引言Introduction
TCGA数据下载看似简单,真正难点在于选对模块、选对数据类型、避免下载后无法直接分析。对医学生、医生和科研人员来说,最常见的问题是样本太多、字段太杂、临床信息不好对齐。
如果你想快速拿到可用于生信分析的TCGA数据,先要理解下载入口、数据格式和工具选择。 这篇文章按实战流程讲清楚 tcga数据下载 的核心步骤。
1. 先搞懂TCGA数据从哪里来
1.1 三个检索入口,决定你能不能顺利下载
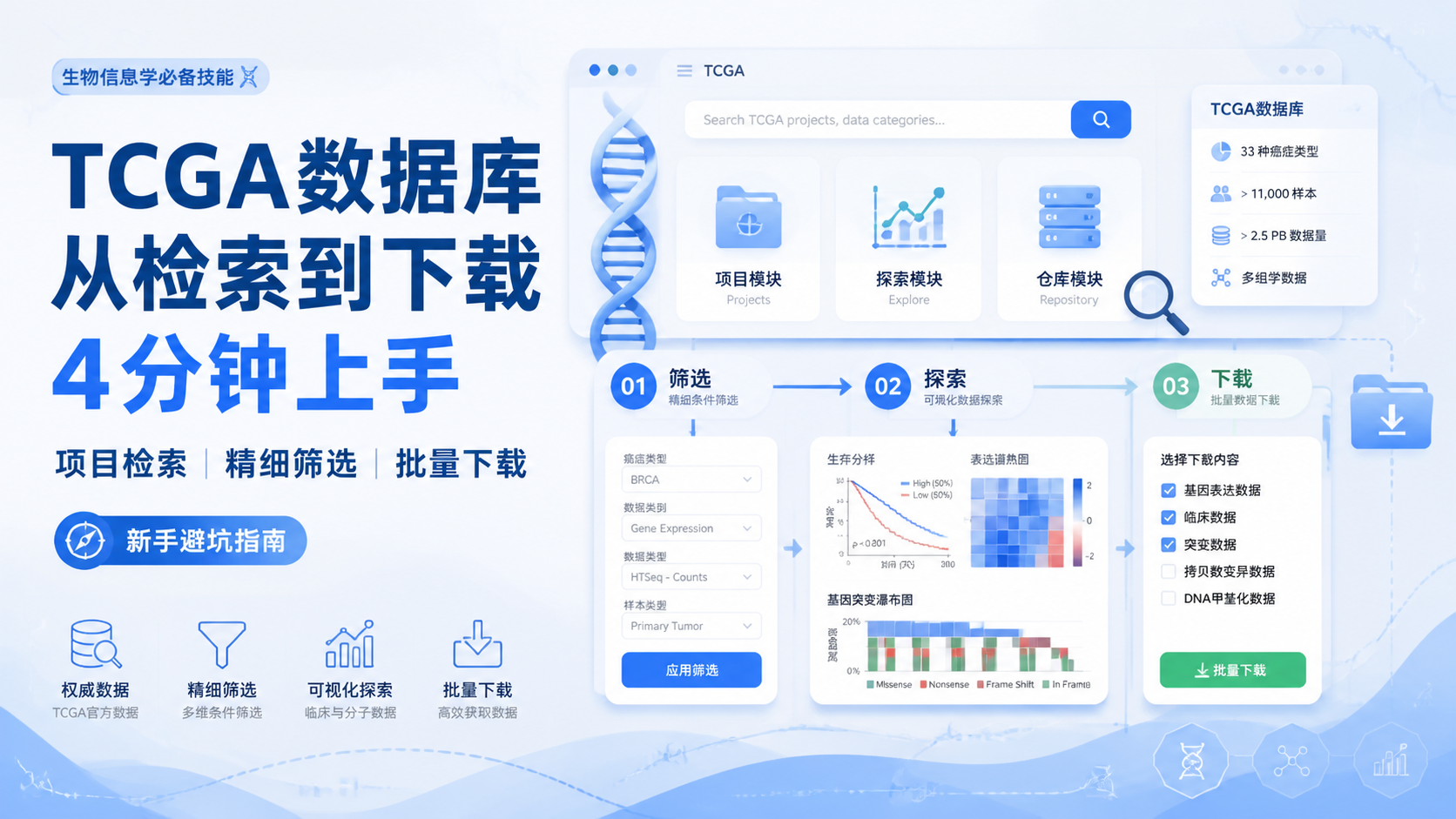
TCGA官网常用的检索方式有三种,分别是 project、exploration 和 repository。
其中,project 更适合按项目、疾病类型、数据分类和实验策略去筛选。exploration 更适合按样本、基因、临床和突变信息查找。repository 则是最终统一进入下载的核心入口。
对大多数 tcga数据下载 场景来说,repository 是最实用的模块。 因为前两个模块筛到的数据,最后都要回到这里加入购物车再下载。
1.2 TCGA能下载哪些数据
TCGA改版后覆盖约67个肿瘤部位,包含20个项目,疾病类型约59种。
可下载的数据类型也很丰富,包括转录组测序、临床数据、DNA甲基化、蛋白组测序等。常见实验策略有 RNA测序、Micro RNA测序、甲基化芯片和单细胞测序。
如果你做的是表达谱分析,最常见的是 RNA测序数据。
如果你要做生存分析、分层分析或临床关联分析,临床数据同样必不可少。
2. 用project模块快速定位目标队列
2.1 按疾病和实验策略缩小范围
在 project 模块里,可以通过项目、原发部位、数据分类和实验策略逐层筛选。
例如做结肠癌 RNA测序分析时,可选择项目 TCGA,原发部位结肠,实验策略 RNA测序。筛选后再进入 repository 查看文件。
这一步的价值在于先锁定队列,再决定下载哪些样本。 这样能明显减少无关文件。
2.2 用GRAPH先看样本分布
页面右侧的 GRAPH 选项可以直接查看不同类型数据及样本数。
这对判断样本是否充足很有帮助,也能提前识别病理类型分布是否均衡。
对于需要分组比较的研究,建议先看样本规模,再决定是否继续下载。
如果样本数过少,后续差异分析和回归分析都容易不稳定。
3. 用exploration和repository精确筛选
3.1 exploration适合按临床和基因进一步过滤
exploration 提供四类检索方式,分别是 cases、genes、clinical 和 mutations。
