引言Introduction
组蛋白修饰数据 不够清晰,常见问题是信号弱、背景高、验证链条断。对医学生、医生和科研人员来说,这会直接拖慢课题推进。本文结合分子修饰研究思路,整理7个可执行策略,帮助你把组蛋白修饰数据做得更稳、更有说服力。
1. 先把研究问题收窄
1.1 从“广筛”转向“明确主变量”
做组蛋白修饰时,最怕一开始就铺得太大。先明确你研究的是哪类修饰,再决定技术路线。常见的是乙酰化、甲基化,也可结合磷酸化相关信号通路分析。问题越聚焦,组蛋白修饰数据越容易形成闭环。
1.2 优先选择能解释表型的修饰
如果目标是讲机制故事,建议先让表型清楚,再去追修饰变化。比如先在细胞模型中复现已知表型,再观察组蛋白修饰是否随之改变。这样比单纯比较病例组和对照组,更容易建立因果链。
2. 选对技术平台
2.1 高通量负责发现
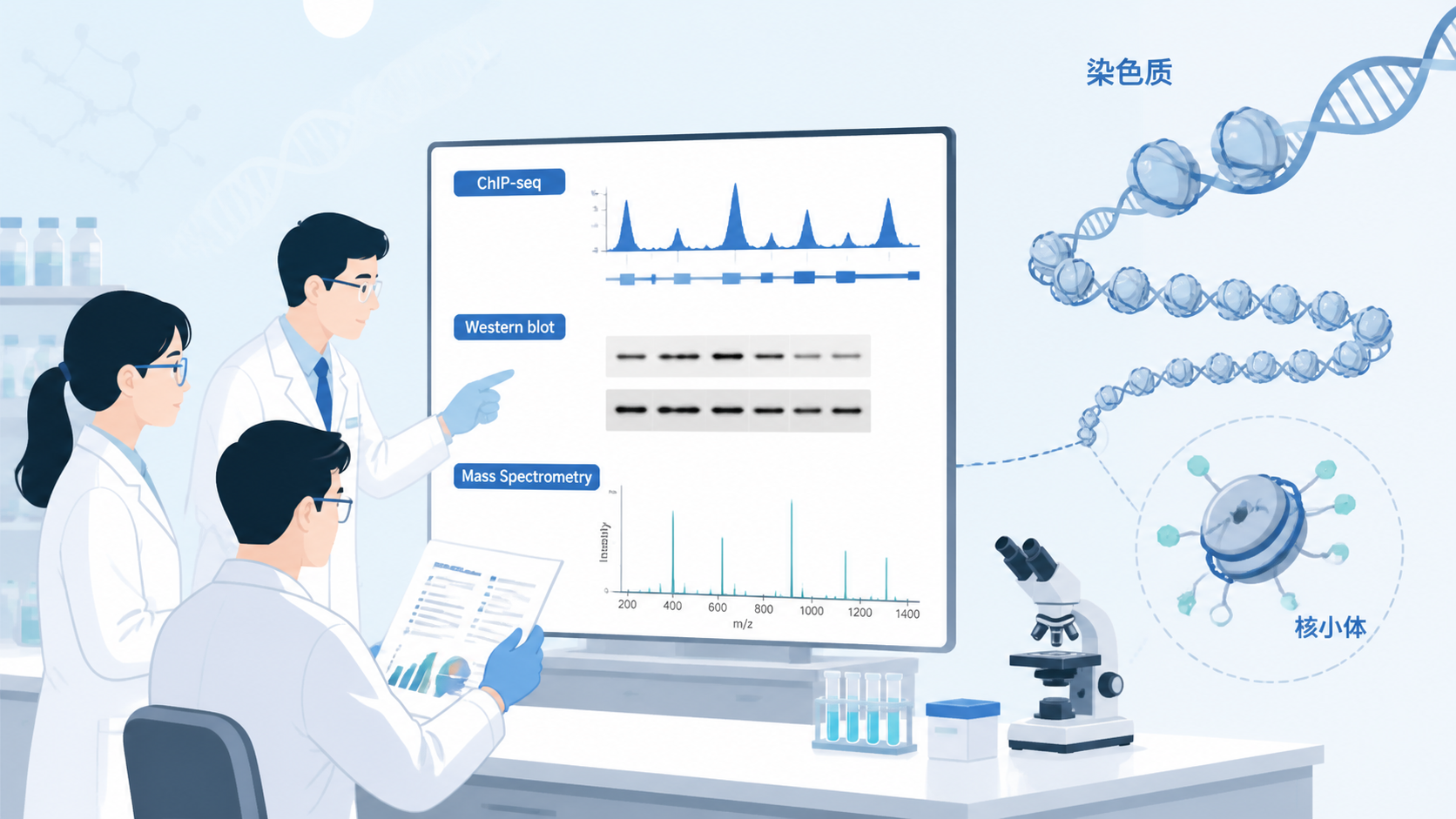
组蛋白修饰数据的第一步通常是筛选。高通量手段适合找候选区域和候选通路。若研究的是组蛋白甲基化或乙酰化相关位点,可结合测序或组学平台先做全局扫描。高通量的价值在于找线索,不在于直接下结论。
2.2 靶向验证负责定论
筛出来之后,必须回到验证层面。Western blot、ChIP相关实验、质谱验证,都比单一结果更可靠。对组蛋白修饰来说,最好同时有修饰水平变化和表达水平变化的证据。这样结论更完整,也更符合E-E-A-T要求中的可验证性。
3. 强化对照设计
3.1 必须设置清楚的比较组
