引言Introduction
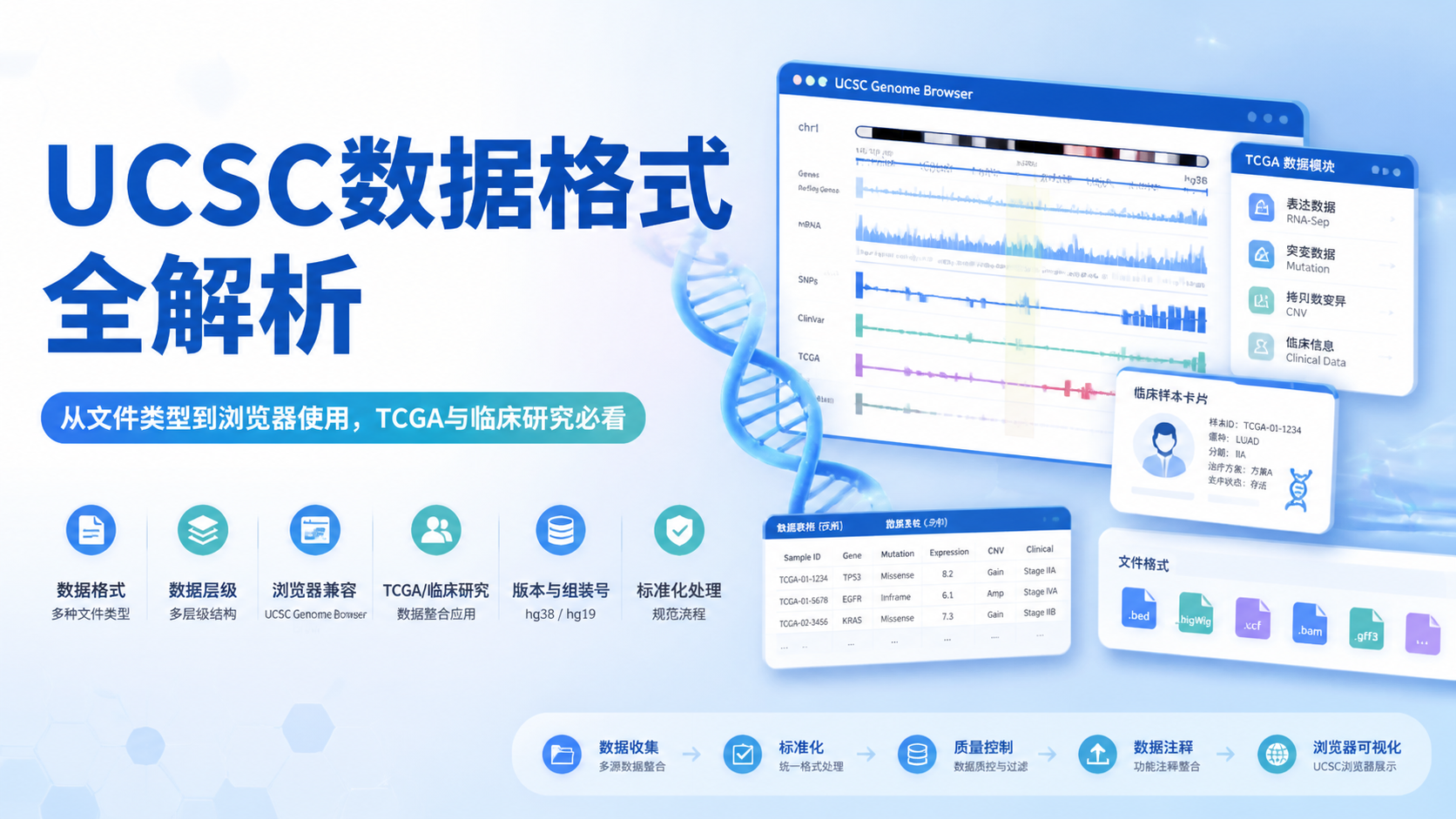
UCSC数据格式是做基因组浏览、注释下载和下游分析时最常遇到的问题之一。很多医学生、医生和科研人员拿到UCSC数据后,常会卡在“文件能打开,却不知道怎么用”。本文用7个关键点讲清UCSC数据格式,帮助你快速判断数据类型、读取方式和分析场景。
1.UCSC数据格式的核心是什么
1.1 先理解它不是单一文件类型
UCSC本身是加州大学圣克鲁兹分校基因组浏览器,提供的是基因组数据访问、可视化、下载和注释工具 。所以,UCSC数据格式并不是一种固定标准,而是多种用于存储和交换基因组信息的文件形式。
常见内容包括基因序列、基因结构、SNP、调控区、表达数据、临床信息和多物种比对信息。它的重点不在“文件长什么样”,而在“数据怎么被组织和读取”。
1.2 你需要先分清数据层级
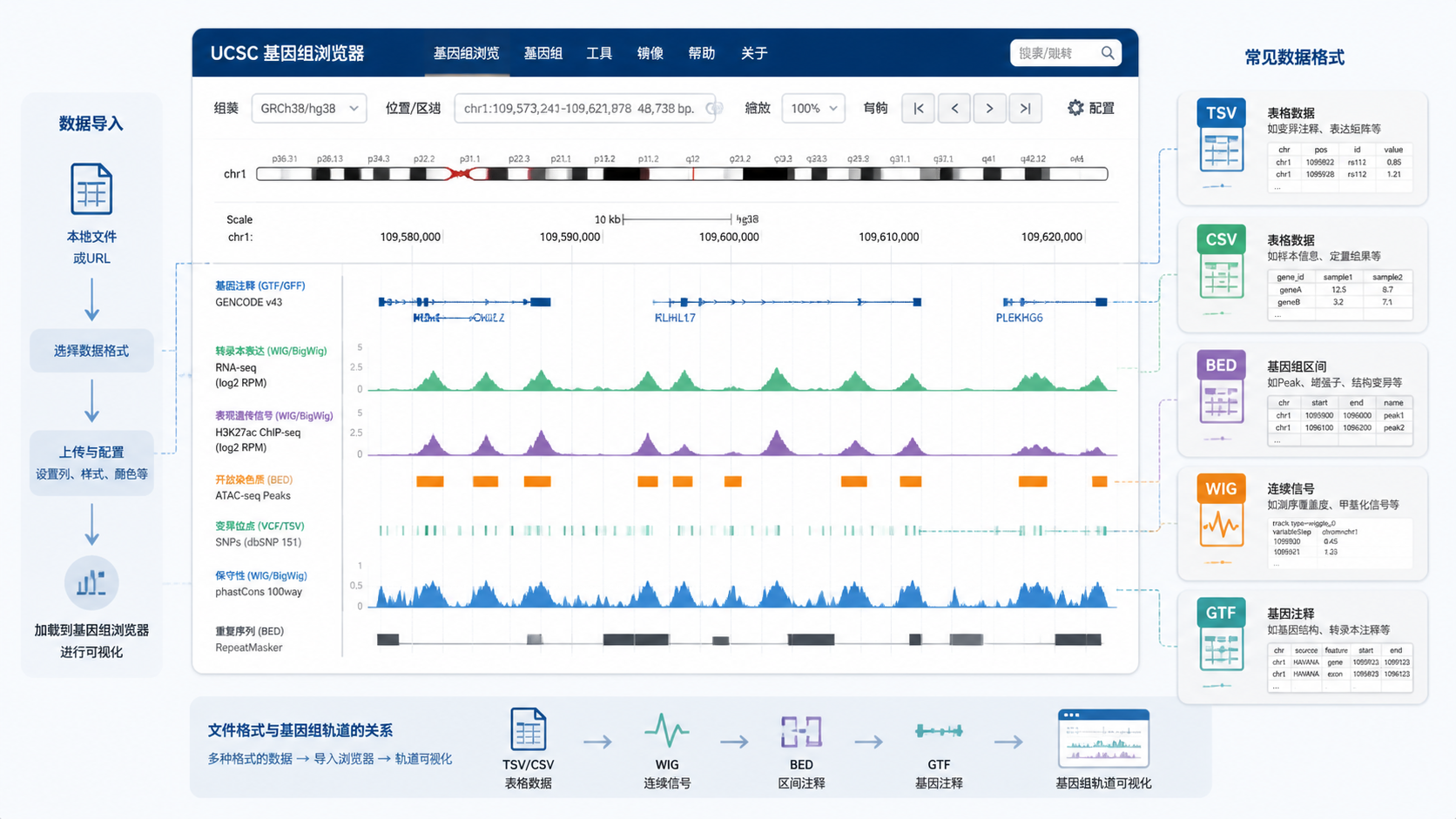
UCSC数据通常对应三个层级。
- 序列层:FASTA、部分比对序列
- 注释层:BED、GTF、WIG、bigWig、bigBed
- 表格层:TSV、CSV、Xena表格数据
对医学生和科研人员来说,最常见的困难不是找不到数据,而是不清楚该用哪种UCSC数据格式进入差异分析、可视化或临床整合。
2.最常见的UCSC数据格式有哪些
2.1 表格类格式最常用于下载和整理
根据知识库信息,UCSC Xena等下载数据常见为TSV格式,也可能是CSV格式。TSV以制表符分隔,CSV以逗号分隔。读取前先判断分隔符,是避免报错的第一步。
