





引言Introduction
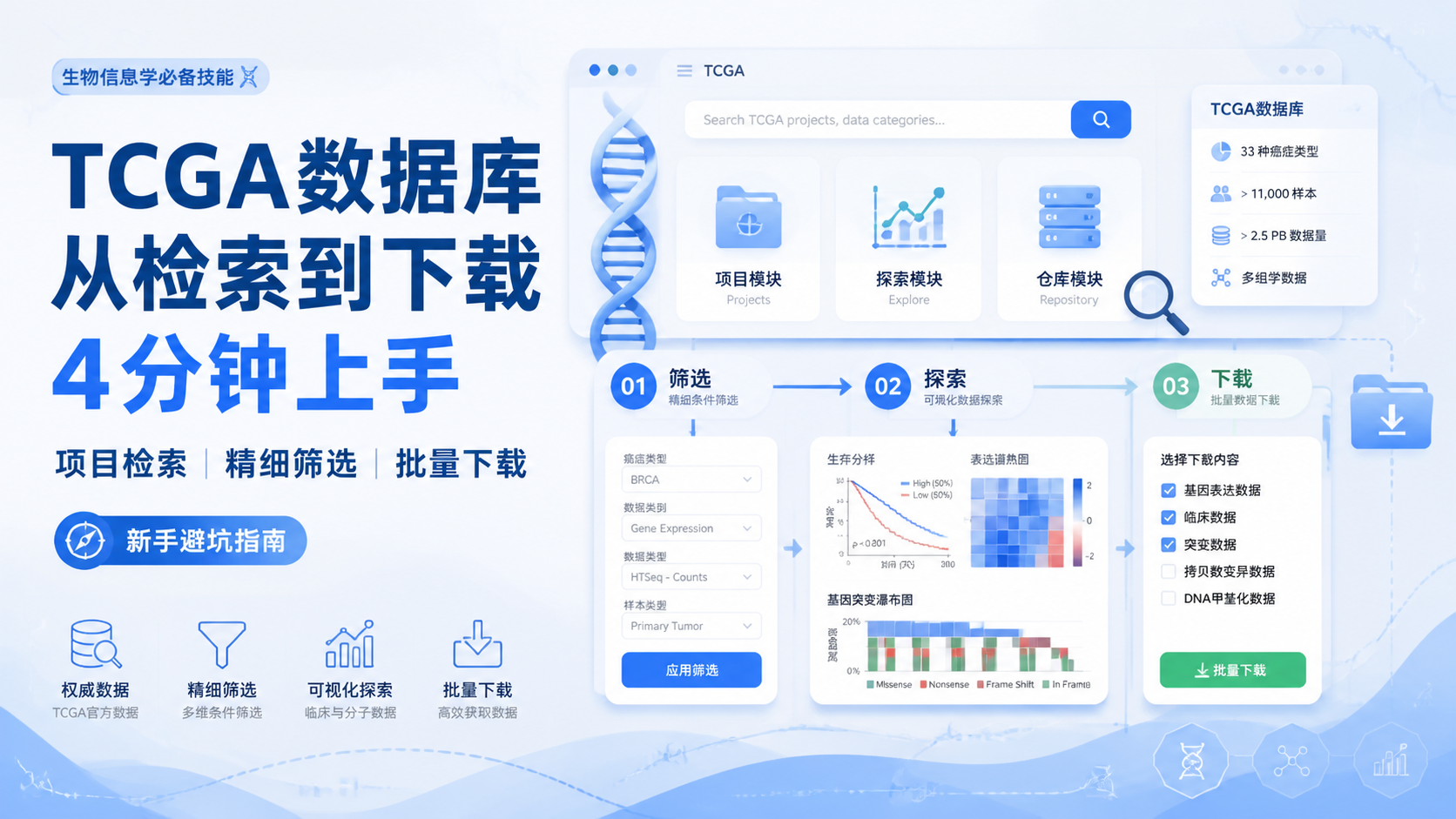
TCGA数据库使用 常卡在第一步。入口多、选项杂、下载路径不清晰,很多医学生和科研人员还没开始分析,就先被检索和下载流程劝退。本文用最短路径,帮你快速掌握TCGA数据库使用的核心逻辑。
1. 先理解TCGA数据库的用途和数据层级
1.1 TCGA能解决什么问题
TCGA是癌症基因组图谱项目,核心价值是把肿瘤的转录组、临床、甲基化、蛋白组等数据集中到一个平台。对研究者来说,它最常用的用途有三类。
- 找差异表达基因。
- 关联分子特征和预后。
- 做肿瘤和正常组织比较。
TCGA数据库使用的关键,不是“会点网页”,而是先明确你要找哪类数据。 如果目标是RNA测序,就优先看表达数据和临床数据。如果想做机制探索,再考虑突变、甲基化和蛋白组。
1.2 数据等级决定你能下载什么
TCGA数据大致分为不同层级。课程知识库中提到,level 1和2多属于受限访问,level 3大多可开放下载。对临床研究和基础分析来说,公开数据通常已经够用。
这意味着,大多数入门场景下,你不必先纠结复杂权限。 先用开放数据建立分析流程,再根据课题需要申请受限数据,会更高效。
1.3 常见数据类型与分析场景
TCGA提供的数据类型较丰富,常见的包括:
- 转录组测序。
- 临床数据。
- DNA甲基化。
- 蛋白组测序。
- miRNA测序。
- 单细胞相关数据。
如果你是初学者,建议先从RNA测序 + 临床资料 入手。这个组合最适合完成差异分析、生存分析和分层比较。
2. TCGA数据库使用的三种检索入口
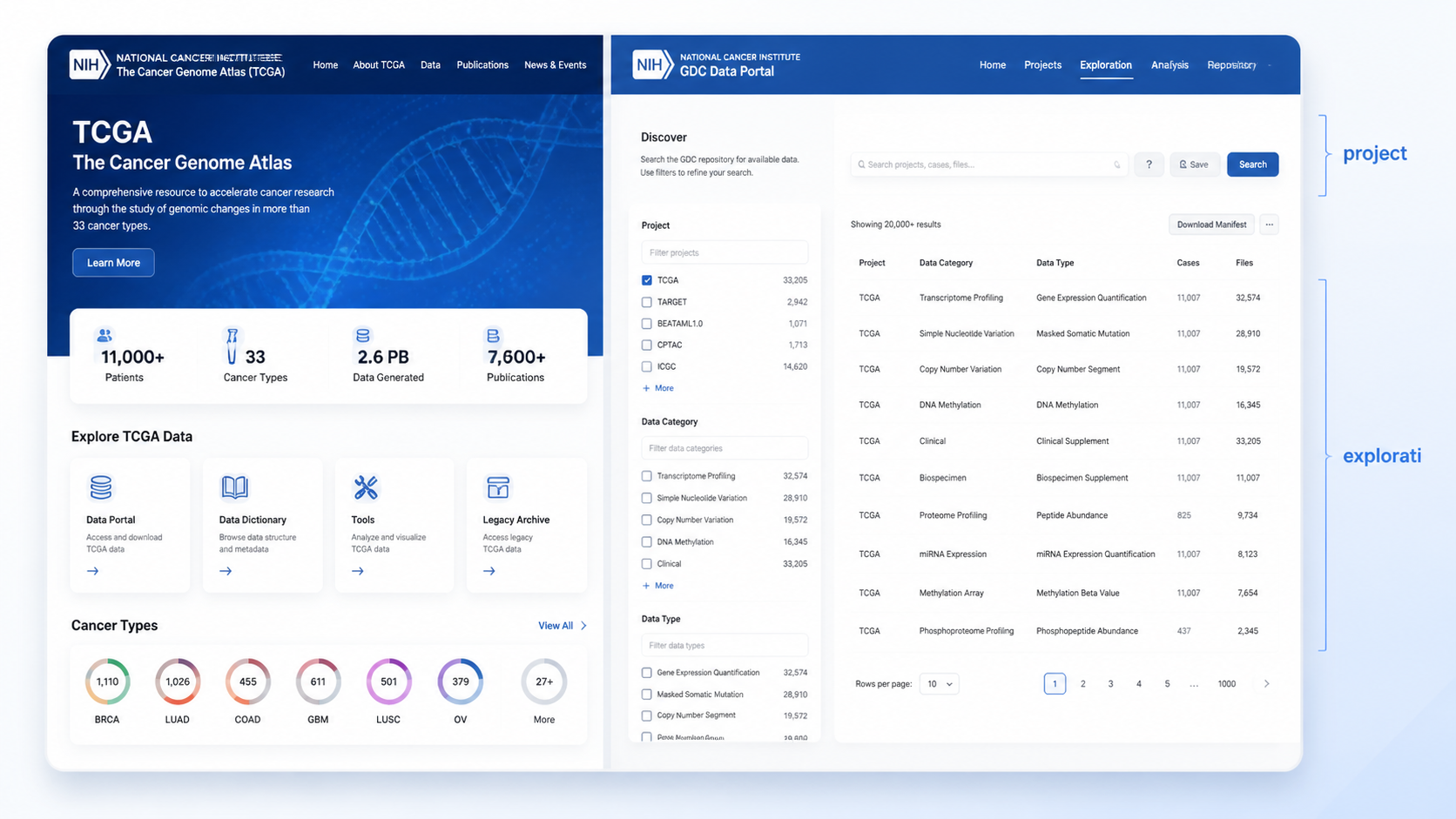
