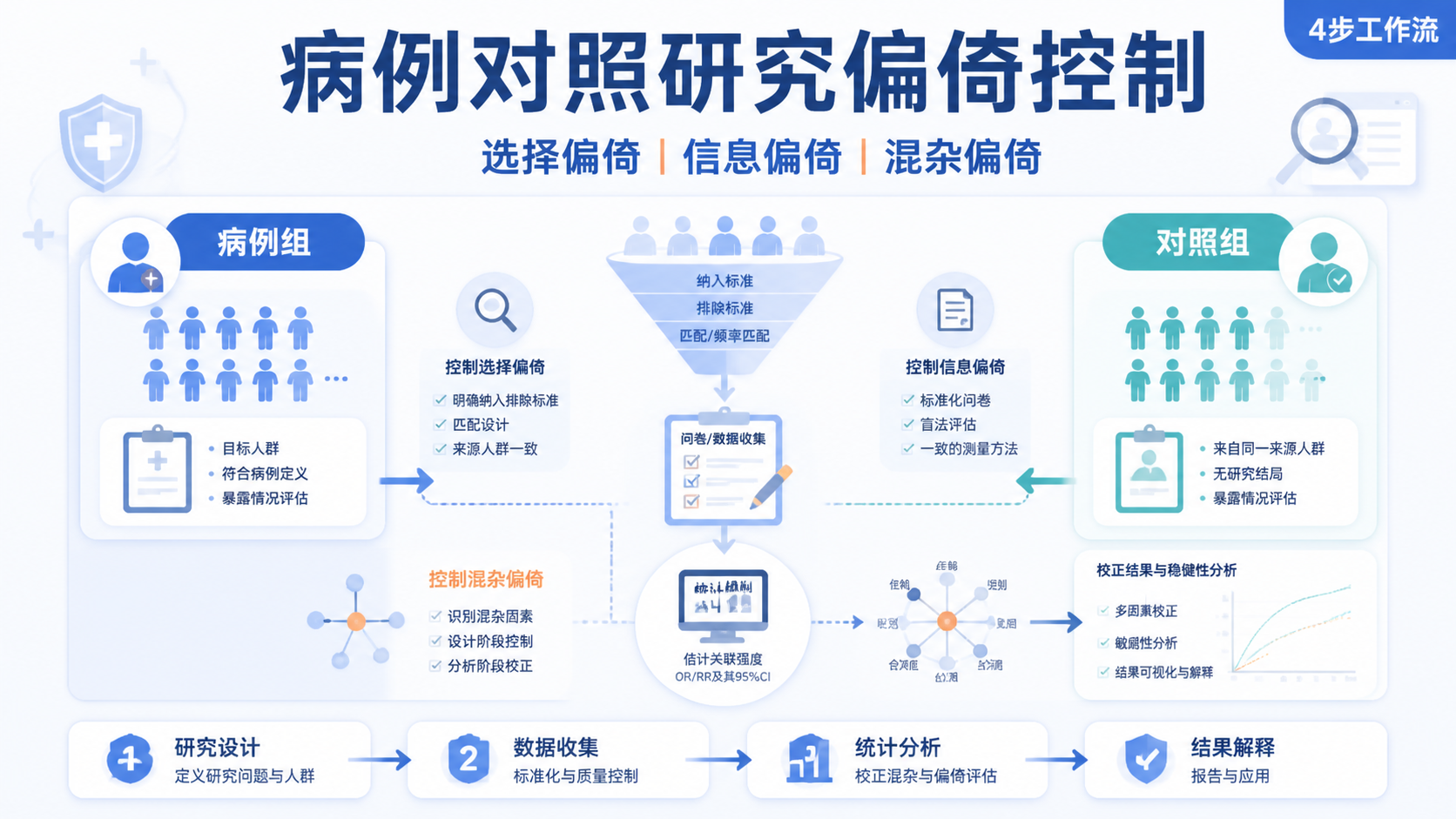
引言Introduction
信息偏倚是队列研究和其他观察性研究中最常见的系统误差之一。它会把“真实关联”扭曲成“看似合理”的结果,直接影响结论可信度。如果你在写论文、做课题或审稿,识别信息偏倚几乎是必修课。
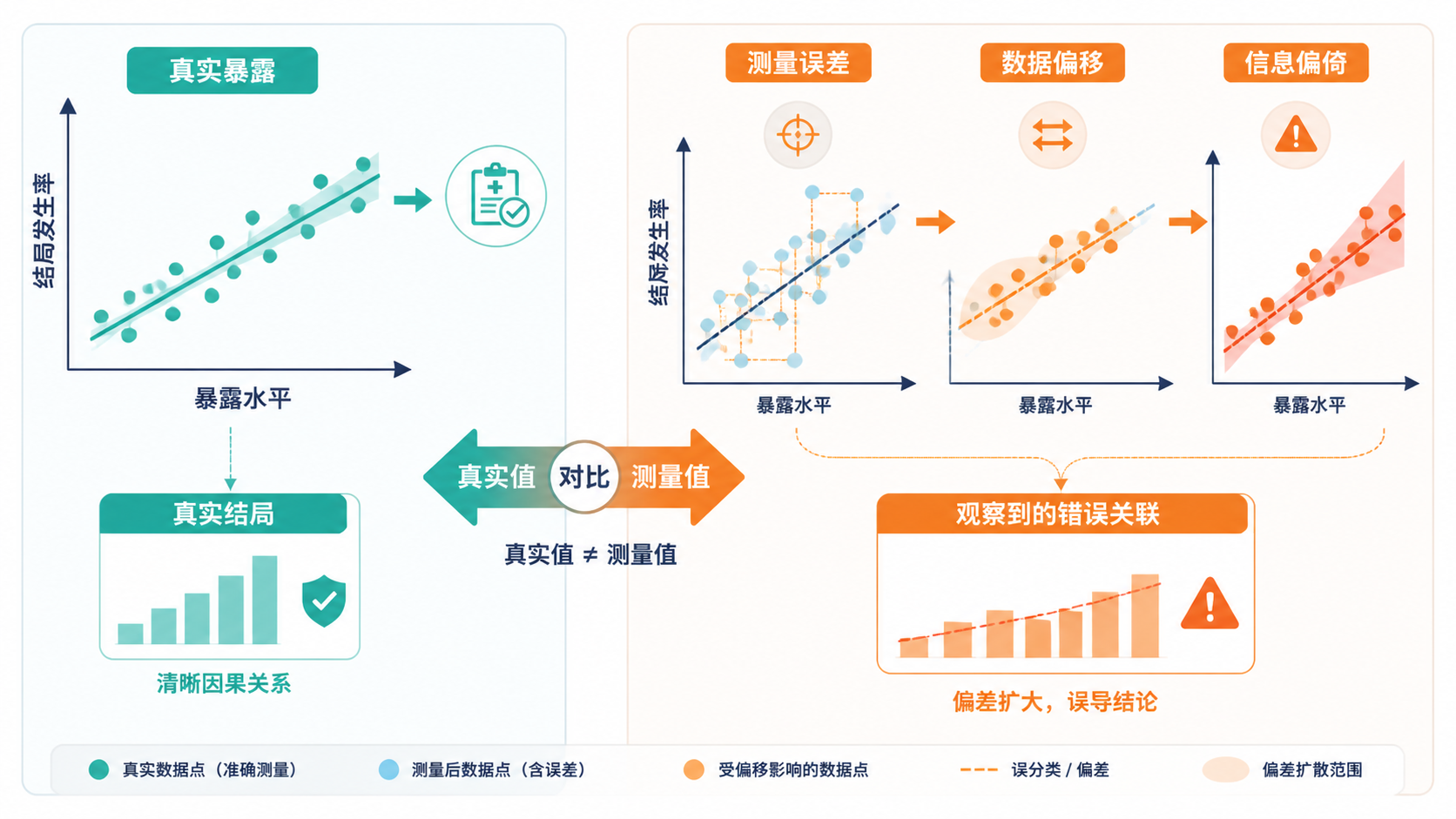
1. 先理解信息偏倚的本质
1.1 什么是信息偏倚
信息偏倚,又称测量偏倚或错分偏倚,是在获取暴露、结局或其他研究信息时产生的系统误差。它不是随机波动,而是方向性错误 。常见表现包括,把有病判成无病,把有暴露判成无暴露。
这类偏倚可发生在研究的多个环节。比如仪器不精确、标准不统一、询问方式不当、记录错误,都会让数据偏离真实值。一旦信息偏倚进入分析阶段,结果往往已经被污染。
1.2 为什么它难被发现
信息偏倚通常不容易靠肉眼识别。因为表面上看,数据仍然完整,统计结果也可能“显著”。但显著不等于真实。
在临床研究中,偏差越系统,越容易稳定地影响整组数据。这也是信息偏倚比偶然测量误差更危险的原因。
1.3 典型场景
常见场景包括:
- 诊断标准不明确,医生判读不一致。
- 问卷回顾既往暴露时,受试者记忆不准。
- 多中心研究中,不同中心使用不同检测方法。
- 记录不完整,关键变量被漏记或误记。
这些问题都可能让同一变量在不同个体之间被不一致地测量,从而产生偏倚。
2. 用3步识别信息偏倚
2.1 第一步,检查“测量链条”是否统一
识别信息偏倚,先看测量过程是否一致。你需要逐项核查:
- 暴露定义是否明确。
- 结局判定是否有统一标准。
- 仪器、试剂、设备是否一致。
- 调查员、医生、检验人员是否经过统一培训。
如果同一研究里,不同人用不同标准、不同工具、不同问法采集信息,信息偏倚风险就会明显升高。统一标准,是识别和预防信息偏倚的第一道门。
2.2 第二步,判断错分是否具有方向性
错分并不一定都一样。上游知识库中提到,信息偏倚可分为非特异性错分和特异性错分。识别时,要看错分是否均匀发生。
- 如果错分在各组中程度相近,通常会让效应值更接近1。
