引言Introduction
增强子数据格式怎么写,常常卡在“信息不全、字段不统一、难以复用”这三个问题上。对医学生、医生和科研人员来说,增强子数据格式 不仅影响数据库整理,也直接影响后续分析、注释和共享效率。

1. 先明确增强子数据格式的核心目标
1.1 不是“写记录”,而是“可计算、可追溯、可共享”
增强子数据格式的第一原则,是让数据能被程序稳定读取,也能被研究者快速理解。很多人只记录一个基因组坐标,但这远远不够。
一个合格的增强子数据格式,至少要回答三个问题:它在哪里,它来自哪里,它支持什么结论。
在实际研究中,增强子常常来自 ChIP-seq、ATAC-seq、DNase-seq、H3K27ac 以及文献整合结果。不同来源的数据,如果没有统一格式,后续做交叉验证会非常困难。
因此,增强子数据格式不能只看“有没有”,更要看“能不能对齐、过滤、复现”。
1.2 基础字段要完整,避免信息断层
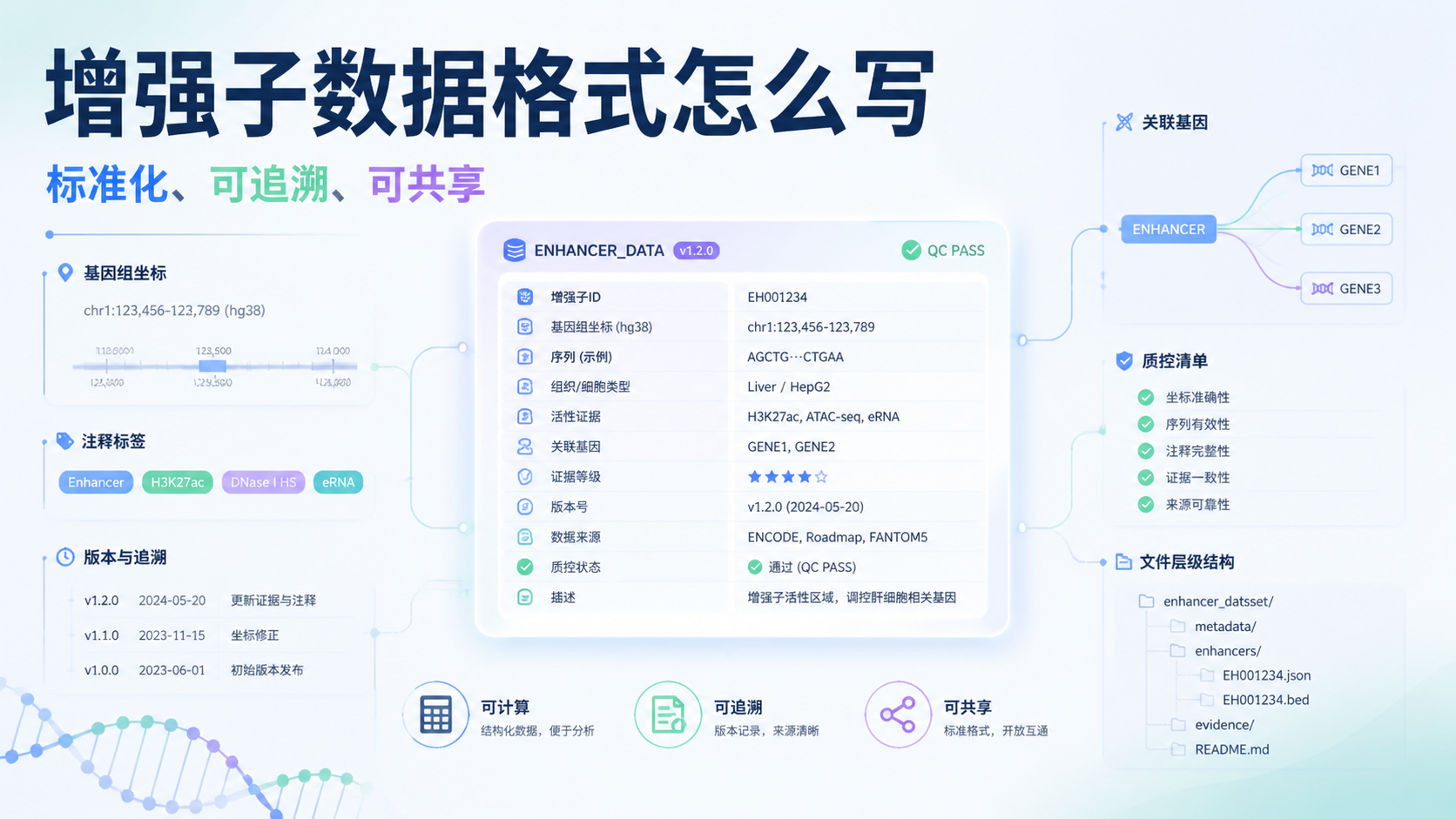
增强子数据格式通常应包含以下核心字段:
- 增强子编号
- 染色体编号
- 起始位置
- 终止位置
- 正负链信息
- 数据来源
- 实验类型
- 细胞类型或组织来源
- 证据等级或置信度
- 注释说明
这些字段不是越多越好,而是越关键越不能缺。坐标信息决定定位,来源信息决定可信度,证据信息决定可用性。
如果后续要做数据库入库或批量分析,还建议增加统一命名规则,避免同一个增强子在不同文件里出现多个名称。
2. 按标准化思路设计增强子数据格式
2.1 推荐采用“主表+注释表”结构
对于科研场景,最稳妥的方式是把增强子数据格式拆成两部分。
第一部分是主表,只保留最核心、最稳定的定位信息。第二部分是注释表,用于保存实验细节、功能预测和文献证据。
这样做的好处很明确。
主表便于程序读取,注释表便于人工理解。
例如,主表可用于基因组浏览器展示,注释表可用于下游富集分析、功能筛选和论文补充材料。
一个实用的主表字段示例包括:
- enhancer_id
- chr
- start
- end
- strand
- score
- source
注释表则可以扩展:
- assay_type
- cell_type
- tissue
- evidence
- target_gene
- pubmed_id
- note
2.2 坐标系统和版本号必须写清楚
很多增强子数据格式出问题,不是字段少,而是坐标体系混乱。
同样是 chr1:100000-100500,如果基于不同参考基因组版本,结果可能完全不同。
所以必须明确写出:
- 参考基因组版本,如 hg19 或 hg38
- 坐标是否为 0-based 或 1-based
- 染色体命名规则,如 chr1 还是 1
- 数据更新时间和版本号
这是增强子数据格式能否真正复现的关键。
如果省略这些信息,后续合并不同批次数据时,容易出现错位、重复和假阳性注释。
2.3 评分和证据等级要有统一标准
增强子并不是所有条目都同等可靠。某些增强子来自多组学交叉支持,某些只是预测结果。
因此,增强子数据格式最好加入 score 或 evidence level。
可以按以下逻辑记录:
- 1类证据:单一实验支持
- 2类证据:两种及以上实验支持
- 3类证据:整合数据库支持
- 4类证据:文献验证或功能实验支持
这样写的好处是,研究者在筛选时可以直接按证据层级排序。
对于需要用于机制研究、靶点分析或论文投稿的数据,这一步尤其重要。
3. 让增强子数据格式真正适合下游分析
3.1 文件格式要兼顾通用性和可读性
在实际工作中,增强子数据格式常见的保存方式包括 TSV、CSV、BED 和 GFF。
如果是面向基因组坐标浏览和批量注释,BED 格式最常用。如果是面向人工整理和共享,TSV 或 CSV 更直观。
选择时可以按用途判断:
