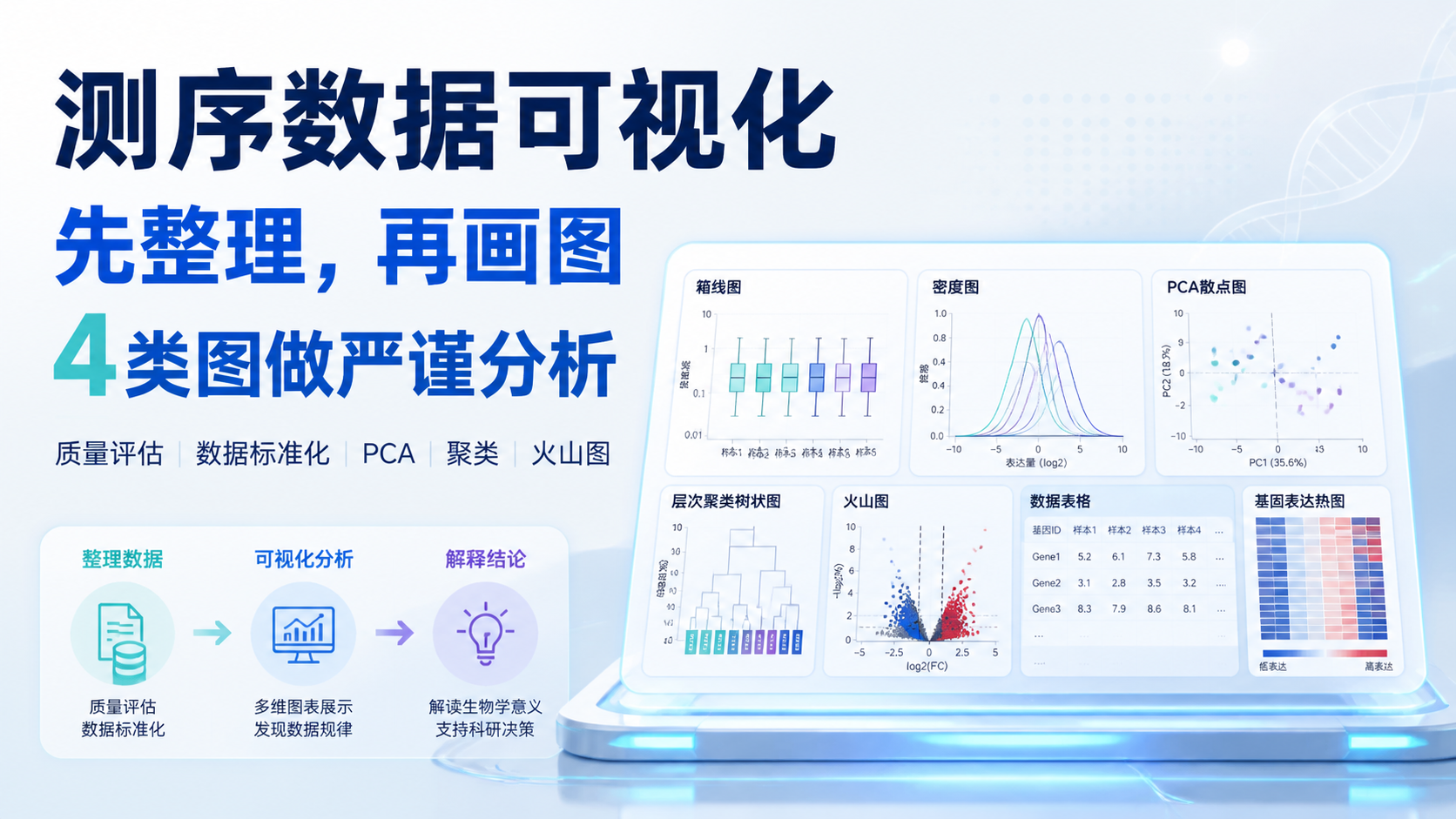
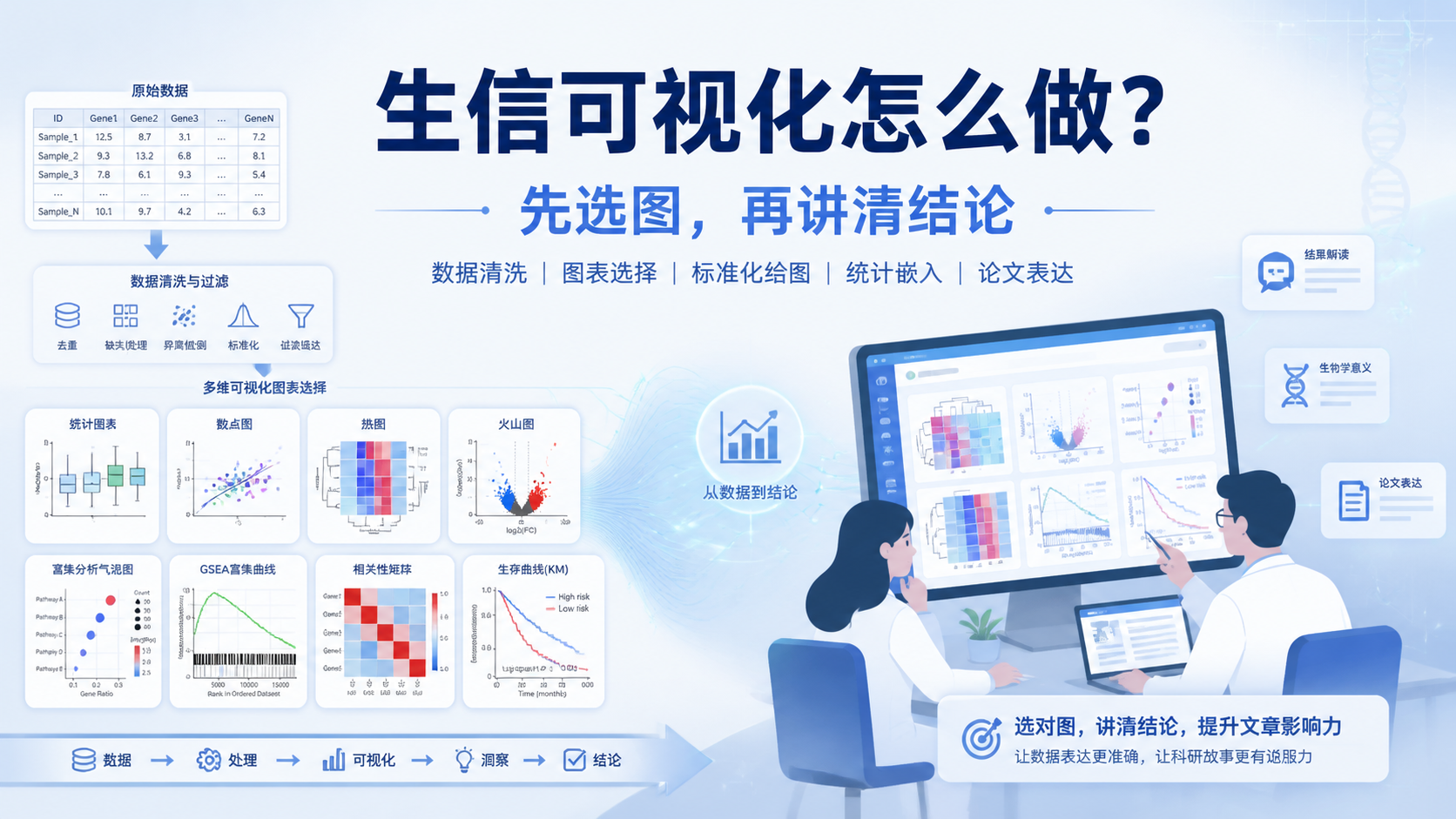
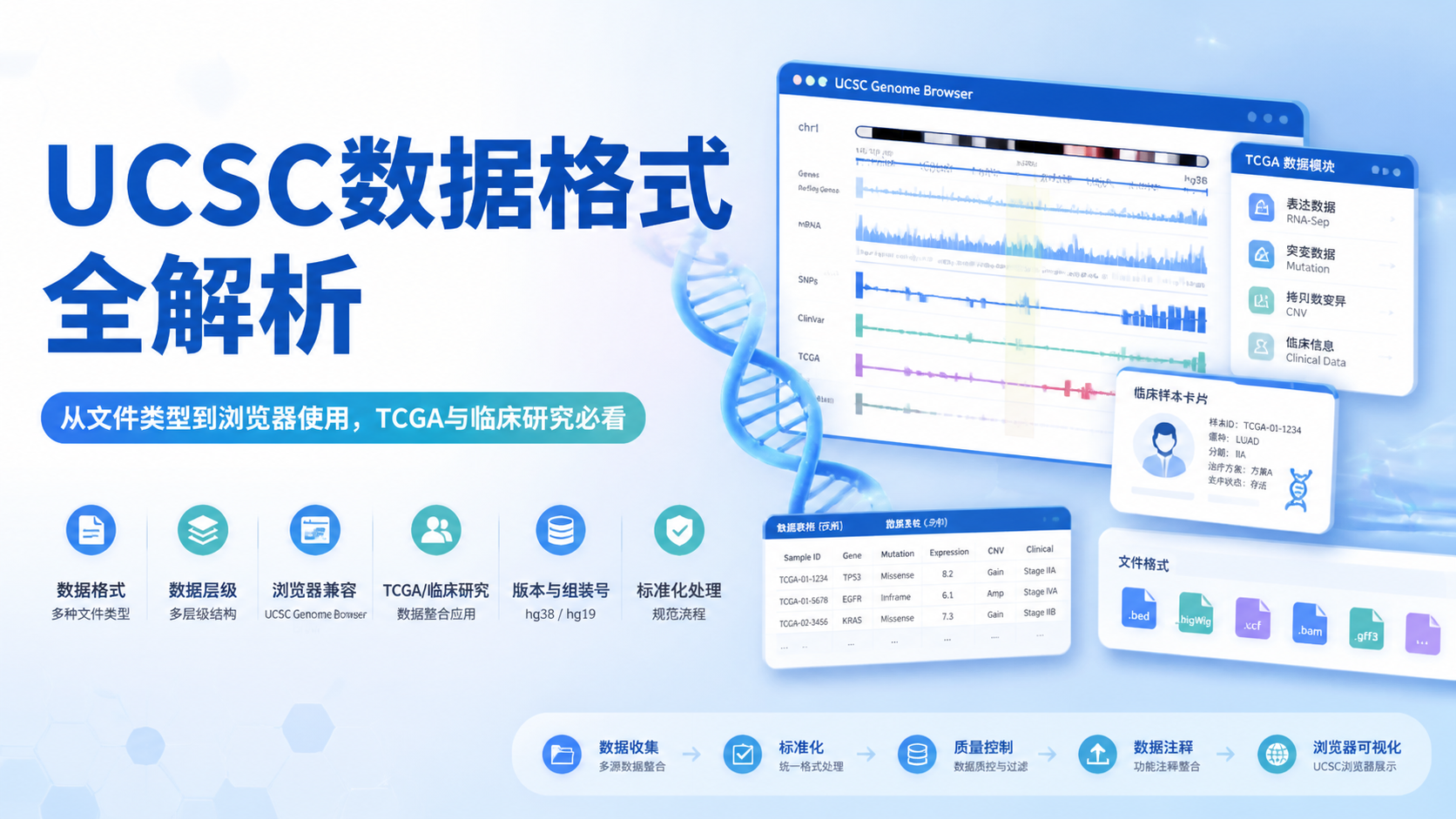
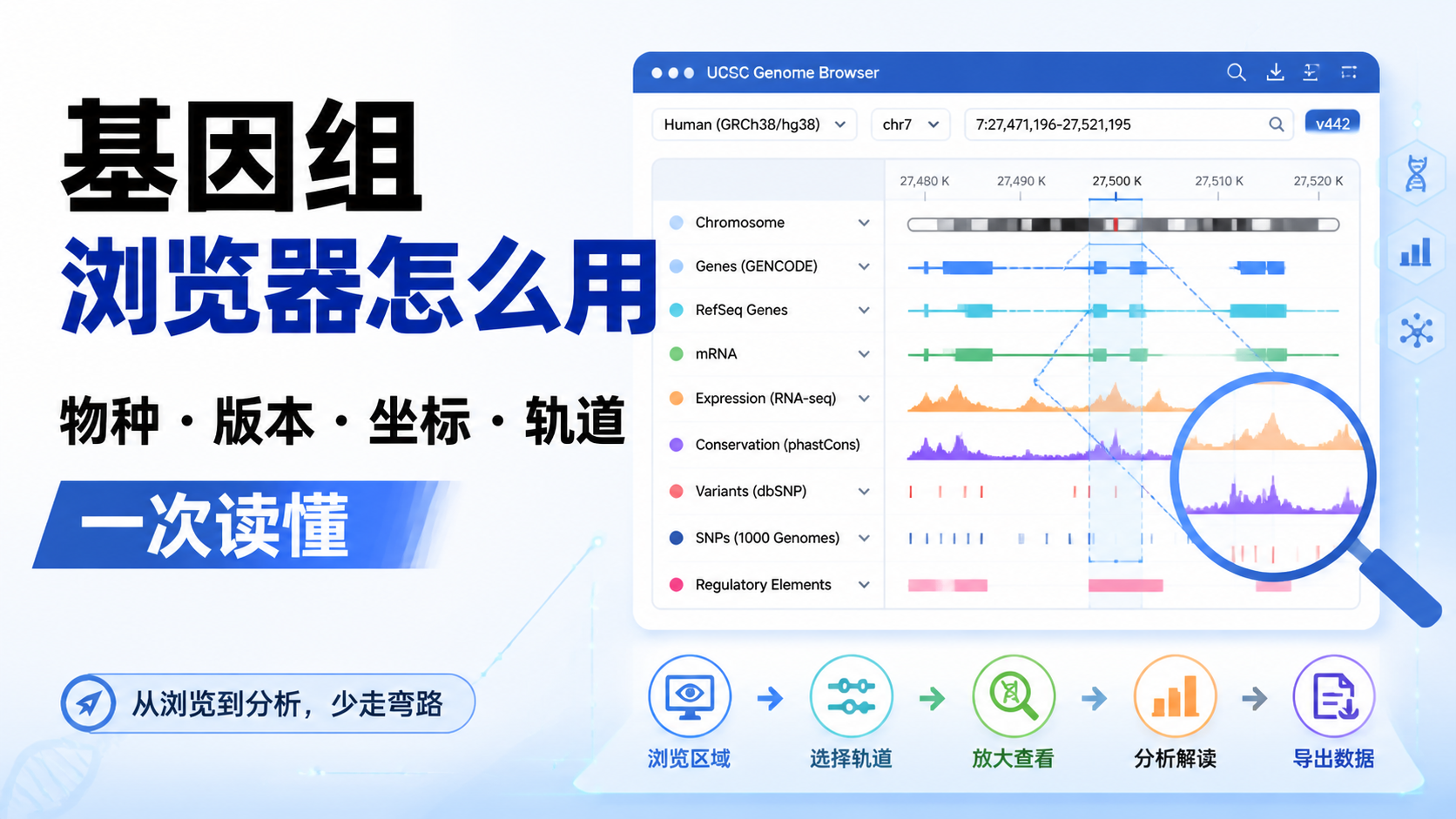
引言Introduction
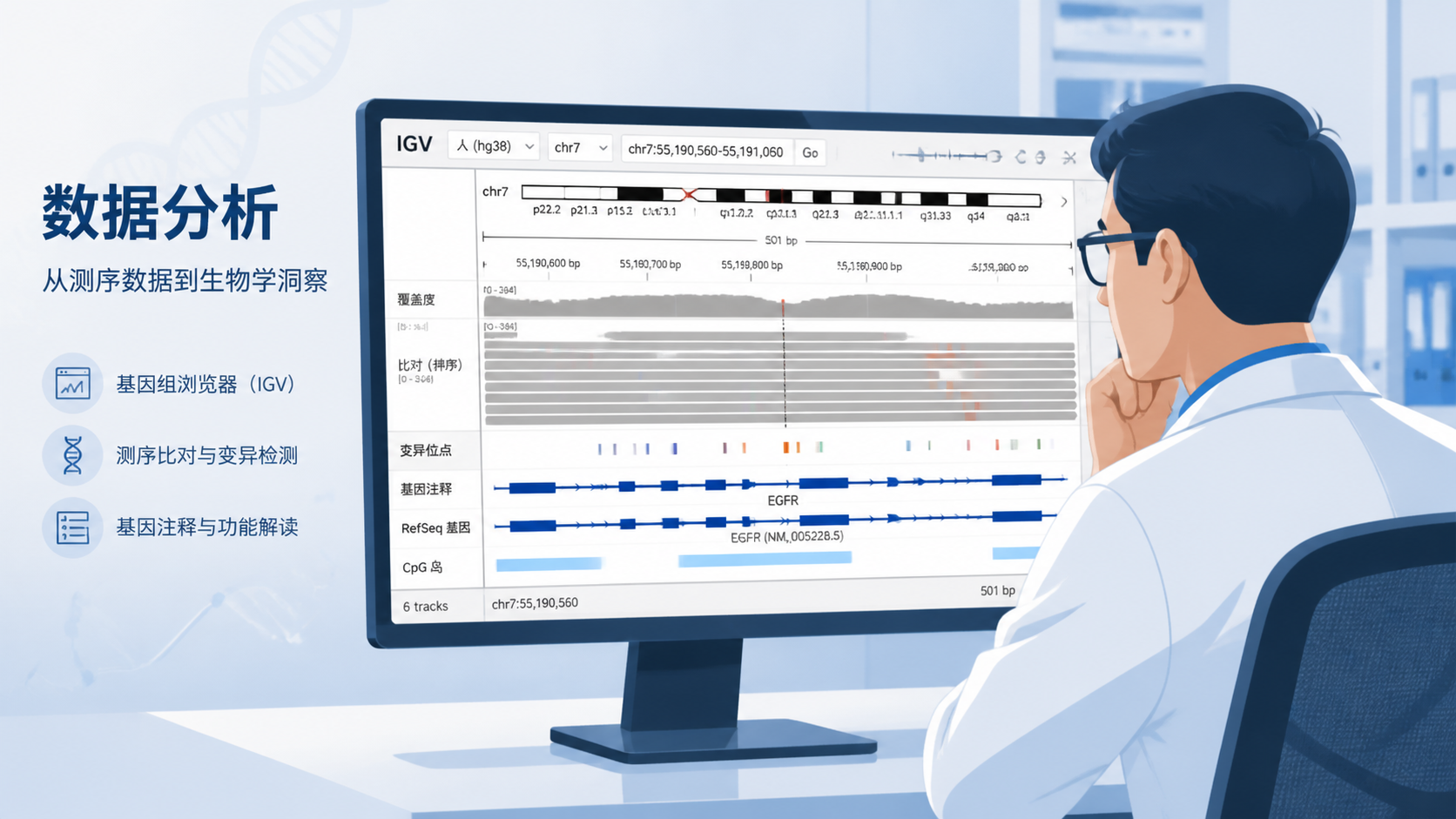
IGV数据格式 直接决定你能否快速、稳定地浏览基因组数据。很多医学生、医生和科研人员在使用IGV时,常遇到文件打不开、轨道显示异常、注释错位等问题。根源往往不是软件本身,而是格式不规范。掌握IGV数据格式,是提升分析效率的第一步。
1. 先理解IGV为什么“挑格式”
1.1 IGV本质上读取的是标准化基因组文件