在TCGA相关下载中,常见数据包括:
- FPKM表达矩阵
- clinical临床信息
- survival生存信息
- copy number拷贝数数据
- 探针ID映射信息
- 基因ID到基因名转换信息
这些内容通常以表格方式组织,适合R、Python和Excel处理。
2.2 浏览器兼容格式适合可视化
UCSC Genome Browser支持快速互动展示,也支持把自己的数据导入浏览器。常见的可视化相关格式包括:
- BED,适合基因组区间
- WIG或bigWig,适合连续信号
- bigBed,适合大规模注释
- BAM或相关比对数据,适合序列对齐展示
如果你的目标是“看基因组位置和信号分布”,优先考虑浏览器友好的格式。
3.为什么UCSC数据格式常被用于TCGA和临床研究
3.1 它的数据整理更利于下游分析
知识库明确提到,UCSC Xena下载方便,且与GDC整理后的CONS数据一致。部分数据经过LOG2处理,也可以逆LOG2后得到整数,便于进一步做差异分析,比如DESeq2和edgeR。
这类数据格式的优势很明确。
- 结构清楚
- 便于批量读取
- 适合做表达矩阵分析
- 适合合并临床信息
对科研人员来说,一个能同时承载表达、临床和生存信息的数据体系,远比单独零散文件更高效。
3.2 临床变量维度更丰富
知识库提到,UCSC上的临床信息有时比GDC更全面,且临床表可达到169列。这里面可能包括样本ID、病人ID、治疗信息、放疗记录等。
这意味着,UCSC数据格式不仅服务于基因层面的分析,也服务于转化医学研究。
4.如何快速判断UCSC数据格式能不能直接用