2.1 Project模块,适合按项目快速筛选
TCGA改版后,项目入口信息更清晰。知识库显示,数据库可按项目、疾病类型、数据分类和实验策略等维度筛选,覆盖67个肿瘤部位、20个项目、59种疾病类型。
在project模块里,你可以先选项目,再按原发部位、实验策略缩小范围。比如做结肠癌RNA测序,就可以按TCGA、结肠、RNA测序逐步筛选。
这个入口适合“我知道我要研究什么癌种”的场景。 它的优点是快,缺点是细节相对少。
2.2 Exploration模块,适合做精细检索
exploration提供四类入口。分别是cases、genes、clinical、mutations。
- cases:按样本检索。
- genes:按基因检索。
- clinical:按临床信息检索。
- mutations:按突变信息检索。
其中clinical模块很实用。它能查人口学资料、诊断资料、治疗情况和暴露因素。例如年龄、性别、分期、病理分期、治疗药物、吸烟史等。
如果你要做分层分析,exploration通常比project更精确。 例如你想筛选亚洲人、病理学I到II期的肝癌样本,就应该优先用clinical条件筛选。
2.3 Repository模块,适合最终下载
repository是最重要的下载入口。它分为files和cases两部分,能把前面检索到的数据最终加入购物车。
知识库明确提到,repository模块的筛选条件最丰富,而且三种检索结果最终都要通过这里进入下载流程。也就是说,TCGA数据库使用真正落地的步骤,往往都要回到repository。
如果你已经筛到目标数据,就可以在这里查看access、experimental strategy、data format等信息,然后加入cart。