IGV是基因组浏览器。它的核心任务,是把比对结果、变异信息、注释信息和信号轨道加载到同一视图中。要做到这一点,文件必须遵循明确的格式规则。
常见可被IGV加载的文件包括:
- BAM、CRAM,用于比对结果
- VCF,用于变异信息
- BED、GTF、GFF,用于基因组注释
- BigWig、BigBed,用于压缩后的轨道数据
- SAM、WIG、Genome files等,视版本和场景而定
IGV数据格式的关键,不只是“能打开”,而是“能正确索引、能准确显示、能稳定交互”。
1.2 格式错误通常来自三个环节
实际工作中,问题多出在数据生成、压缩索引和参考基因组三个环节。
常见异常包括:
- 染色体命名不一致,如“chr1”和“1”混用
- 文件未排序,导致无法建立索引
- 索引文件缺失,如.bai、.tbi、.csi
- 参考基因组版本不一致,如hg19和hg38混用
这些问题看似简单,却会直接影响IGV加载结果。因此,理解IGV数据格式,必须同时理解文件本身、索引和参考基因组的匹配关系。
2. 4步快速掌握IGV数据格式
2.1 第一步,先判断数据类型
不同研究目的,对应不同的IGV数据格式。
如果你看的是测序比对结果,优先使用:
- BAM或CRAM
- 对应索引文件.bai或.crai
如果你看的是变异位点,优先使用:
- VCF
- 对应索引文件.tbi或.csi
如果你看的是基因注释区域,优先使用:
- BED
- GTF或GFF
如果你看的是覆盖度或连续信号,优先使用:
- BigWig
- BigBed
先选对文件类型,再谈IGV数据格式,效率会高很多。
这一步能避免很多无效排查。
2.2 第二步,确认文件是否适合IGV加载
IGV对文件的基本要求很明确。文件通常需要满足三点:
- 内容标准
- 排序规范
- 索引齐全
以BAM为例,文件一般需要经过比对、排序,再建立索引。没有索引,IGV无法快速定位到指定基因区域,只能表现为加载缓慢或无法浏览。