如果你要限定年龄、分期、种族、治疗信息或暴露因素,就应该优先用 clinical。临床字段包括人口学资料、诊断资料、治疗情况和暴露因素。
例如,检索亚洲人、病理一期和二期的TCGA肝癌RNA测序数据时,可以在 cases 里选 TCGA LIHC,再在 clinical 中限定 HCC 病理分期和种族。随后进入 repository 下载。
3.2 repository是最终下载入口
repository 下分为 files 和 cases 两部分。
files 中可按 data category、experimental strategy、data type、workflow type、platform 等条件筛选。cases 中则可以继续按 primary site、program、disease type 以及临床信息筛选。
实际操作中,repository 往往是 tcga数据下载 的主战场。 因为它的筛选项最全,且所有数据最终都在这里加入购物车。
以 TCGA 肝癌 REC 数据为例,可在 cases 中设置 program 为 TCGA,project 为 TCGA LIHC,再在 files 中选择 experimental strategy 为 REC、access 为 open。筛选后即可看到对应文件数量,并批量加入购物车。
4. 选对下载方式,避免后期返工
4.1 网页购物车适合小样本
TCGA数据下载有三种常见方式。第一种是直接在网页购物车下载。
如果样本量较少,或者网络条件较好,这种方式最直接。
操作流程是先在 repository 中加入购物车,再点击右上角 CART,核对文件数、样本数、项目来源和文件大小,确认后下载。
这种方法简单,但大样本时效率不高。
4.2 GDC client适合批量下载
第二种方式是使用官方 GDC data transfer tool,也就是 GDC client。
它适合批量下载,尤其当样本量较大时,比网页直接下载更稳定。
常见步骤包括:
- 下载 GDC client 工具。
- 设置环境变量。
- 在命令行验证工具是否可用。
- 使用 manifest 文件执行批量下载。
验证是否配置成功,可在 CMD 中输入 GDC-client -h。 若能正常输出帮助信息,说明环境变量设置成功。
下载时常见命令是 gdc-client download -m manifest文件路径。
建议把工作目录切到英文路径,避免中文或空格造成报错。
4.3 替代网站适合整理后数据
第三种方式是使用替代网站,比如 UCSC Xena。