3. 用一个例子掌握完整检索路径
3.1 以TCGA COAD RNA测序为例
课程中给出的示例是TCGA COAD RNA测序数据。操作逻辑很简单。
- 在project中选择项目TCGA。
- 选择原发部位结肠。
- 选择实验策略RNA测序。
- 查看右侧病理类型。
- 点击open querying repository进入repository。
- 选择access为open。
- 点击add all files to cart。
这个流程体现了TCGA数据库使用的标准思路:先定位项目,再确认数据类型,最后进入下载。
3.2 以TCGA LIHC临床分层为例
如果你研究肝癌,可以用exploration做更细筛选。知识库示例中提到,可在cases里选择program为TCGA、project为TCGA LIHC,再在clinical中设置HCC病理学分期为stage I和II,种族为Asian。之后再进入repository下载。
这种方法特别适合做亚组分析。比如你要比较不同分期、不同种族或不同治疗背景的表达差异,就必须先把样本筛准。
样本筛选越清楚,后续统计越稳。 这也是很多TCGA数据库使用新手容易忽略的一步。
3.3 基因和突变检索怎么用
genes入口可以查看特定基因的突变情况。知识库中提到,可检索到716个基因的突变信息,并以TP53为例展示生存差异。mutations入口则提供突变后果、突变类型、SIFT、PolyPhen等信息,还能查看特定位点相关的生存曲线。
对临床科研来说,这两个入口常用于:
- 找候选驱动基因。
- 看突变是否影响预后。
- 为机制实验提供线索。
如果你的课题要连接“分子改变”和“生存结局”,这两个模块很有价值。