以VCF为例,文件最好经过压缩并建立索引。否则,变异记录在大文件中很难按坐标快速检索。
对IGV数据格式来说,索引文件不是附件,而是必需组成部分。
这是很多初学者最容易忽略的一点。
2.3 第三步,统一参考基因组版本
IGV展示数据时,参考基因组必须一致。否则,即使文件本身正确,也会出现坐标对不上、注释位置偏移、基因区间显示异常等问题。
常见参考基因组包括:
- hg19
- hg38
- mm10
- mm39
如果你的BAM来自hg19,但VCF或注释文件按hg38整理,IGV中的显示结果就可能混乱。
在临床研究和组学分析中,版本不统一会直接影响结果解释。
建议你在导入前先检查:
- 物种是否一致
- 染色体命名是否一致
- 坐标系统是否一致
这是使用IGV数据格式时最重要的前置判断。
2.4 第四步,检查索引与压缩方式
很多文件之所以无法在IGV中顺利浏览,不是因为内容错了,而是压缩和索引方式不对。
常见规范是:
- BAM配.bai
- CRAM配.crai
- bgzip压缩VCF,再配.tbi或.csi
- BigWig和BigBed本身就适合快速随机访问
如果文件大、区域多、查询频繁,优先选择支持随机访问的IGV数据格式。
这样能明显提升加载速度和交互体验。
对于超大文件,索引质量尤其重要。索引不完整、路径错误、文件损坏,都会导致轨道无法正常显示。
3. 你在IGV里最常见的格式问题
3.1 染色体命名不一致
这是最常见的问题之一。比如参考基因组使用“chr1”,而文件中写成“1”。两者看似接近,实际上无法自动匹配。
解决思路很简单:
- 在导入前统一命名规则
- 保持参考基因组与注释文件一致
- 必要时进行坐标和名称转换
在IGV数据格式管理中,统一命名比后期补救更重要。
3.2 文件未排序或索引失效
如果BAM、VCF或BED文件没有按染色体和坐标排序,IGV往往无法正确读取索引。
