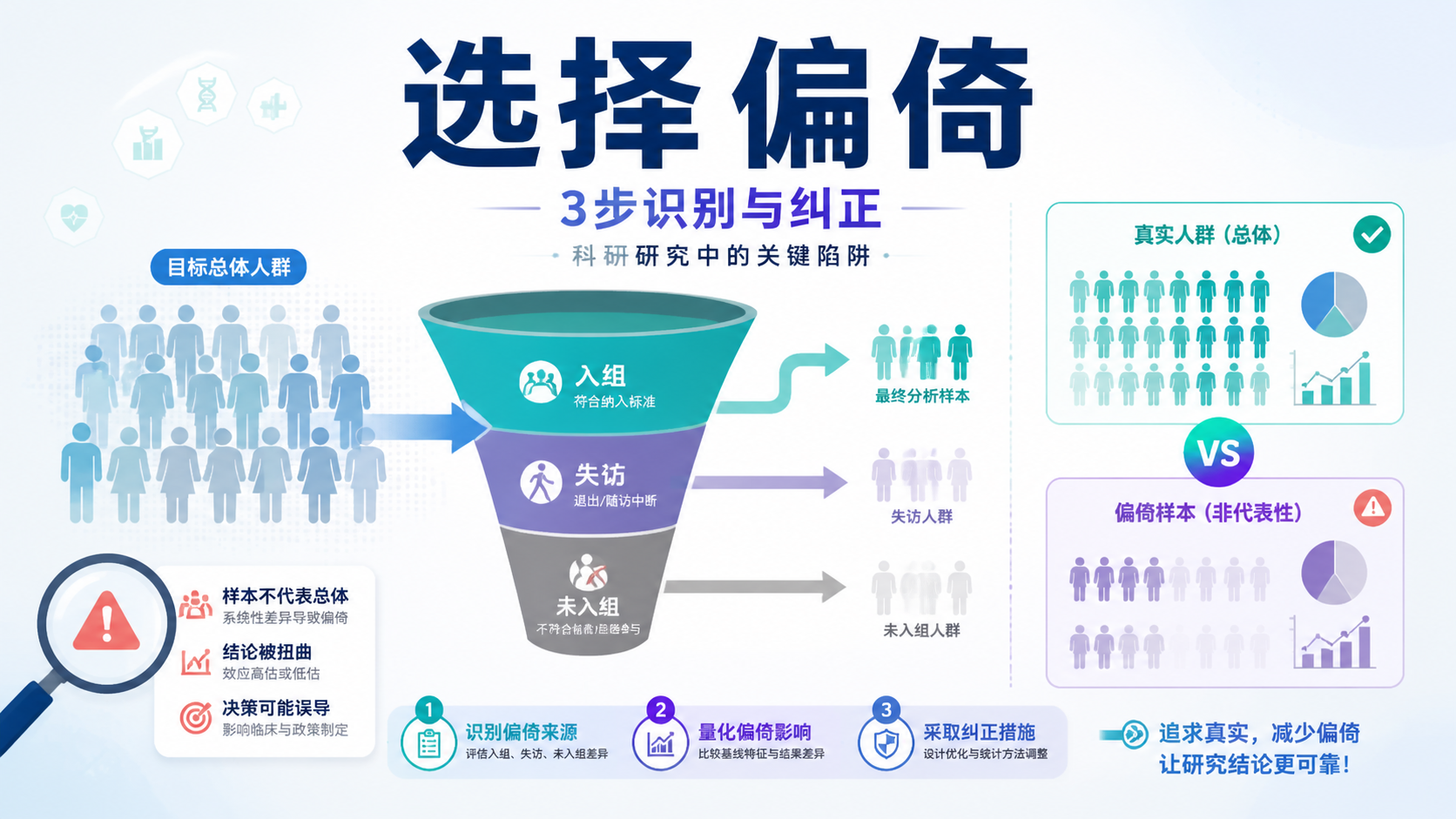
引言Introduction
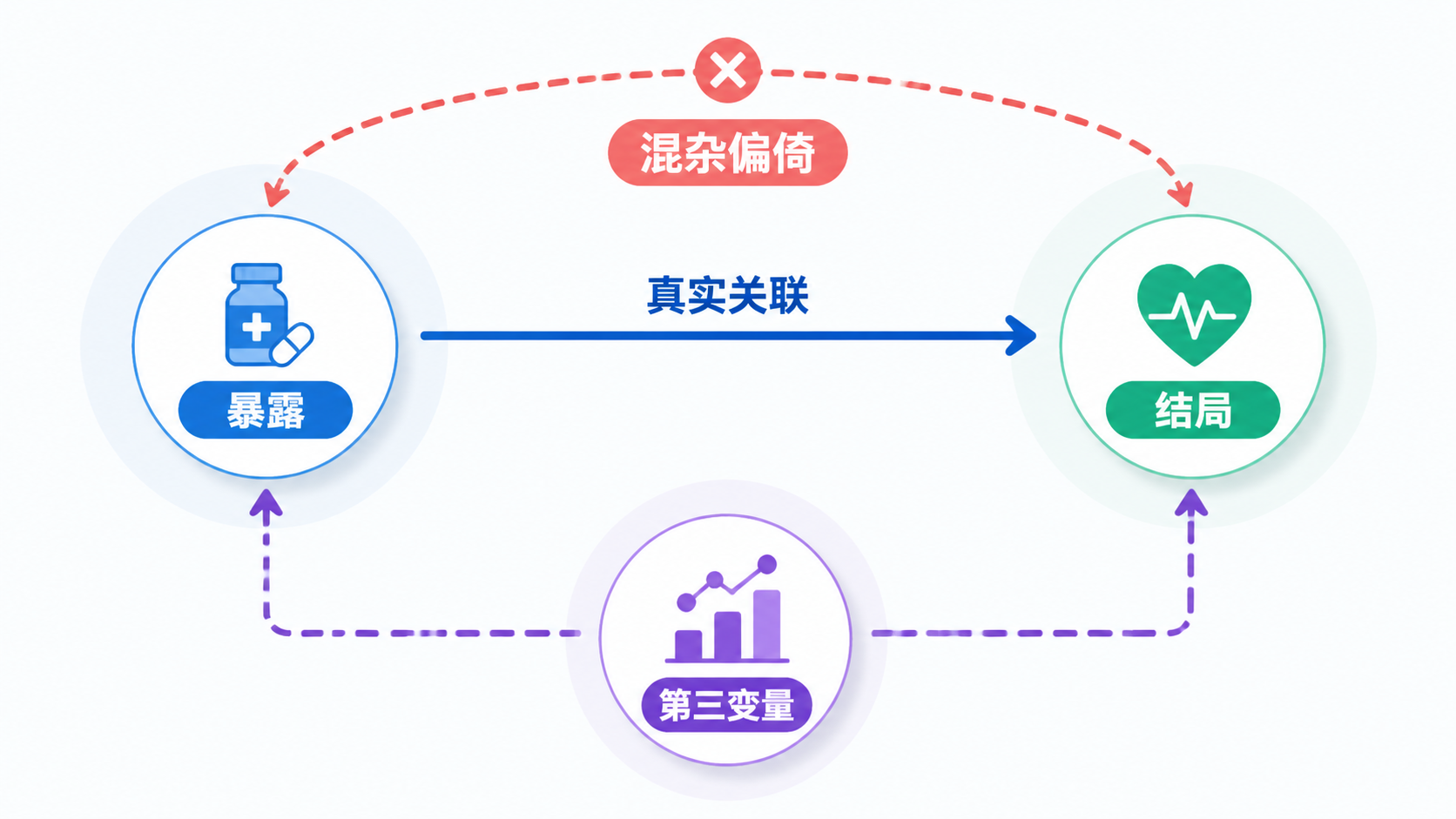
在观察性研究中,混杂偏倚 是最常见,也最容易被忽视的误差之一。它会让“暴露”和“结局”看起来有关,实际上却是第三因素在作祟。对医学生、医生和科研人员来说,识别混杂偏倚 ,是判断研究可信度的第一步。
1. 什么是混杂偏倚
1.1 先理解混杂的本质
混杂偏倚 ,指一个与暴露相关、又独立影响结局的第三变量,干扰了暴露与结局之间的真实关系。
换句话说,研究结果表面上像是“暴露导致了结局”,但真正推动结果变化的,可能是这个第三因素。
例如,在研究“咖啡与心血管疾病”时,如果饮酒、吸烟、年龄分布不同,就可能把真实效应扭曲。
这类问题在病例对照研究、队列研究、横断面研究中都很常见。
1.2 为什么它会影响结论
混杂偏倚 的危险在于,它不会让数据显得“错误”,而是让数据显得“合理但不真实”。
很多研究设计看似完整,但如果没有控制混杂,最终得到的关联强度可能被高估、低估,甚至方向相反。
从方法学上看,混杂问题会直接影响内部真实性。
因此,判断一项研究能否支持因果推断,核心之一就是先看它是否充分识别并处理了混杂偏倚。
2. 识别混杂偏倚的4步法
2.1 第一步:判断第三变量是否满足混杂条件
识别混杂偏倚 ,先看第三变量是否同时满足三个条件。
一是与暴露有关。二是与结局有关。三是不能位于暴露到结局的因果链上。
这是最基本的判定框架。
如果某变量只与结局相关,但与暴露无关,通常不是混杂。
如果它是暴露之后才出现的中介变量,也不应当按混杂处理。
实务中最常见的错误 ,是把中介、效应修饰和混杂混在一起。