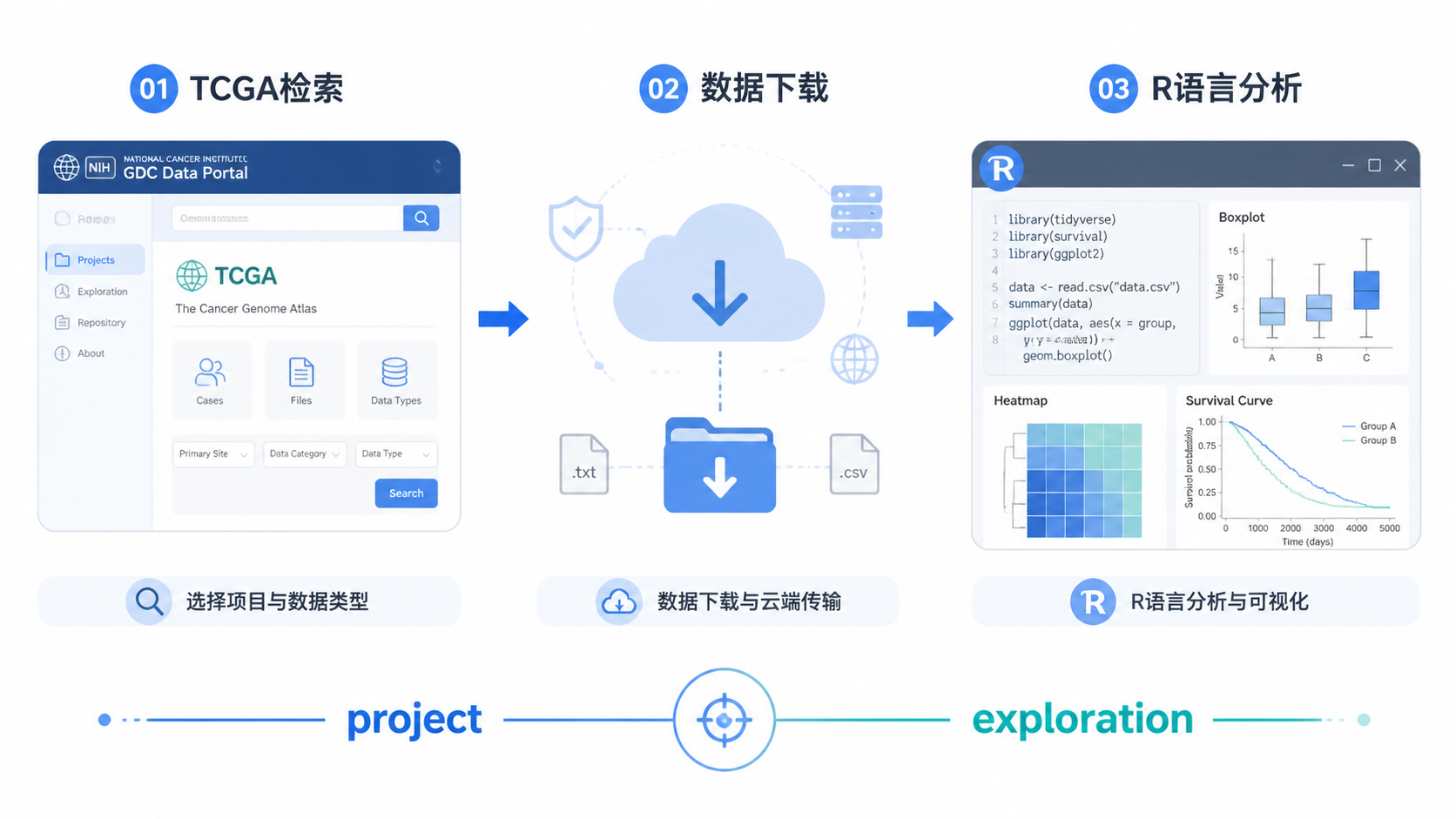
4. TCGA数据库使用后,怎么完成下载
4.1 直接网页下载,适合小数据集
知识库给出三种下载方式。第一种是网页购物车直接下载。适合样本数较少、网速较好的情况。
流程是:检索完成后进入cart,核对文件数、样本数、项目来源和文件大小,再点击下载。
这种方式最简单,但不适合大批量下载。
4.2 GDC client,适合批量下载
当样本量较大时,推荐使用GDC client。知识库给出了一套标准步骤。
- 下载GDC Data Transfer Tool。
- 设置环境变量。
- 在命令行输入
GDC-client -h验证是否成功。 - 使用manifest文件下载。
常见命令形式为:gdc-client download -m manifest文件路径。
对于需要批量获取TCGA表达矩阵的人来说,GDC client更稳定,也更适合自动化整理。
4.3 替代网站和R包,适合提高效率
除了官网,知识库还提到UCSC Xena、Firehouse以及R包下载方式。
- UCSC Xena适合获取整理好的公共数据。
- Firehouse可用于部分数据下载。
- R包适合在分析环境中直接调取数据。
如果你已经进入正式科研阶段,这些方法能明显减少手工处理时间。TCGA数据库使用到后期,重点就从“下载”转向“标准化整理”。
5. 新手最容易踩的3个坑
5.1 只会下载,不会筛选
很多人一上来就下载全部数据,结果文件多、格式乱、样本对不上。正确做法是先明确癌种、数据类型和实验策略,再下载。
5.2 只看表达,不看临床
表达分析如果不结合临床,就很难形成高质量结论。至少要同步提取分期、生存、治疗信息。这样才能做出更完整的结果。
