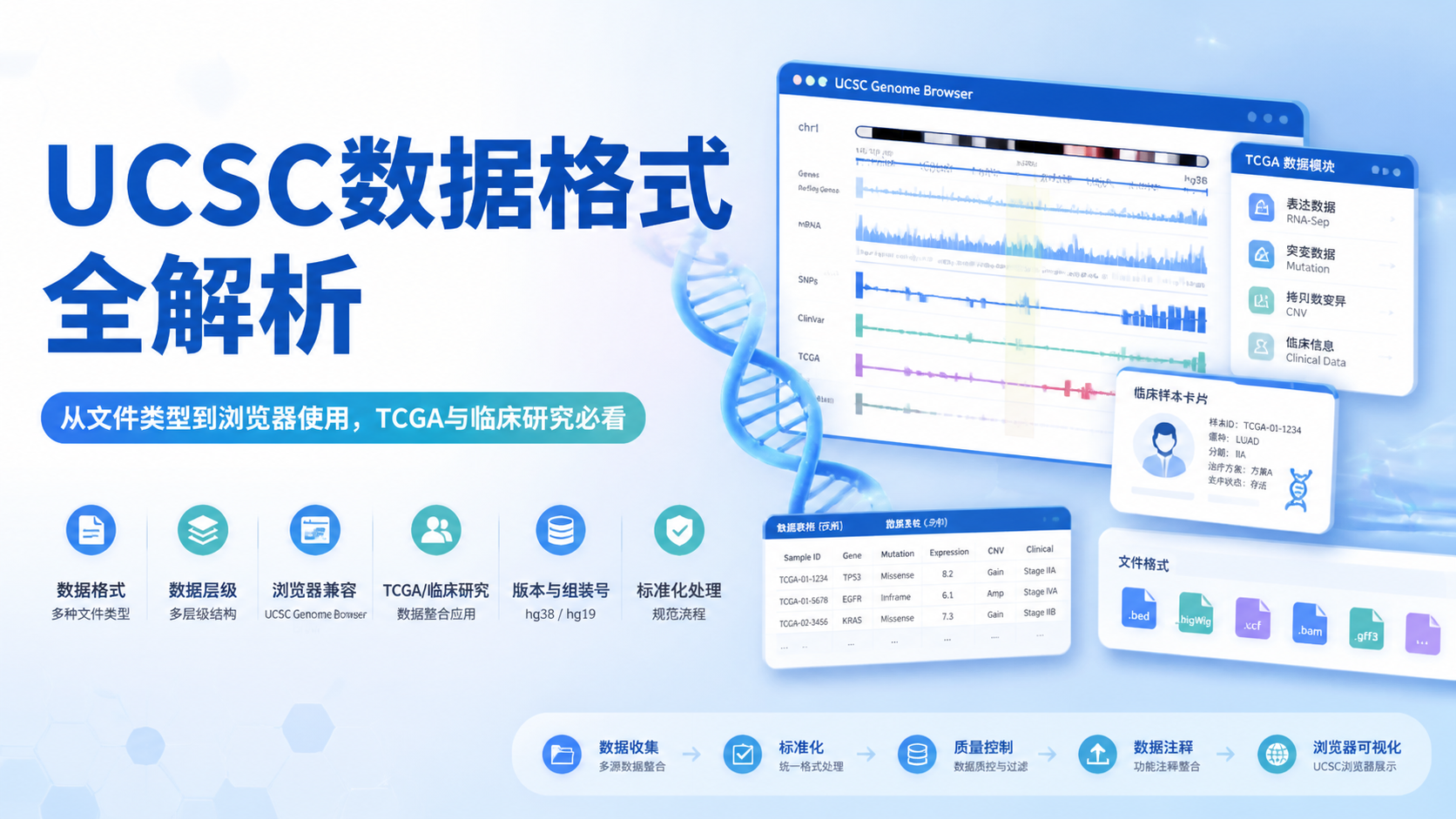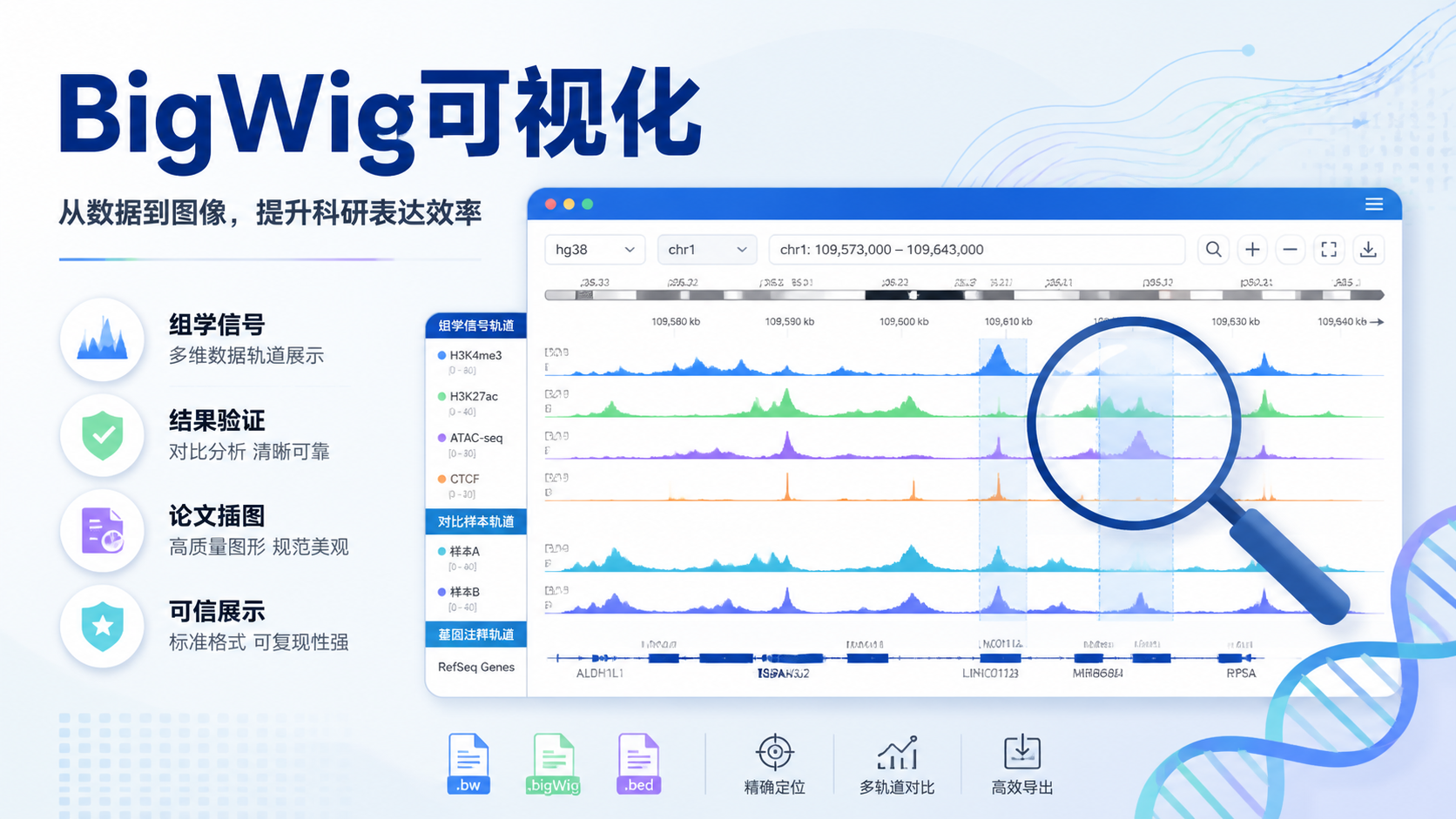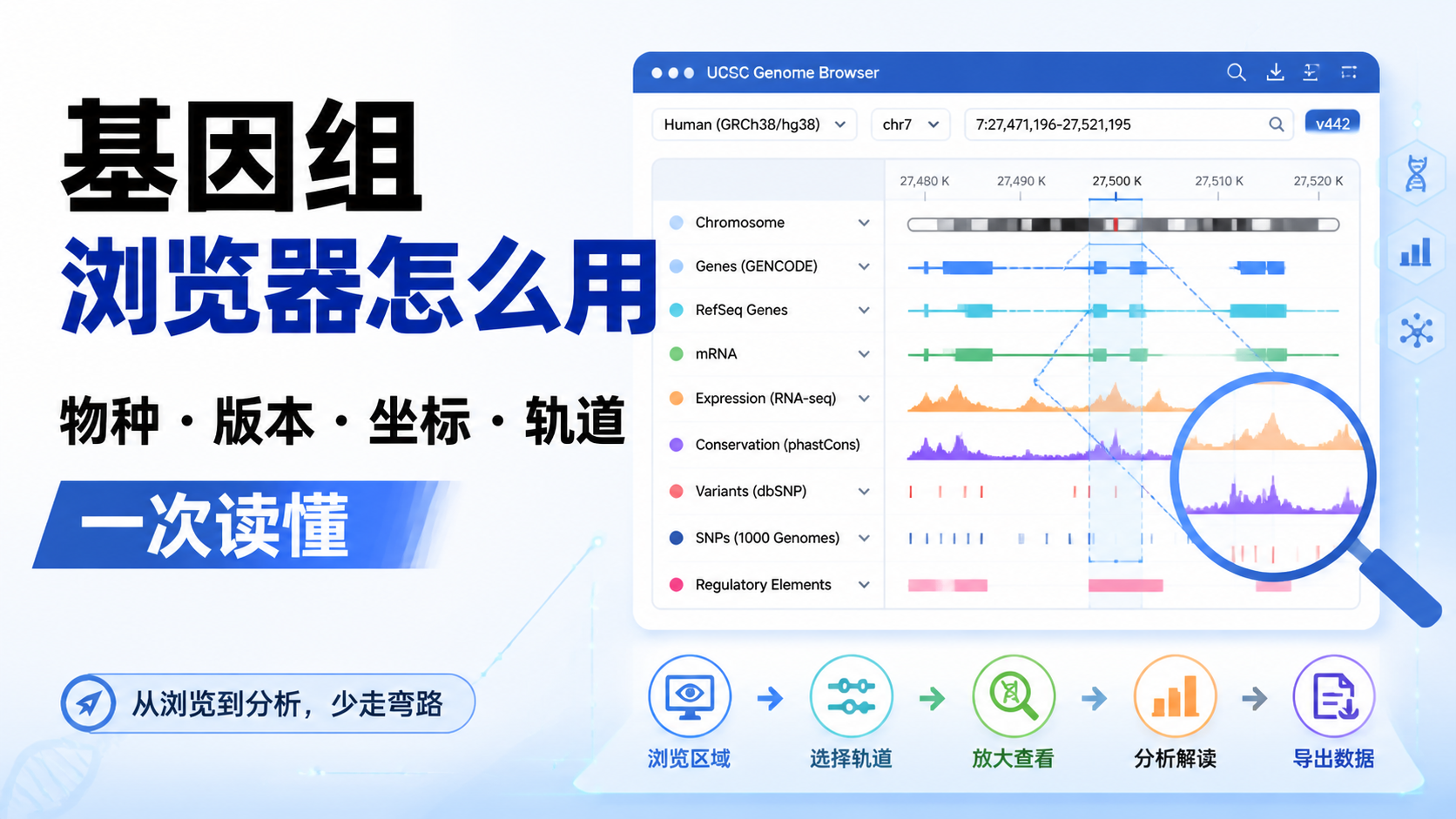
引言Introduction
基因组浏览器数据看起来信息密集,但真正难点不是“有没有数据”,而是“如何读对数据”。物种、组装版本、坐标和注释轨道一旦选错,结果就可能完全偏移。想快速、准确解读基因组浏览器数据,先抓住版本、坐标和track三件事。
1. 先确认物种和组装版本
1.1 版本不同,位置就不同
