引言Introduction
启动子预测、启动子克隆和后续功能验证,最容易出错的不是算法,而是启动子数据格式 。同一段序列,方向写错、坐标写错、FASTA 头信息不完整,都会直接影响预测结果和实验设计。下面结合常用数据库流程,讲清楚如何规范书写。
1. 启动子数据格式的核心原则
1.1 先明确你要写的是什么
启动子数据格式不是单纯的DNA序列。它至少要回答三个问题。
- 这段序列来自哪个基因。
- 它对应哪个参考基因组版本。
- 它相对于TSS的起止位置是什么。
规范的启动子数据格式,必须能让别人直接复现你的序列来源。 这也是E-E-A-T里最关键的可验证性。
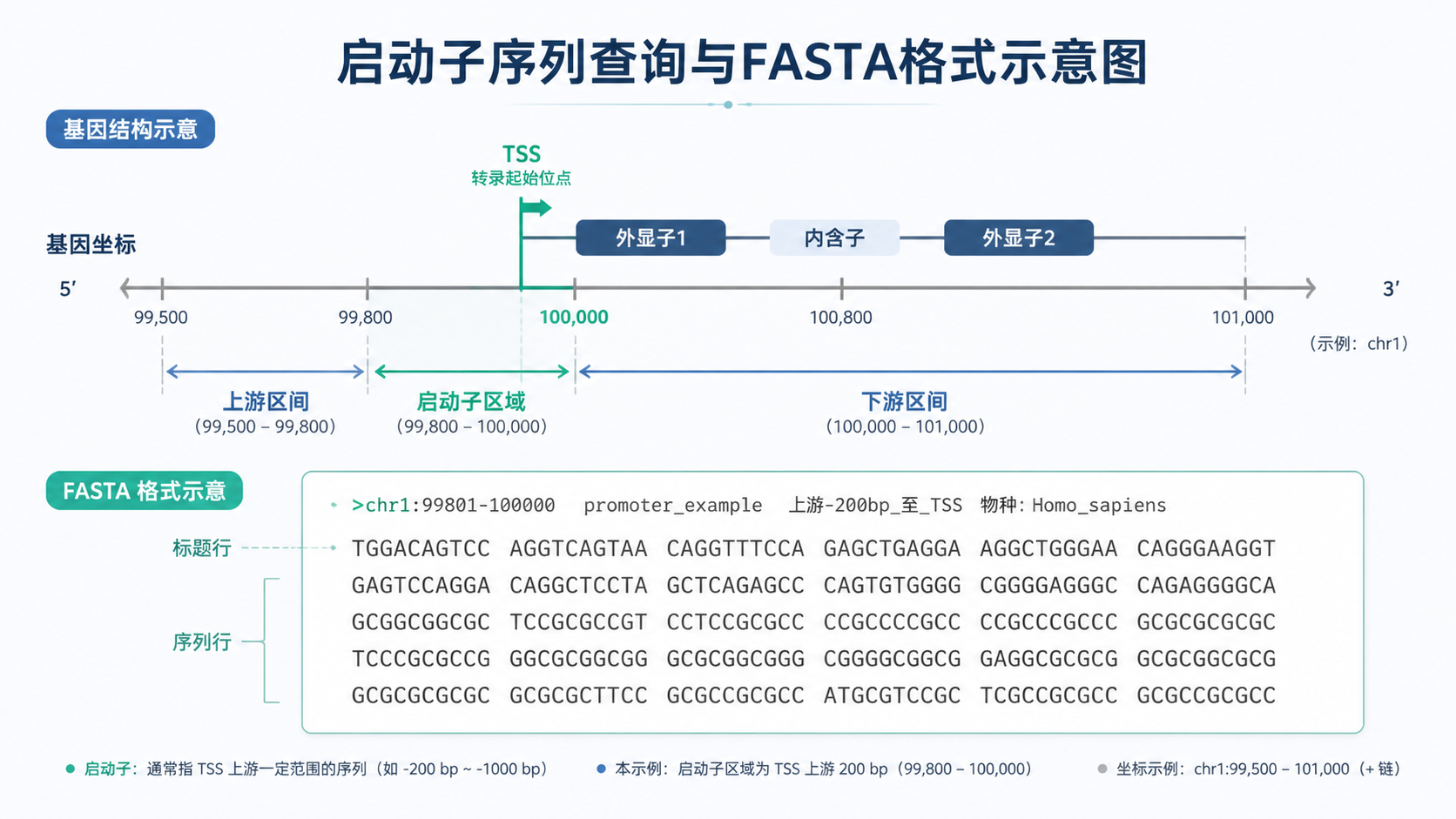
以人类PTEN为例,若已确认基因位于 Chr10: 87863625-87971930 ,且为正向转录,那么启动子区通常从转录起始位点上游取一定长度,再延伸到下游少量碱基。知识库中示例使用的是 上游3000 bp、下游100 bp ,即 87860625-87863725 。
这类信息写清楚,后续无论是数据库检索、序列提取,还是引物设计,都能对上。
1.2 坐标比序列更重要
很多人只贴一串序列,却不标注坐标。这样不规范。
标准写法应同时保留:基因名、染色体、链方向、参考版本、起止坐标、提取长度。
建议最少包含以下字段:
- Gene symbol
- Species
- Genome build
- Chromosome location
- Strand
- TSS position
- Promoter region coordinates
- Sequence length
如果是正链,常用写法是:
- 上游区间:TSS - 3000
- 下游区间:TSS + 100
如果是反义链,则要改成:
- 终点 + 3000
- 终点 - 100
方向写错,比少写一个碱基更致命。