这类平台通常提供整理好的 TCGA 数据,适合不想从原始文件逐个合并的研究者。
对新手而言,这种方式门槛更低。
尤其在做表达矩阵、临床表型和生存分析时,往往更容易直接进入分析阶段。
5. tcga数据下载后的分析准备
5.1 下载前先确认数据层级
TCGA数据分为不同层级。常见思路是区分原始数据、比对文件和标准化后的表达矩阵。
如果你的目标是差异表达、分组比较或联合临床分析,通常更需要已经整理好的矩阵数据,而不是分散的原始文件。
很多下载失败并不是工具问题,而是数据层级选错了。 这会导致后续还要重复处理。
5.2 临床数据要和表达数据对应
临床信息里包含年龄、性别、分期、治疗和生存结局等内容。
这些字段是做 E-E-A-T 风格研究设计时最重要的基础变量。
下载后建议先检查:
- 样本ID是否能匹配
- 临床变量是否完整
- 组间样本数是否足够
- 是否存在缺失值或重复样本
如果这些基础问题没处理好,后续统计分析会非常被动。
所以 tcga数据下载 的终点不是“拿到文件”,而是“拿到可分析的数据”。
5.3 对新手更推荐标准化流程
对于刚入门的科研人员,直接从官网原始数据开始处理,工作量会很大。
因为文件分散、格式不统一,有些数据还需要额外合并和清洗。
更稳妥的路径是:
- 先用 project 或 exploration 定位队列。
- 再在 repository 精确筛选。
- 优先下载表达矩阵和临床数据。
- 最后确认样本对应关系,再进入统计分析。
这套流程能显著降低返工率。
也更适合用于论文前期的数据准备。
总结Conclusion
TCGA数据下载并不难,关键是先选对入口,再选对数据类型,最后选对下载工具。
对于大多数研究场景,建议先用 project 或 exploration 定位队列,再到 repository 统一下载。样本少可网页直下,样本多优先用 GDC client,想快速进入分析则可考虑 UCSC Xena 等整理型平台。
如果你希望把 tcga数据下载、样本整理和后续分析流程做得更快更稳,可以借助解螺旋品牌的标准化工具和课程资源,减少重复试错,把更多时间留给结果解读。 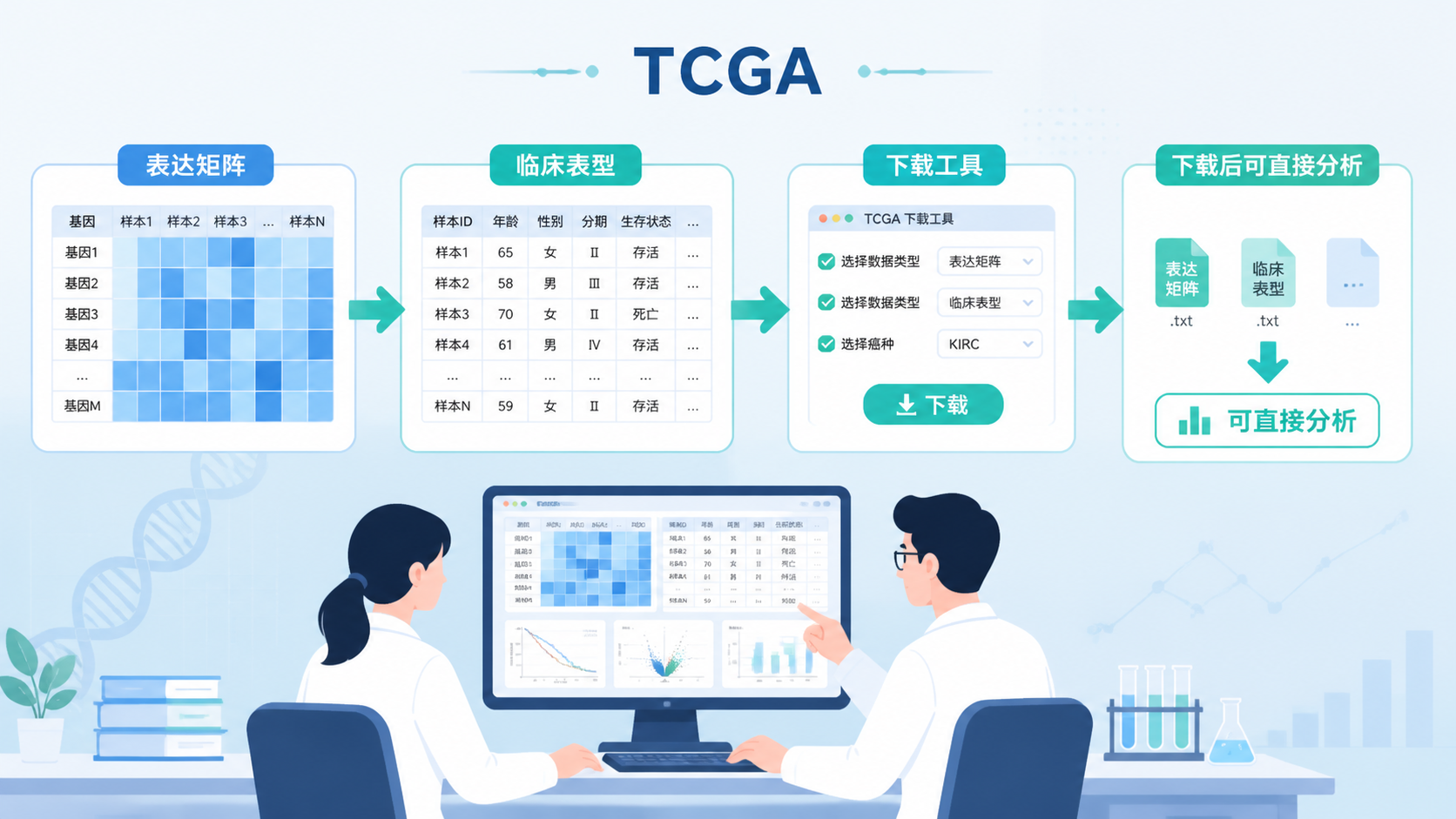
- 引言Introduction
- 1. 先搞懂TCGA数据从哪里来
- 2. 用project模块快速定位目标队列
- 3. 用exploration和repository精确筛选
- 4. 选对下载方式,避免后期返工
- 5. tcga数据下载后的分析准备
- 总结Conclusion