很多组蛋白修饰数据不稳,根源不是技术差,而是对照不严。至少要区分处理组、模型组、空白组。若有修饰酶参与,还应加入过表达、敲低或催化失活组。没有清晰对照,修饰变化很难解释。
3.2 把“修饰”和“表达”分开看
知识库提示,修饰影响表达,比只影响分子交互更容易论证。放到组蛋白修饰研究中也是如此。要同时看染色质状态和下游基因表达。这样才能回答“这个修饰到底有没有功能”。
4. 盯住“写入酶”和“去除酶”
4.1 先锁定上游调控者
做组蛋白修饰数据时,不要只盯着修饰本身。更重要的是谁在写、谁在擦。比如乙酰化常与去乙酰化酶相关,甲基化则涉及甲基转移酶和去甲基化酶。上游酶的变化,往往比单个修饰点更有机制价值。
4.2 用功能干预证明因果
建议采用过表达和抑制双向策略。若修饰酶改变后,组蛋白修饰水平和下游表型同步变化,机制链就更完整。若再加入催化结构域失活或位点突变,证据会更强。
5. 盯紧表达一致性
5.1 不一致不是坏事,但要解释
在分子修饰研究里,mRNA和蛋白不一致很常见。对组蛋白修饰数据来说,也要关注修饰变化是否对应靶基因表达变化。若修饰增强但转录未变,就要考虑位点选择、时间窗或细胞状态。
5.2 优先验证稳定性和转录效应
知识库强调,修饰直接影响稳定性,比只影响交互作用更容易论证。组蛋白修饰研究中,也建议优先看对转录活性、染色质开放程度和稳定表达的影响。这类结果更容易形成可发表的机制故事。
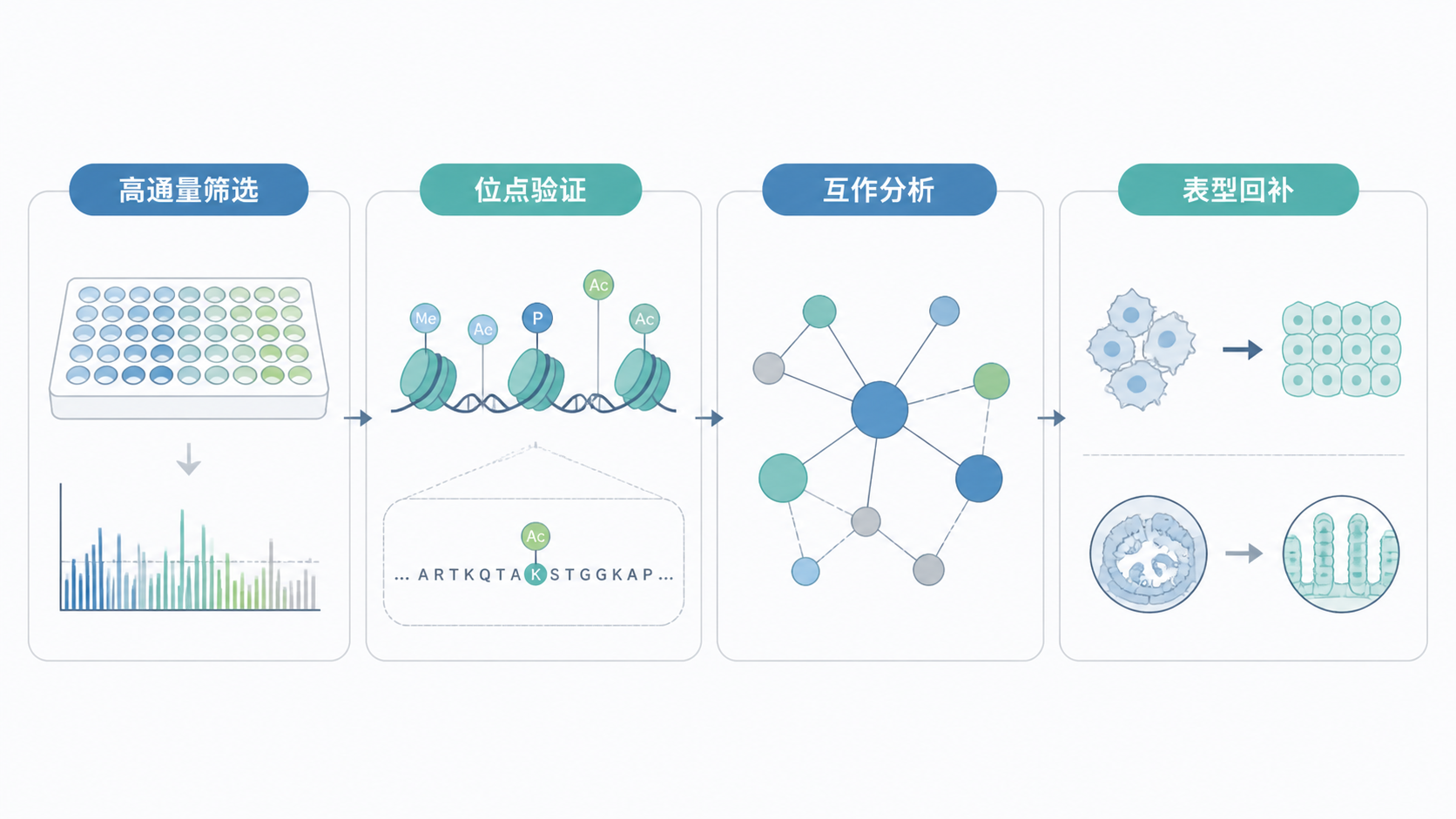
6. 用位点突变提升说服力
6.1 让证据指向特定位点