4.1 先看分隔符,再看字段含义
实际下载后,最常见的问题是文件能打开,但不知道如何读取。知识库建议先尝试TSV,不行再试CSV。如果两者都不行,就直接打开文件查看分隔方式。
你可以按这个顺序判断。
- 看文件后缀
- 判断分隔符
- 检查首行是否为字段名
- 确认行名和列名是否对应样本或基因
对矩阵型数据来说,行名常是基因ID,列名常是样本前16位编码。
4.2 确认数据是否做过标准化
知识库提到,部分下载数据已经做过LOG2处理。这个信息非常关键,因为它决定你能否直接用于某些统计分析。
- 已LOG2处理的数据适合可视化和部分比较
- 逆LOG2后得到整数,更适合DESeq2、edgeR这类差异分析流程
- 临床和生存信息通常可直接整合,不需要转换
如果忽略数据预处理状态,很容易把分析结果做偏。
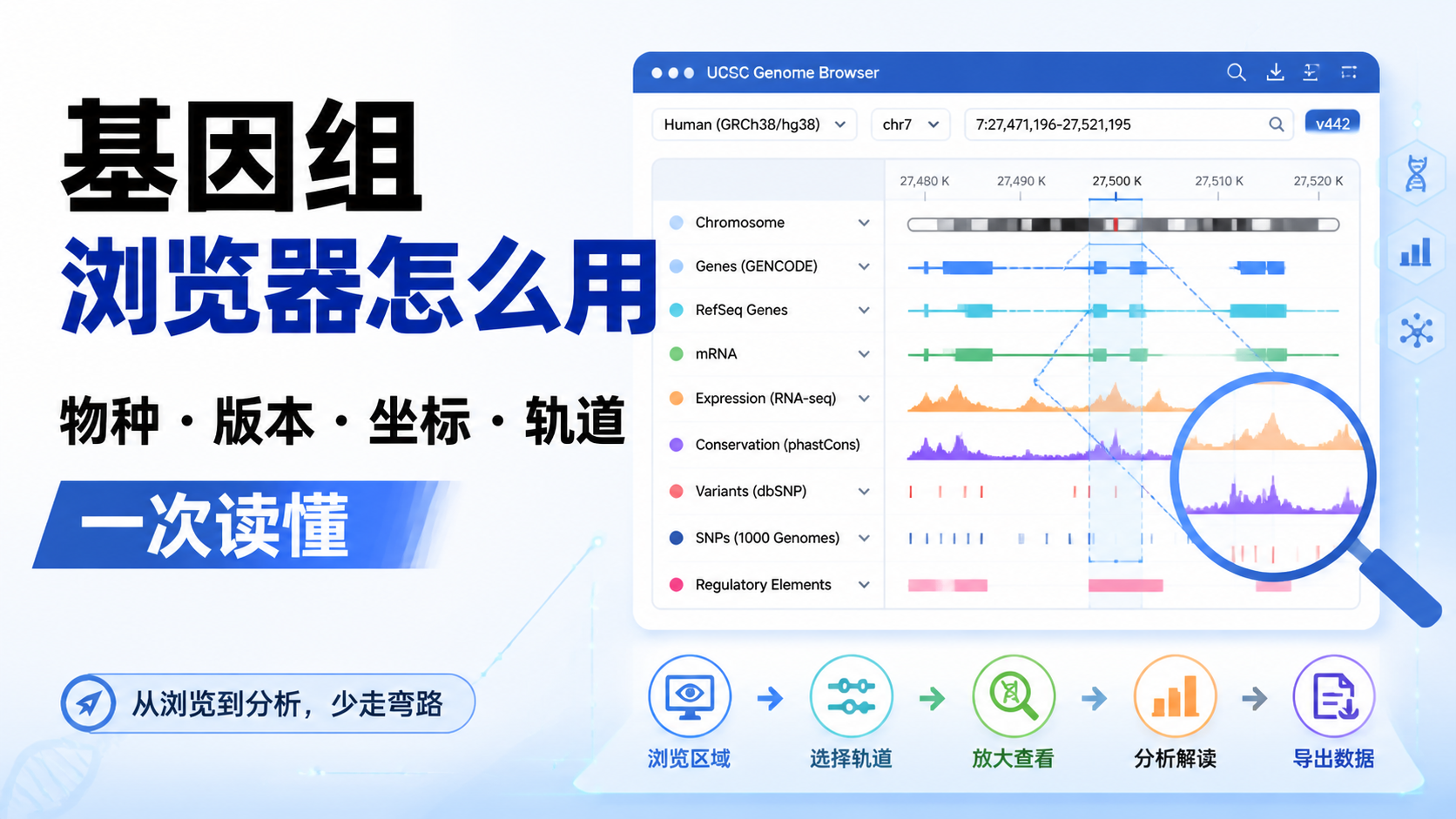
5.UCSC数据格式在浏览器里的使用逻辑
5.1 Genome Browser强调“按区域查看”
UCSC Genome Browser是一个基于网络的图形查看器,支持缩放和滚动查看染色体注释。它的强项是把某一基因组区域的多层信息放在同一窗口中展示。
你可以看到:
- 基因结构
- 调控区域
- 变异分布
- 表达轨迹
- 多物种比对
这也是为什么UCSC数据格式强调“可视化友好”。
5.2 常用工具和格式是对应关系
UCSC提供多个工具,和格式高度相关。
- BLAT,用于快速比对序列
- Table Browser,用于从数据库下载数据
