引言Introduction
甲基化水平数据看起来只是一个百分比,但背后常常对应基因沉默、表型差异和疾病机制。对医学生、医生和科研人员来说,真正的难点不是“测出来”,而是“怎么解释”。如果你只看均值,很容易忽略位点、分组和表达联动。
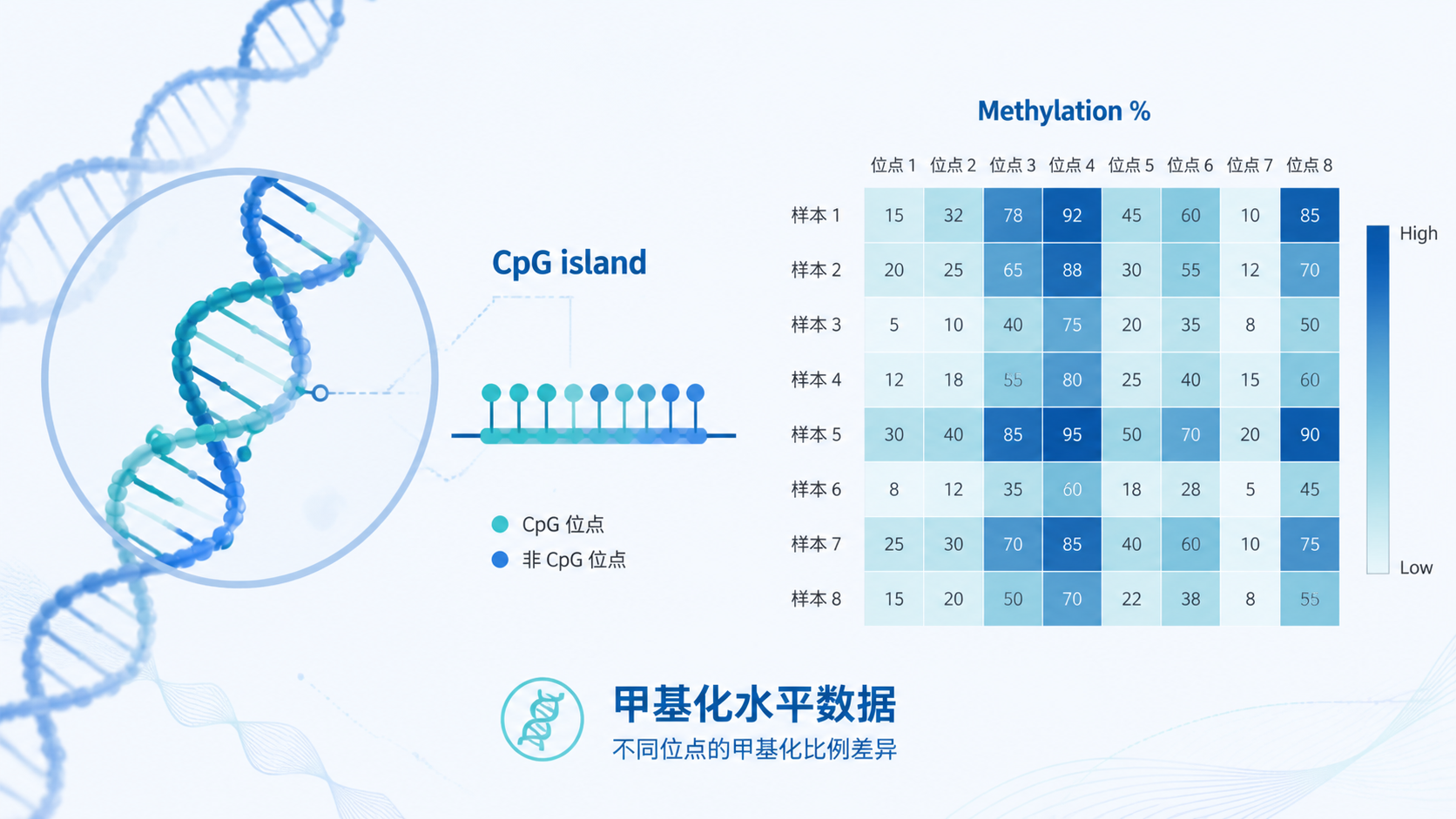
1. 先看甲基化水平数据来自哪里
1.1 明确检测对象
甲基化水平数据最常见的来源,是启动子区域或CpG岛位点。不同研究会选不同层级。比如,启动子甲基化常用于推断基因转录是否被抑制。文献中提到的TGF-β1、XPO4,都是围绕启动子区域展开分析。
第一步不是看结果,而是先确认:测的是全基因组、候选基因,还是某个具体位点。
如果对象不同,解释逻辑也不同。全基因组更偏模式分析。位点级数据更适合机制推断。
1.2 理解数据类型
甲基化水平数据可能来自重亚硫酸盐测序、焦磷酸测序、MSP等方法。不同方法的分辨率不同。位点级数据更细,适合做差异分析和相关性分析。
在甲基化研究里,核心往往是“位点选择”和“甲基化水平差异”。这是判断数据是否有生物学意义的前提。
2. 看差异,但不要只看均值
2.1 关注分组比较
甲基化水平数据最常见的解读方式,就是病例组和对照组比较。比如某研究中,PCOS患者在TGF-β1启动子CpG4位点甲基化显著降低。另一篇研究则提示,XPO4启动子甲基化升高,并且与mRNA表达呈负相关。
只要看到“显著差异”,下一步就要问:差异发生在几个位点,是否集中在功能区。
如果差异位点位于启动子核心区,它对转录调控的解释力度通常更强。
2.2 结合分层分析
单纯比较总体甲基化率,有时会掩盖亚组效应。文献里常见做法是按表型分层,比如按胰岛素抵抗、年龄、BMI等指标分组。这样能看到甲基化水平数据是否与临床表型同步变化。
在PCOS研究中,作者不仅比较了总体甲基化率,还进一步分析了不同甲基化水平下的临床指标差异。这一步的价值在于把“相关”变成“更接近机制”。
3. 重点看位点,而不是只看整体甲基化率
3.1 位点差异比整体均值更有解释力
甲基化水平数据常有一个误区,就是把多个CpG位点简单平均。这样会丢失关键位点信息。实际上,某一个位点的变化,就可能决定整个启动子状态。
例如,文献中提到TGF-β1启动子CpG4和CpG7位点的低甲基化,可能与PCOS的胰岛素抵抗机制相关。
如果一个位点变化明显,而其他位点不变,这个“局部信号”往往比总平均更值得追踪。
3.2 关注功能区
优先看这些区域:
- 启动子区。
- TSS附近。
- CpG岛核心区。
- 转录因子结合相关区域。
这些区域的甲基化变化,更可能影响转录。一般而言,启动子高甲基化更常与转录沉默相关,低甲基化则可能与表达激活相关。