这会导致调整过度,反而引入新的偏倚。
2.2 第二步:检查基线特征是否失衡
很多混杂偏倚 可以通过基线表初步发现。
如果暴露组和对照组在年龄、性别、病程、吸烟史、合并症等方面明显不平衡,就要提高警惕。
尤其是样本量不大时,随机分配也可能出现偶然失衡。
观察性研究中,这种失衡更常见,也更难通过后续分析完全纠正。
建议优先查看以下内容。
- 暴露组与对照组的人群构成。
- 关键预后因素的分布。
- 是否存在明显的选择偏倚。
- 是否有分层前后效应变化。
如果某个变量在两组间差异显著,而且它又与结局密切相关,那么它很可能是混杂因素。
2.3 第三步:看效应量在调整前后是否明显变化
识别混杂偏倚 ,不能只看P值。
更重要的是看效应量在调整前后是否变化明显。
常用做法是比较粗效应估计值与校正后的估计值。
如果加入某些变量后,OR、RR、HR变化超过预设阈值,说明这些变量可能构成混杂。
很多方法学文献常用的经验标准是,若效应量变化达到10%及以上,应考虑存在混杂。
但这不是绝对标准,具体还要结合研究场景、样本量和变量间关系判断。
注意,显著不等于混杂,不显著也不代表没有混杂。
因此,判断逻辑必须建立在“变化幅度”和“变量关系”上,而不是单纯看统计学显著性。
2.4 第四步:结合因果路径图和专业知识验证
仅靠统计模型,无法完全识别所有混杂偏倚 。
因为模型只能处理“你已经想到并测量到的变量”。
这时,因果路径图,尤其是DAG,可以帮助判断哪些变量应纳入调整,哪些变量不该调整。
它能清楚展示暴露、结局、混杂因素、中介变量之间的关系。
临床专业知识同样重要。
例如,某些基础疾病在药物使用研究中既影响处方选择,又影响预后,这类变量往往需要纳入控制。
而某些治疗后指标,虽然与结局相关,却可能是中介,不宜贸然调整。