在解读基因组浏览器数据时,第一步不是搜基因,而是确认物种和基因组组装版本。UCSC 浏览器中,同一物种可能存在多个组装版本。人类常见版本包括 hg38。小鼠常见版本包括 mm39。如果版本不一致,基因坐标会变化,后续分析会失真。
这在跨样本、跨项目比较时尤其重要。
同一研究项目内,组装版本必须保持一致。 否则,基因位置、外显子边界、变异注释都会出现偏差。
1.2 先看版本信息,再做检索
UCSC 浏览器主页和检索页都会显示物种、版本及其来源信息。进入前,应先确认当前分析对象。若你要下载数据,选择就近镜像站点通常更快。若只做浏览,原始站点和镜像站点都可用。
要点是:先版本,后检索。 这是读懂基因组浏览器数据的基础动作。
2. 选对检索词,结果才会准
2.1 检索词不止是基因名
UCSC Genome Browser 支持多种检索方式。常见包括:
- 基因名称,如 TP53。
- RNA 登录号,如 NM_000546。
- 具体坐标,如 chr17:7,668,421-7,687,490。
- 染色体带,如 20p13。
- DNA 序列。
- 疾病名称,如 breast cancer。
- 蛋白结构关键词,如 zinc finger。
这意味着,基因组浏览器数据的入口并不单一。 不同研究问题,应选不同检索词。
2.2 输入不完整时,要注意自动匹配
以基因名称检索时,系统会弹出匹配条目。若输入不完整,浏览器通常给出部分匹配结果,而不是直接精确定位。