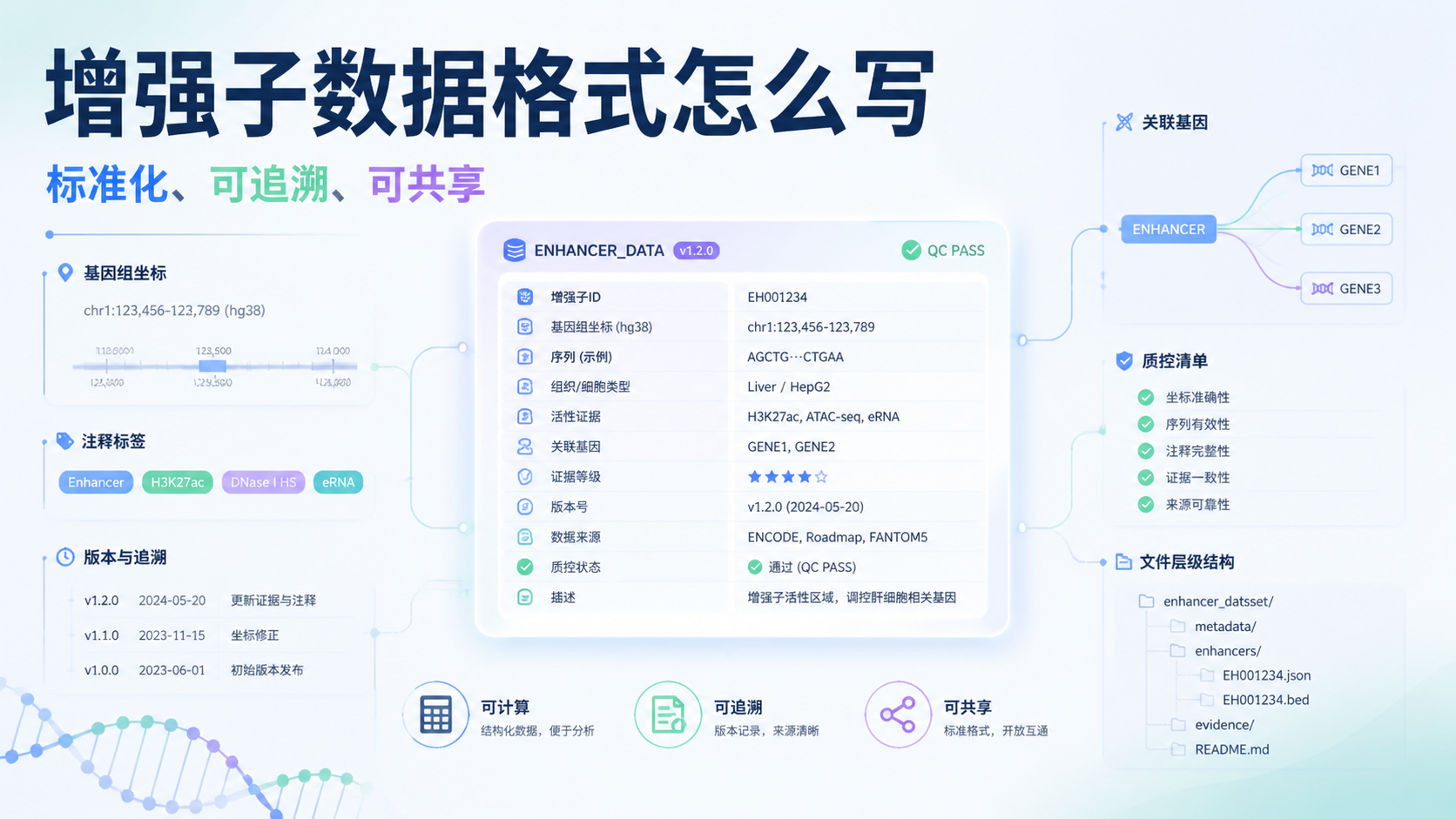
2. 启动子数据格式怎么写最规范
2.1 推荐的FASTA写法
启动子数据格式最常见的是FASTA。标准结构很简单:第一行是标题行,第二行开始是序列。
建议标题行至少包含这些信息:
- 基因符号
- 物种
- 参考基因组
- 区间坐标
- 链方向
例如:
>PTEN_Homo_sapiens_GRCh38_chr10_87860625-87863725_plus
NNNNNNNNNN
如果需要更专业,可以进一步写成:
>PTEN|Homo sapiens|GRCh38|chr10:87860625-87863725|plus|promoter_region
标题行越规范,后面做启动子预测、Motif分析和实验记录越省事。
2.2 序列行的规范要求
序列本身也有格式要求。
- 只写A、T、C、G。
- 不要混入空格、数字、中文标点。
- 不要把5’到3’方向写反。
- 长序列建议按固定长度换行,常用60或80个字符一行。
- 不要把未知碱基随意改写。
知识库中提到,像GenBank、Gene、UCSC、EPD这类数据库,都可以导出或截取启动子区序列。一旦来源明确,序列格式就必须统一。
2.3 方向标注必须一致
这是最常见的错误点。
正链基因:
- 以基因起始位点为基准。
- 向左取上游。
- 向右取少量下游。
反链基因:
- 以基因终止位点为基准。
- 方向相反。
- 仍要按转录方向定义上游和下游。
也就是说,“上游”是转录方向概念,不是简单的左边或右边。
写启动子数据格式时,不能只看染色体坐标大小,还要看链方向。
3. 启动子数据格式中最容易漏掉的字段
3.1 必须写清参考基因组版本
不同版本的参考基因组,坐标可能不同。
例如:
- GRCh38
- hg38
- current reference status
没有参考版本,坐标信息就不够完整。