- 如果错分只发生在某一组,或两组错分程度不同,结果可能被高估或低估。
这一步的关键,是判断误差是否“偏向某一组”。
比如暴露组更容易被仔细检查,结局被更多发现,就可能出现诊断怀疑偏倚。反过来,如果对照组测量更粗糙,也会导致组间比较失真。
2.3 第三步,回看结果是否与临床逻辑一致
信息偏倚常常体现在“不合理但看起来合理”的结果里。识别时,可以反向验证:
- 结果是否过于整齐。
- 效应值是否异常接近或远离真实临床经验。
- 组间差异是否来自测量方式,而不是生物学差异。
例如,若某研究中自报暴露与客观检测差异很大,就要优先考虑回忆偏倚或报告偏倚。若多中心研究中不同中心结论差异明显,也要优先查测量流程是否一致。凡是结果和临床逻辑冲突,都要先想信息偏倚。
3. 从3个高频来源定位信息偏倚
3.1 回忆和报告问题
在回顾性研究中,让受试者回忆既往暴露,最容易出现信息偏倚。时间越久,记忆越不可靠。若问题设计带有暗示性,被调查者还可能主动修饰答案。
这类偏倚常见于生活方式、用药史、饮食史等变量。判断时,可重点看:
- 暴露是否依赖自述。
- 回顾时间是否较长。
- 是否存在社会期许性回答。
自报信息越多,信息偏倚风险越高。
3.2 观察和诊断问题
如果研究结局依赖医生判断,就要关注诊断水平和标准一致性。知识库明确指出,医生诊断水平不高、标准不明确、记录错误,都可能引起信息偏倚。
尤其在多中心研究中,不同中心可能使用不同设备或不同流程。此时,差异可能来自测量体系,而不是研究对象本身。研究设计再好,测量不统一,也会拉低证据等级。
3.3 记录和数据管理问题
历史性队列研究常见档案缺失、记录不全。看似只是数据缺失,实际可能导致系统性偏差。
如果缺失并不是随机发生,而是集中在某类人群,信息偏倚就会与选择偏倚相互叠加,进一步歪曲结果。此时应检查:
- 缺失是否集中在某一组。
- 缺失变量是否与结局相关。
- 原始病历、登记表、随访表是否一致。
4. 如何降低信息偏倚对论文和课题的伤害
4.1 设计阶段就要预防
最有效的做法,是在研究启动前把测量规则写清楚。包括纳入标准、结局标准、暴露定义、判读规则、质控流程。