真正高质量的研究,不是调整得越多越好,而是调整得越准确越好。
3. 常见识别误区
3.1 把相关性当成混杂
很多人看到变量与结局相关,就认为它是混杂因素。
其实不对。混杂的前提是,它还必须与暴露相关。
如果只与结局相关,但与暴露无关,那更可能是独立预后因素,而不是混杂。
这类变量是否纳入模型,要看研究目的,但不能简单贴上混杂标签。
3.2 过度调整
另一个常见问题,是把所有能测到的变量都放进模型。
这会带来过度调整,甚至调整掉真实效应。
例如,把中介变量或碰撞变量误当成混杂变量,就可能引入新的偏倚。
因此,变量进入模型前,必须先判断它在因果结构中的位置。
3.3 忽视残余混杂
即使做了调整,混杂偏倚 也未必完全消失。
原因包括测量误差、未测量变量、分类粗糙、样本量不足等。
例如,把“吸烟”简单分成有无,可能不足以消除其混杂影响。
更理想的做法,是尽量获取更精细的暴露强度、持续时间和频率信息。
4. 如何降低混杂偏倚对研究的影响
4.1 在设计阶段先控制
最有效的策略,是在研究设计阶段减少混杂偏倚 。
常见方法包括随机化、限制、匹配和分层设计。
随机对照试验之所以证据等级更高,核心原因之一就是它能平衡已知和未知混杂因素。
而在观察性研究中,限制纳入标准、匹配关键变量,能先削弱一部分混杂影响。
4.2 在分析阶段再校正
如果设计阶段无法完全消除,就要在分析阶段控制。
常见方法包括多变量回归、分层分析、倾向评分匹配、倾向评分加权等。
不过要注意,方法本身不是万能的。
前提是变量选得对,模型设得对,数据质量也要足够高。
4.3 在报告中透明说明
高质量研究不仅要控制混杂偏倚 ,还要把控制过程写清楚。
包括纳入了哪些混杂变量,为什么选择它们,是否做了敏感性分析,是否评估了未测量混杂。