- Variant Annotation Integrator,用于功能注释
- Data Integrator,用于整合多来源数据
- In-silico PCR,用于引物快速比对
- LiftOver,用于不同组装版本转换
如果你手里的文件是区间型、注释型或序列型,就可以优先考虑这些工具。格式选对了,工具效率会高很多。
6.做研究时要特别注意的3个细节
6.1 版本和组装号不能忽略
UCSC会不定时更新。不同基因组组装版本之间,坐标可能不一样。做论文、复现分析或多队列整合时,必须确认参考版本。
常见风险包括:
- 同一基因在不同版本坐标不同
- 注释轨道更新后内容变化
- 临床下载数据和表达数据版本不一致
如果坐标体系没对齐,后续分析结果很难可信。
6.2 批次信息需要单独处理
知识库提到,UCSC临床信息中包含batch number,可反映样本批次编号。对于转录组和多组学分析,这类信息非常重要。
建议你在分析前检查:
- 是否存在批次效应
- 是否需要校正
- 样本是否来自不同平台或中心
这一步常被忽略,但对结果影响很大。
6.3 不能把UCSC当作测序平台
知识库明确说明,UCSC本身不进行测序,也不直接下结论。它主要是收集、整理、检索、可视化和下载信息。
所以,使用UCSC数据格式时要保持科研规范。
- 看清原始来源
- 记录引用信息
- 区分平台注释与原始测序结果
- 结合原始数据库交叉验证
这也是E-E-A-T意义上的“可信使用”。
7.实际工作中怎么提高处理效率
7.1 先建立自己的读取流程
对医学生和科研人员来说,最实用的方法不是记住所有格式,而是建立固定流程。