这种情况下,文件即使能打开,也可能出现空白、报错或跳转失败。
建议在正式导入前检查:
- 是否已排序
- 索引是否生成成功
- 索引是否与文件版本对应
索引失效常见于文件被重新编辑、重新压缩或被移动路径后。
这类问题在科研协作中非常常见。
3.3 大文件加载慢
当数据量很大时,IGV的体验差异会非常明显。
如果没有合适的压缩和索引,浏览一个区域可能要等待较久。
优化方法包括:
- 使用适合随机访问的格式
- 避免加载冗余轨道
- 只保留当前分析需要的文件
- 尽量使用压缩后格式
对于长期项目,建议一开始就按照标准化的IGV数据格式整理文件,后续会省很多时间。
4. 从科研到临床,如何更高效地用好IGV
4.1 建立自己的文件检查清单
想稳定使用IGV,最实用的方法不是记住所有格式细节,而是建立固定检查流程。
建议每次导入前检查:
- 文件类型是否正确
- 是否有对应索引
- 是否已排序
- 参考基因组是否一致
- 染色体命名是否统一
这5项足以覆盖大多数IGV数据格式问题。
4.2 把格式管理前置到数据生产阶段
很多团队把格式问题留到最后才处理,结果在汇报前集中返工。
更高效的做法,是在数据生成阶段就统一规范。
例如:
- 比对后立即排序并建索引
- 变异文件压缩后马上索引
- 注释文件提前统一坐标体系
- 项目内固定参考版本和命名规则
这样做的好处是,后续打开IGV时几乎不需要反复试错。
格式前置管理,能显著提升科研效率和结果可重复性。
4.3 让解螺旋帮助你减少重复排查
如果你在项目中经常遇到文件格式混乱、索引缺失、版本不一致等问题,说明你的数据整理流程需要标准化工具支持。解螺旋可帮助医学生、医生和科研人员更高效地梳理数据结构,减少在IGV导入和浏览阶段的重复排查。
对于需要持续处理组学数据的人来说,稳定、规范、可复用的IGV数据格式管理,比临时修补更有价值。