如果可能,尽量采用更稳定、更精确的测量工具,并统一培训调查员。信息偏倚一旦形成,后期很难真正补救。
4.2 采用盲法和标准作业流程
在诊断试验和观察性研究中,盲法非常重要。让测量者不知道受试者分组,可减少主观判断差异。
同时,建议使用标准作业流程,减少“谁来测都不一样”的问题。对于检验和量表,最好定期校准和复核。
4.3 用重复测量和一致性检查做验证
知识库提到,估计信息偏倚的常用办法,是对随机样本进行重复调查或重复检测,再比较两次结果。
如果重复结果一致性差,说明测量稳定性不足,信息偏倚可能较大。对于论文写作,这类信息也应在方法学和局限性部分如实说明。
5. 研究写作中如何表达信息偏倚
5.1 讨论部分要写什么
在论文讨论部分,建议明确说明:
- 研究中哪些变量依赖自报。
- 哪些结局存在主观判定。
- 多中心或历史数据是否存在标准不统一。
- 偏倚可能对效应值造成何种方向影响。
不要只写“可能存在偏倚”,而要说明偏倚来自哪里、可能偏向哪一边。
这会显著提升论文的可信度和方法学质量。
5.2 审稿人最关注的点
审稿时,通常会重点看三件事:
- 暴露和结局是否测量一致。
- 是否存在组间差异化检测。
- 是否做过质量控制和一致性验证。
如果这些问题交代不清,研究再有统计显著性,也难以让人信服。对医学生、医生和科研人员来说,识别信息偏倚,本质上是在保护研究结论的有效性。
总结Conclusion
信息偏倚是观察性研究中最容易被忽视、却最能扭曲结论的系统误差。识别它,核心就是三步:先查测量链条是否统一,再判断错分是否有方向性,最后回看结果是否符合临床逻辑。只有把信息偏倚控制在方法学层面,研究结果才更接近真实。
如果你正在做临床研究、课题设计或论文写作,建议用更专业的研究支持工具提升质控效率。解螺旋 可帮助你更系统地梳理研究设计、偏倚控制与论文表达,让方法学更扎实,结论更可信。

- 引言Introduction
- 1. 先理解信息偏倚的本质
- 2. 用3步识别信息偏倚
- 3. 从3个高频来源定位信息偏倚
- 4. 如何降低信息偏倚对论文和课题的伤害
- 5. 研究写作中如何表达信息偏倚
- 总结Conclusion