对读者来说,这些信息直接决定结论能否被信任。
对科研人员来说,这也是提升论文可发表性的重要部分。
5. 研究者实际操作时的4个检查点
5.1 先列出潜在混杂变量清单
在正式建模前,先结合文献和临床经验列清单。
优先考虑年龄、性别、基础疾病、病程、严重程度、治疗史等变量。
这些变量通常最容易构成混杂偏倚 。
5.2 再画出因果关系图
用DAG梳理变量关系。
明确哪些是暴露前变量,哪些是中介,哪些可能是碰撞变量。
这一步能明显减少错误调整。
5.3 之后比较调整前后结果
看效应方向、效应大小、置信区间是否发生变化。
如果变化明显,说明混杂控制在起作用。
如果几乎不变,也不能直接下结论,还要看模型和变量是否充分。
5.4 最后做敏感性分析
即使已经控制了已知因素,仍应评估未测量混杂的影响。
敏感性分析可以帮助判断结果稳健性。
这是临床研究和流行病学分析中非常重要的一环。
总结Conclusion
识别混杂偏倚,关键不是记住定义,而是掌握判断逻辑。
先看第三变量是否同时关联暴露和结局,再看基线是否失衡,再比较调整前后效应变化,最后结合DAG和专业知识验证。
这套4步法 ,适合医学生快速入门,也适合科研人员在论文设计和审稿中使用。

如果你希望把这些方法真正用于论文设计、课题申报或数据分析,建议使用更系统的研究支持工具。解螺旋 可以帮助你更高效地梳理变量关系、优化研究思路、提升混杂控制的规范性,让你在面对复杂临床数据时更快找到问题关键。
- 引言Introduction
- 1. 什么是混杂偏倚
- 2. 识别混杂偏倚的4步法
- 3. 常见识别误区
- 4. 如何降低混杂偏倚对研究的影响
- 5. 研究者实际操作时的4个检查点
- 总结Conclusion