做数据库查询时,版本不一致会导致区域偏移,尤其在精确定位TSS时非常麻烦。
建议在记录中统一写:
- Genome build: GRCh38
- Database source: NCBI Gene / UCSC / EPD
3.2 必须写清TSS与启动子边界
启动子并不等于整个上游区域。很多实验只需要核心启动子或某个候选片段。
可分两层写法:
- 广义启动子区 :TSS上游3000 bp到下游100 bp
- 核心启动子区 :TSS附近约-25 bp到+50 bp
知识库明确指出,核心启动子通常位于 TSS上游约25 bp 到下游50 bp 。
而上游的GC盒、CAAT盒等调控元件,往往分布在更靠上的区域。
所以,规范的数据格式应把这两层分开:
- promoter region
- core promoter region
3.3 必须记录数据来源
没有来源的数据格式,不适合直接进入课题组记录或文章补充材料。
推荐写法:
- NCBI Gene database
- UCSC Genome Browser
- EPDnew database
如果是预测得到的结果,也要注明工具:
- Promoter 2.0
- Softberry FPROM
例如,Promoter 2.0 的结果解读中,score 和 likelihood 能提示转录起始位点在预测区域内的可能性。Softberry FPROM 则会输出是否存在含TATA盒或不含TATA盒的核心启动子。
4. 启动子预测前,数据格式为什么要先标准化
4.1 数据格式决定预测质量
启动子预测前,最关键的是先拿到正确的候选序列。
知识库给出的流程很清楚:
- 在NCBI Gene或UCSC中查询基因。
- 确认基因位置和链方向。
- 根据邻近上游基因间距,确定候选启动子范围。
- 提取FASTA序列。
- 再做预测。
如果这一步格式不标准,后面的预测就没有意义。