如果已有明确修饰位点,最好做位点突变。比如把关键赖氨酸位点突变后,看修饰是否消失、表型是否回撤。这样能把“相关”推进到“依赖”。
6.2 配合双向互作验证
若研究涉及修饰酶和底物蛋白的关系,可补充互作证据。Co-IP、双向验证、突变回复,都能增强组蛋白修饰数据的可信度。位点突变加互作验证,是提升数据质量的核心组合。
7. 让数据回到课题故事
7.1 机制要简洁,不要贪多
高通量研究常见问题不是候选太少,而是太多。组蛋白修饰数据也一样。建议只保留最能解释表型的一条主线。修饰类型、上游酶、下游靶基因,三者之间能闭环即可。
7.2 细胞和动物层面要互相支撑
如果条件允许,细胞实验后尽量补动物验证。这样组蛋白修饰数据不仅有体外证据,还有体内支撑。对医生和科研人员来说,这类数据最能提高文章层次,也更利于后续转化。
总结Conclusion
提升组蛋白修饰数据,本质上是提升研究的清晰度、可验证性和因果链完整度。 你需要做的,不只是把信号做出来,而是把“修饰变化、表达变化、表型变化”串起来。
如果你希望更快拿到可发表的组蛋白修饰数据 ,可以借助解螺旋的课题设计与数据优化思路,把筛选、验证和机制闭环一步步做扎实。这样更省时间,也更容易形成高质量结果。
- 引言Introduction
- 1. 先把研究问题收窄
- 2. 选对技术平台
- 3. 强化对照设计
- 4. 盯住“写入酶”和“去除酶”
- 5. 盯紧表达一致性
- 6. 用位点突变提升说服力
- 7. 让数据回到课题故事
- 总结Conclusion