引言Introduction
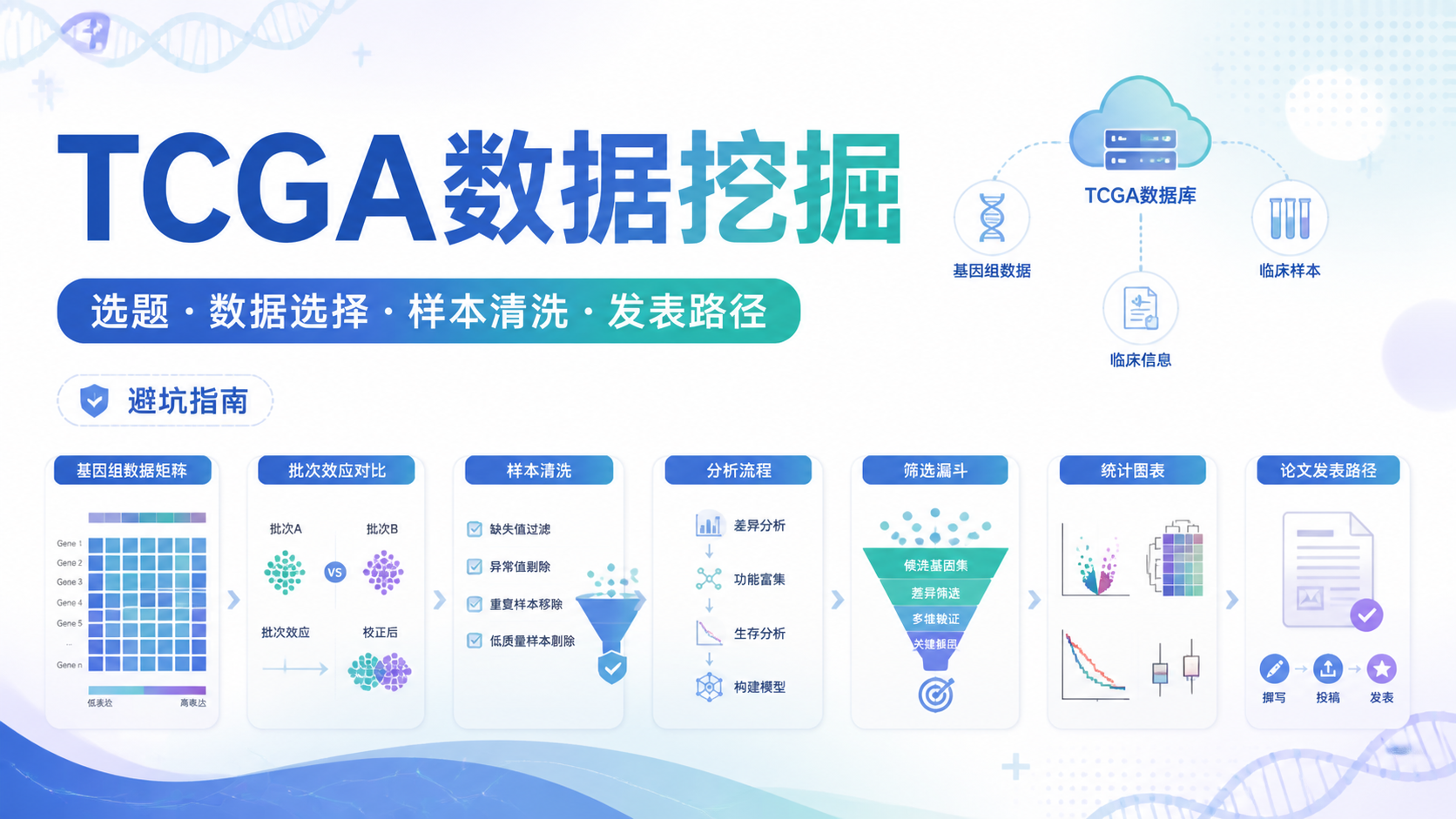
TCGA数据整理看似只是读文件、合并表格,实际最容易出错的是样本ID、临床分期和重复测序样本。如果整理不规范,后续差异分析、WES分析和生存分析都会被放大误差。 本文围绕tcga数据整理,按清洗、编号、临床、工具四个层面,给出可直接落地的规范。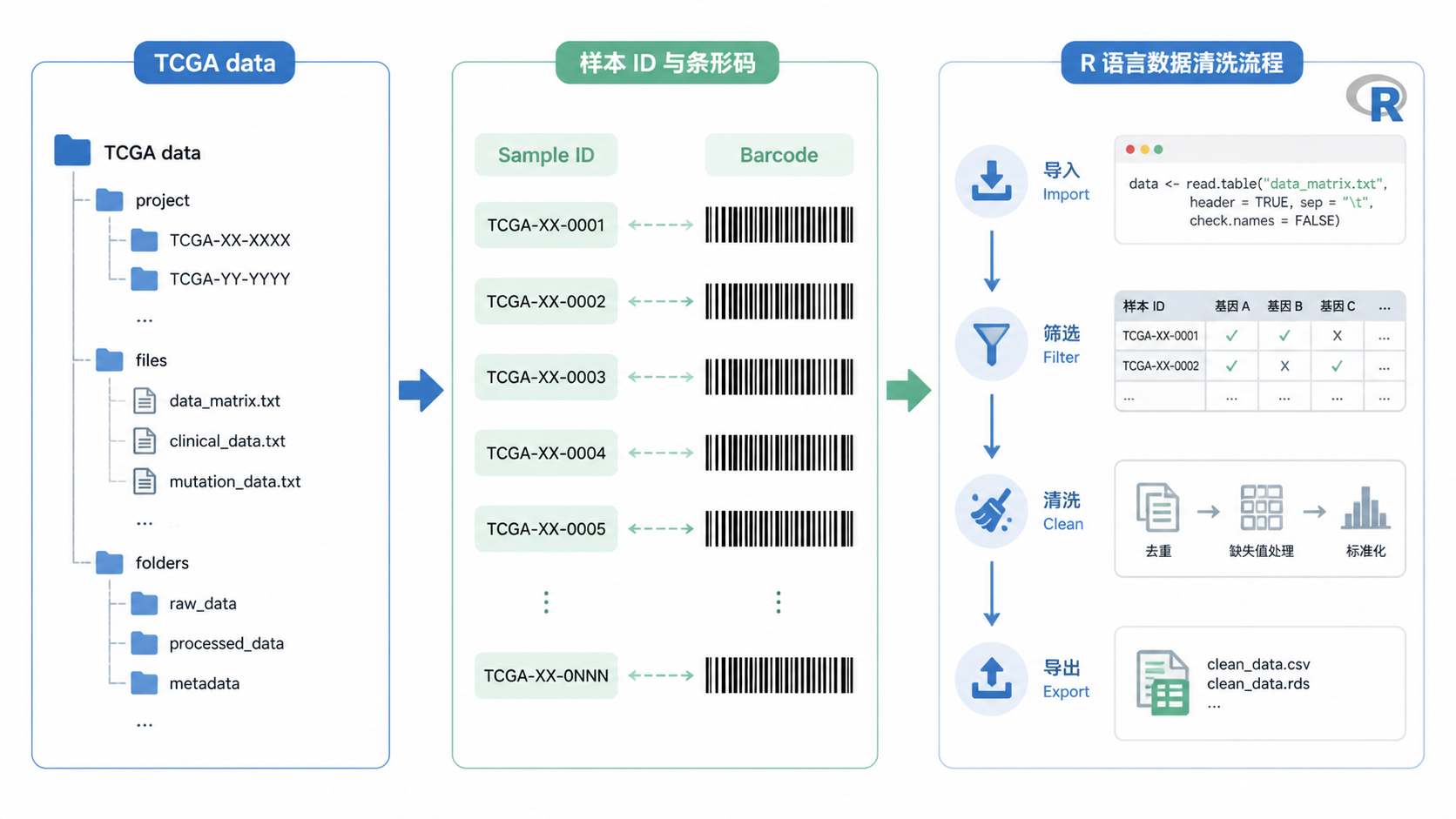
1. 先把表达矩阵整理干净
1.1 从单个样本开始核对
tcga数据整理的第一步,不是批量处理,而是先随机抽取两个样本做核对。课程中先比较两份count文件的行列数,再用identical()判断第一列是否一致,最后用cbind()合并。
这个步骤的意义很直接。 它能先确认基因行是否对齐,避免后面批量合并时出现错位。对于医学生和科研人员来说,这一步相当于先做质控,再做统计。
1.2 批量读取前先统一命名规则
TCGA原始文件往往分散在多个目录下。整理时要先定义文件名的规律,再用正则表达式筛选目标文件。知识库中给出的做法是,先用file.path("1.expdata/", x)拼接路径,再用lapply()逐个读取。
随后用do.call(cbind, exp_list)把结果合并成表达矩阵。这里最关键的是检查行名和列名。 行名通常是基因,列名应是样本文件名或样本ID。如果列名异常,后续分析会全部受影响。
1.3 数据矩阵要保留可追溯性
tcga数据整理不是单纯“把数据拼起来”,而是要保留来源信息。每一列样本都应能追溯到原始文件。这样在发现异常值时,才能快速回查原始样本。
建议保留以下信息:
- 原始文件名
- 样本ID
- 读取日期
- 数据类型,如count、FPKM或临床信息
可追溯性是E-E-A-T里“可信度”的基础。
2. 样本ID必须按TCGA规则统一
2.1 barcode是样本识别核心
TCGA的barcode是样本识别标准。它包含项目、组织来源、样本类型、分析平台等信息。知识库明确提到,样本编号中01到09通常代表肿瘤样本,10到19代表正常样本,20到29代表对照样本。