但要注意,这不是绝对规则,最终仍需结合mRNA和蛋白水平验证。
4. 一定要和表达、临床指标联动解读
4.1 看甲基化与表达是否负相关
甲基化水平数据最有价值的地方,不是孤立数值,而是与表达的关系。
在XPO4相关研究中,启动子甲基化升高与mRNA表达降低呈负相关。这符合常见的转录调控逻辑。
在METTL14-FTH1相关研究中,m6A甲基化改变了mRNA稳定性,进而影响表达和铁死亡过程。虽然机制类型不同,但核心思路一致:修饰水平改变,最终要落到表达和功能上。
4.2 看是否与临床指标相关
临床科研中,甲基化水平数据最好同时分析年龄、BMI、胰岛素、HOMA-IR、血糖等指标。
文献中TGF-β1甲基化率与年龄呈正相关,与空腹胰岛素和HOMA-IR呈负相关。这提示甲基化不仅是分子现象,还可能与代谢表型有关。
建议的阅读顺序是:
- 先看甲基化差异。
- 再看表达变化。
- 最后看临床相关性。
这三步能帮助你判断,甲基化水平数据到底是“伴随现象”,还是“潜在机制节点”。
5. 用一套固定逻辑判断数据是否可信
5.1 先看样本和设计
样本量、分组方式、是否有家系背景、是否做了多组比较,都会影响甲基化水平数据的解释。
例如,家系研究和普通病例对照研究,结论外推范围不同。前者更适合发现易感位点,后者更适合验证群体差异。
5.2 再看统计和验证
解读时要关注:
- 是否做了位点级统计。
- 是否报告了显著性。
- 是否有表达验证。
- 是否存在机制上的闭环。
如果只有甲基化差异,没有mRNA或蛋白验证,结论通常只能停留在“相关”。
如果再加上功能注释、相关性分析和表达验证,甲基化水平数据的说服力会明显增强。
5.3 最后看生物学一致性
当你看到“启动子高甲基化,表达下降”,这是比较符合经典模型的。
但如果方向相反,也不一定错误。此时就要回到位点、组织类型和调控网络本身去解释。甲基化不是独立信号,它只是调控网络的一部分。
总结Conclusion
甲基化水平数据的解读,关键不在“数值大小”,而在“位点、分组、表达、临床”四者是否形成闭环。先看检测对象,再看差异位点,再看表达联动,最后结合临床指标和统计设计判断可信度。这样才能避免把甲基化数据读成孤立结果。
如果你正在做甲基化相关课题,或者需要把甲基化水平数据整理成更适合论文和汇报的表达方式,可以借助解螺旋品牌提供的生信与文献解读支持,把数据逻辑、图表解读和机制表达一次梳理清楚。
- 引言Introduction
- 1. 先看甲基化水平数据来自哪里
- 2. 看差异,但不要只看均值
- 3. 重点看位点,而不是只看整体甲基化率
- 4. 一定要和表达、临床指标联动解读
- 5. 用一套固定逻辑判断数据是否可信
- 总结Conclusion