例如PTEN案例中,上游邻基因CFL1P1与PTEN起点相差 18013 bp 。因为间距较大,所以可以更宽一些地提取启动子区域。这个判断过程本身就依赖坐标表达是否规范。
坐标规范,是整个分析链条的起点。
4.2 Motif分析也依赖格式
启动子数据格式正确后,才能进一步找:
- TATA盒
- Initiator
- GC盒
- CAAT盒
知识库中提到,EPD中可以直接选择 Promoter Motifs,分别预测这些元件。
但前提是,你的输入序列边界已经定义清楚。
如果边界不清:
- TATA盒可能被截掉。
- 下游TSS附近序列可能缺失。
- 预测结果会偏离真实调控区。
4.3 实验设计更需要可追溯格式
后续做启动子报告基因载体构建时,通常要从基因组DNA中扩增启动子片段。
这时启动子数据格式不规范,会直接影响:
- 引物位置
- 扩增片段长度
- 克隆方向
- 报告载体插入是否正确
从数据库到实验台,格式一致性决定可重复性。
5. 一套可直接套用的标准模板
5.1 文本记录模板
建议你在实验记录或表格中按下面格式整理:
- Gene: PTEN
- Species: Homo sapiens
- Genome build: GRCh38
- Chromosome: chr10
- Strand: plus
- TSS: 87863625
- Promoter region: 87860625-87863725
- Length: 3101 bp
- Source: NCBI Gene / UCSC
- File format: FASTA
这个模板的价值在于,后续任何人都能快速复查。
5.2 FASTA模板
>PTEN|Homo sapiens|GRCh38|chr10:87860625-87863725|plus|TSS=87863625
ATG...
如果是用于提交数据库或软件分析,建议再补充:
- transcript ID
- promoter type
- extraction rule
例如:
- upstream 3000 bp, downstream 100 bp
- core promoter search window
5.3 表格模板
如果你要整理多个基因,表格比纯文本更高效。
| Gene | Species | Build | Chr | Strand | TSS | Region | Length | Source |
|---|---|---|---|---|---|---|---|---|
| PTEN | Homo sapiens | GRCh38 | chr10 | + | 87863625 | 87860625-87863725 | 3101 | NCBI Gene |
表格化管理,是最适合科研团队协作的启动子数据格式。
总结Conclusion
启动子数据格式的规范写法,核心不是“写得像不像”,而是能不能被复现、能不能被验证、能不能直接用于预测和实验 。最少要写清基因名、物种、参考版本、链方向、TSS、坐标区间和序列来源。FASTA标题行也要同步标准化。这样,后续无论是NCBI、UCSC、EPD查询,还是Promoter 2.0、Softberry FPROM分析,都能减少错误。
如果你希望把启动子查询、序列提取、预测和实验设计串成一套更高效的流程,可以借助解螺旋 的科研内容与工具支持,统一管理启动子数据格式,减少重复整理时间,提高课题推进效率。
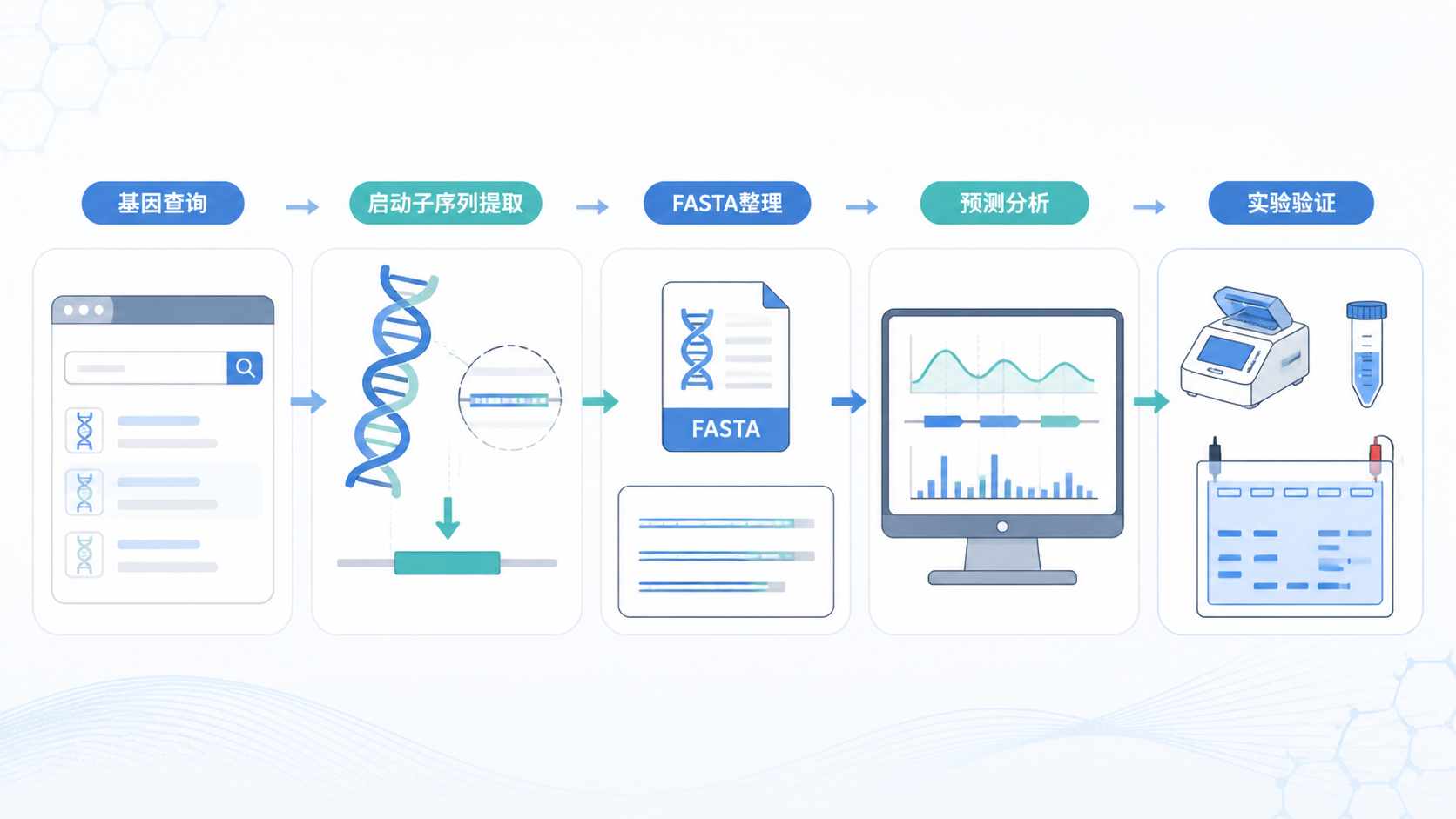
- 引言Introduction
- 1. 启动子数据格式的核心原则
- 2. 启动子数据格式怎么写最规范
- 3. 启动子数据格式中最容易漏掉的字段
- 4. 启动子预测前,数据格式为什么要先标准化
- 5. 一套可直接套用的标准模板
- 总结Conclusion