建议按这个顺序处理:
- 判断数据类型
- 确认分隔符
- 查看是否LOG2处理
- 核对样本名和基因名
- 合并临床信息
- 再进入差异分析或生存分析
这样可以减少重复报错,也更适合团队协作。
7.2 让标准化工具替你省时间
如果你经常处理UCSC数据格式,建议使用更规范的数据管理与文献支持工具。像解螺旋这类面向科研场景的产品,可以帮助你更快理解数据库来源、梳理分析路径、沉淀规范化流程。当数据格式、版本和临床变量都变复杂时,标准化工具能明显降低出错率。
对临床科研而言,真正浪费时间的往往不是分析本身,而是前期格式判断、文件整理和版本对齐。把这部分流程标准化,才是提升效率的关键。
总结Conclusion
UCSC数据格式并不是单一文件,而是围绕基因组浏览、注释下载、表达矩阵和临床整合形成的一套数据组织方式。你只要抓住7个关键点,就能快速判断文件类型、读取方式、预处理状态和适用场景。对医学生、医生和科研人员来说,真正重要的是把格式识别、版本确认和批次处理做扎实。
如果你希望进一步提高UCSC数据处理效率,减少格式判断和数据整理的时间,可以结合解螺旋的科研支持工具,把数据读取、规范化和下游分析流程做得更稳、更快。

- 引言Introduction
- 1.UCSC数据格式的核心是什么
- 2.最常见的UCSC数据格式有哪些
- 3.为什么UCSC数据格式常被用于TCGA和临床研究
- 4.如何快速判断UCSC数据格式能不能直接用
- 5.UCSC数据格式在浏览器里的使用逻辑
- 6.做研究时要特别注意的3个细节
- 7.实际工作中怎么提高处理效率
- 总结Conclusion