- BED,适合基因组区间分析
- GFF,适合结构化注释
- TSV,适合科研协作和表格管理
- CSV,适合通用导入导出
不要在一个文件里混用多种表达方式。
例如,一部分坐标是整数,一部分带空格说明,一部分写成文本标签,这会明显增加后处理成本。
3.2 统一命名规则,减少重复和歧义
增强子数据格式最常见的问题之一,是同一条记录在不同项目里名称不一致。
比如有的写“Enhancer_001”,有的写“E001”,还有的直接写文献编号。这样会导致合并失败。
建议统一命名为:
- 项目缩写
- 组织或细胞类型
- 序号
- 版本号
例如:HepG2_E001_v1。
命名统一后,才能真正支持批量检索、版本管理和跨项目整合。
3.3 补充关联基因和功能说明,但不要过度推断
很多研究者会希望增强子数据格式里直接写上 target gene。这个思路可以保留,但要注意区分“预测关联”和“实验验证”。
增强子和靶基因之间可能跨越较远距离,也可能受三维染色质结构影响。
因此建议在字段里明确标注:
- predicted_target_gene
- validated_target_gene
- evidence_method
不要把预测结果写成确定结论。
这不仅影响科学严谨性,也会降低数据可信度。对医生和科研人员来说,这种区分非常重要。
4. 写增强子数据格式时最容易忽略的3个细节
4.1 缺少元数据
元数据包括样本来源、实验时间、分析流程和筛选阈值。
没有元数据,增强子数据格式就很难被复现。
尤其在多中心研究中,元数据往往比主结果更重要。
4.2 缺少质控信息
如果增强子来自高通量测序,最好记录基本质控指标,例如:
- reads 数量
- 比对率
- 峰值调用方法
- 阈值标准
这些信息能帮助判断数据是否可靠,也能解释不同批次之间的差异。
4.3 缺少版本管理
增强子注释会不断更新。数据库升级、基因组版本切换、文献补充,都会改变结果。
所以增强子数据格式最好保留:
- 创建日期
- 修改日期
- 版本号
- 维护人或团队
版本管理不是附加项,而是科研数据规范化的基础。
5. 一个实用的增强子数据格式模板
5.1 建议字段示例
下面是一套可直接参考的增强子数据格式模板:
| enhancer_id | chr | start | end | strand | genome_build | source | assay_type | cell_type | score | evidence_level | target_gene | pubmed_id | version |
|---|
这个结构的优点是清晰、可扩展、便于计算。
如果你需要用于论文补充材料,或者导入内部数据库,这类格式通常最稳妥。
5.2 写作时遵循的3个原则
第一,字段固定。 不要今天加一列,明天删一列。
第二,含义明确。 每一列都要有解释。
第三,来源可追溯。 每条记录最好能回到原始实验或文献。
这三点做好后,增强子数据格式就不仅是“表格”,而是可以支撑分析流程的数据资产。
总结Conclusion
增强子数据格式怎么写,本质上不是格式问题,而是规范化问题。
只要抓住三个要点,就能明显提升数据质量:字段要完整,坐标要标准,证据要可追溯。 再配合统一命名、版本管理和明确的元数据,增强子数据格式就能真正用于科研整合、机制分析和论文写作。
如果你正在整理增强子注释、构建数据库或准备投稿材料,可以借助解螺旋 的专业内容与科研支持,快速把分散数据整理成可复用、可验证、可发表的规范格式。

- 引言Introduction
- 1. 先明确增强子数据格式的核心目标
- 2. 按标准化思路设计增强子数据格式
- 3. 让增强子数据格式真正适合下游分析
- 4. 写增强子数据格式时最容易忽略的3个细节
- 5. 一个实用的增强子数据格式模板
- 总结Conclusion