在tcga数据整理里,如果不理解barcode,就很容易把肿瘤样本和正常样本混淆。对于后续分组分析,这是致命错误。
2.2 用metadata把文件名对上真实样本
课程中提到可通过jsonlite::fromJSON()读取metadata文件,再提取TCGA样本ID,并把文件名与样本ID一一对应。不同肿瘤项目的ID列数可能不同,因此不能假设所有项目完全一致。
整理时应重点做三件事:
- 读取metadata
- 提取样本ID
- 修改表达矩阵列名
列名统一后,表达矩阵才真正可用于下游分析。
2.3 重复测序样本要有筛选原则
TCGA中常见一个病例对应多个测序结果。课程和上游知识都提示,重复样本处理不能随意删除。一般要依据replicate filter、analyte、plate和center等信息判断。
常见原则包括:
- 优先保留更合适的测序版本
- 去除FFPE等不优样本
- 对重复样本按官方规则筛选
- 保留可追溯的最终编号
如果同一患者存在多个条目,必须先统一筛选逻辑,再进入统计分析。
3. 临床信息要优先选对格式
3.1 XML能用,但解析复杂
TCGA临床信息常见于.xml文件。课程中使用XML包的xmlParse()逐个读取,再查看节点并提取所需字段。这种方法可以得到分期、生存、TNM等信息。
但它的问题也很明显。XML结构复杂,字段分散,不同项目节点不完全一致。尤其是分期字段,可能出现stage 3A、3B、3C等细分层级。 如果没有统一规则,很容易在字符串切割时出错。
3.2 更推荐使用官方整理好的表格式数据
上游知识明确提到,TCGA工作人员更推荐使用table格式的临床文件。它通常把内容分成多个文件,例如:
- clinic patient
- follow up
- treatment
- drug
- radiation
这种方式的优势是字段更清晰,且与XML信息一致。对于需要快速完成tcga数据整理的研究人员来说,表格式临床数据比XML更稳妥。
3.3 分期信息要区分临床分期和病理分期
在肿瘤研究中,分期不是一个字段就能解决的问题。知识库特别强调,Stage分为clinical stage和pathological stage。真正需要重点关注的是pathological stage。
常见细节包括:
- stage 3可能细分为3A、3B、3C
- TNM分期中,T、N、M要分别核对
- 病理分期和临床分期不能混用
如果研究目标是疗效、预后或分层分析,建议优先提取病理分期,再根据研究设计决定是否保留TNM细项。
4. 简化流程要选对工具
4.1 TCGAbiolinks更适合规范化下载
如果手动处理文件太多,可以直接用TCGAbiolinks。课程中介绍了getGDCprojects()查看项目,随后用GDCquery()查询,GDCdownload()下载,GDCprepare()整理表达矩阵。
它的优势很明显:
- 能直接从GDC获取数据
- 适合批量下载
- 提供相对标准化的处理流程
对于需要减少人工失误的tcga数据整理,这是更稳的方案。
4.2 RTCGA适合快速调用,但要注意局限
RTCGA包可以直接按项目调取表达和临床数据,适合快速探索。不过知识库也提示了它的局限性。主要问题是数据更新和标准化可能不如官方渠道及时。
因此,RTCGA更适合:
- 课程演示
- 快速预览
- 初步验证分析思路
不太适合直接作为最终发表数据源。正式研究仍应优先使用GDC或官方推荐的数据整理路径。
4.3 建议建立固定清洗流程
一套稳定的tcga数据整理流程,建议至少包含以下步骤:
- 下载原始数据
- 核对文件命名和样本ID
- 去除重复和异常样本
- 统一临床字段
- 记录筛选规则
- 保存最终可复现版本
这样做的价值不只是“整齐”,而是保证结果可复现。对论文投稿、课题答辩和团队协作都很重要。
总结Conclusion
tcga数据整理的核心,不是把文件拼在一起,而是先保证样本ID正确,再保证临床字段统一,最后保证流程可追溯。 从表达矩阵、barcode、临床分期到工具选择,每一步都决定后续分析是否可信。
如果你希望减少手工清洗时间、提高整理规范性,可以结合解螺旋的课程和工具方案,把TCGA原始数据快速转成可分析的数据集。对于科研人员而言,节省的不是时间,而是返工成本和结果风险。 
- 引言Introduction
- 1. 先把表达矩阵整理干净
- 2. 样本ID必须按TCGA规则统一
- 3. 临床信息要优先选对格式
- 4. 简化流程要选对工具
- 总结Conclusion