5.3 忽略样本类型和开放权限
repository里经常需要看access和sample type。尤其是公开数据与受限数据混在一起时,如果不先筛选,后面很容易卡住。
真正高效的TCGA数据库使用,是“筛选优先,下载其次,分析最后”。
6. 4分钟上手的最短操作路径
6.1 记住这条流程
如果你只想快速上手,可以直接记这条路径:
- 先在project确定癌种。
- 再在exploration细化样本。
- 最后到repository下载。
- 小数据直接网页下。
- 大数据用GDC client。
6.2 记住这三个优先级
- 先看project,确认研究对象。
- 再看clinical,确认分层条件。
- 最后看repository,完成导出。
这套顺序几乎适用于所有常见的TCGA数据库使用场景。
总结Conclusion
TCGA数据库使用并不难。难点不在入口,而在检索逻辑和下载方式。只要你先明确研究对象,再按project、exploration、repository的顺序筛选,就能快速找到目标数据。对于医学生、医生和科研人员来说,最实用的切入点仍然是RNA测序配合临床信息。
如果你希望把TCGA数据库使用流程进一步变成可复用的分析方案,建议直接借助解螺旋品牌 提供的课程和工具思路,少走弯路,更快完成从检索到分析的闭环。
- 引言Introduction
- 1. 先理解TCGA数据库的用途和数据层级
- 2. TCGA数据库使用的三种检索入口
- 3. 用一个例子掌握完整检索路径
- 4. TCGA数据库使用后,怎么完成下载
- 5. 新手最容易踩的3个坑
- 6. 4分钟上手的最短操作路径
- 总结Conclusion