把标准流程建立起来,才能把时间留给真正的分析和解释。
总结Conclusion
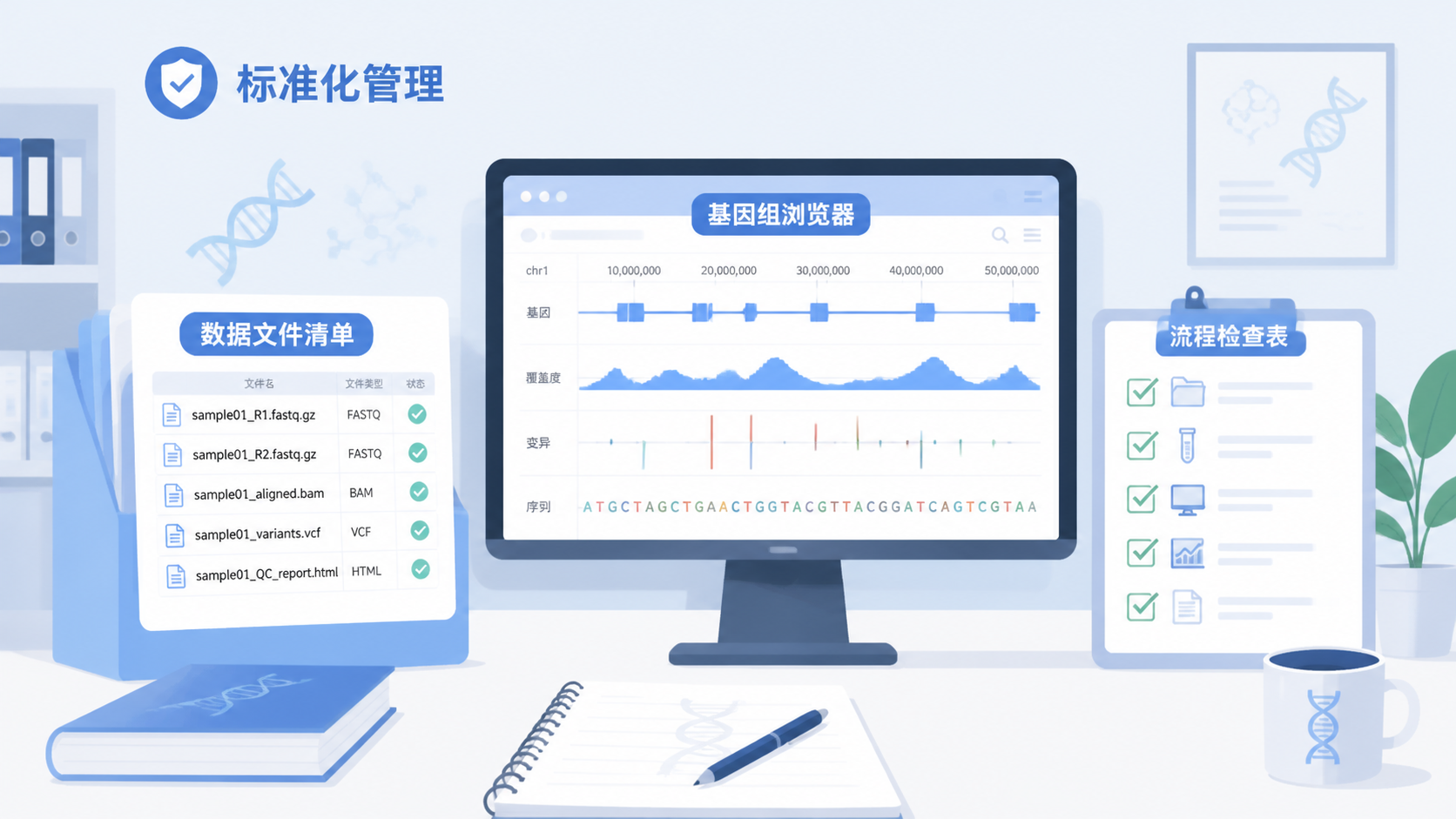
IGV数据格式的核心,不只是文件能不能打开,而是类型是否匹配、索引是否齐全、参考基因组是否一致。
只要按“识别类型、检查文件、统一版本、验证索引”这4步走,大多数导入和显示问题都能提前避免。
对于医学生、医生和科研人员来说,熟练掌握IGV数据格式,意味着更快定位问题,更少重复劳动,也更高的数据解释效率。
如果你希望进一步提升数据整理和分析效率,欢迎关注并使用解螺旋 相关工具与服务,让标准化流程真正落地。
- 引言Introduction
- 1. 先理解IGV为什么“挑格式”
- 2. 4步快速掌握IGV数据格式
- 3. 你在IGV里最常见的格式问题
- 4. 从科研到临床,如何更高效地用好IGV
- 总结Conclusion