这对新手很重要。不要把“出现结果”误当成“结果准确”。 一定要再次核对条目名称、转录本和位置。
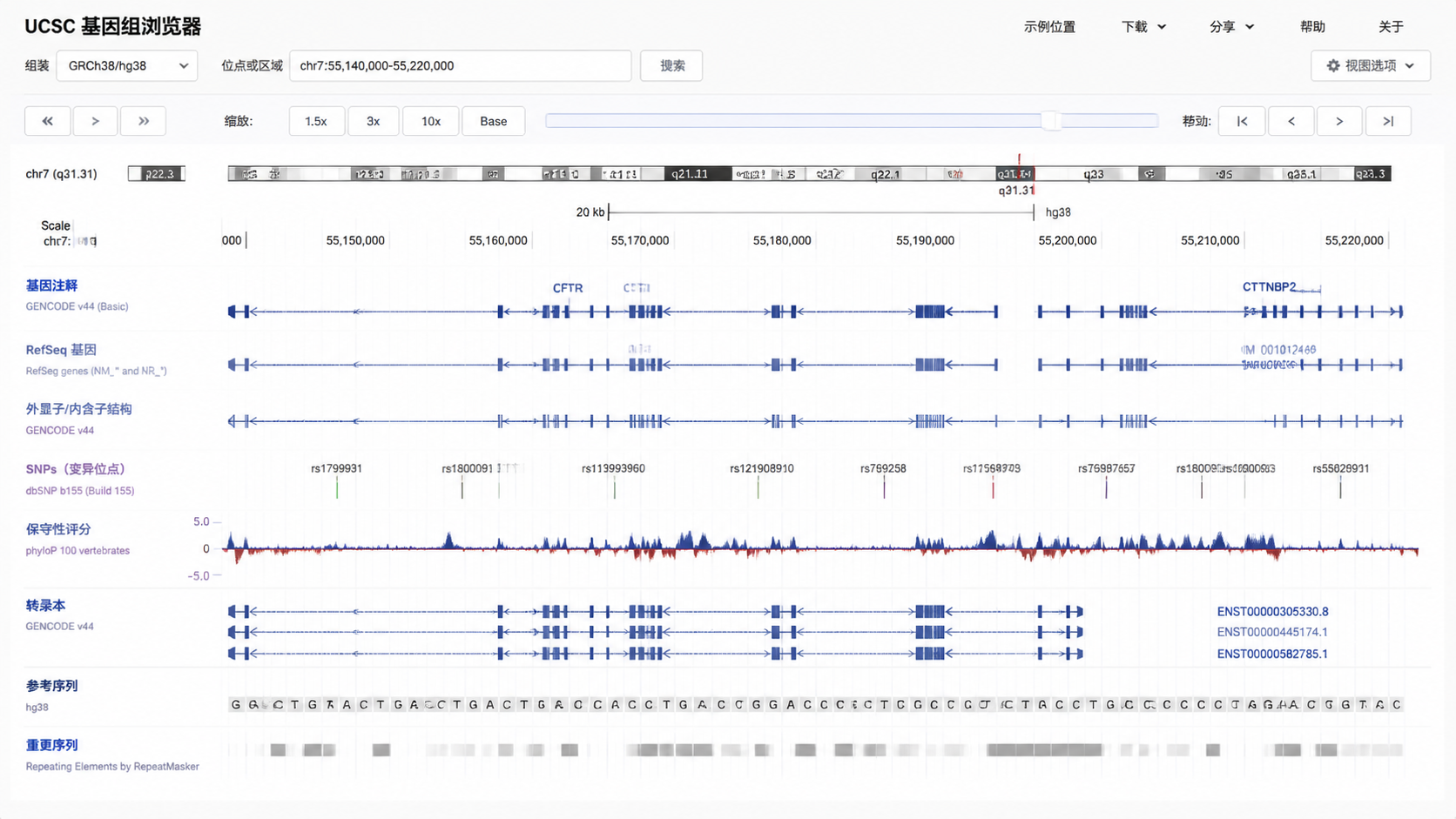
3. 读懂坐标,是解读数据的核心
3.1 坐标格式要看清
基因组浏览器数据的定位本质上依赖坐标系统。标准格式通常是 chr:start-end。例如 chr17:7,668,421-7,687,490。
这类坐标能直接定位到染色体上的具体区段,也能用于缩放查看局部区域。
坐标读错,后面的外显子、SNP、重复序列和表达轨道都会跟着错。
3.2 单基因、片段到整条染色体都能看
UCSC 浏览器的一个优势是连续可变显示。它可以从单个碱基,一直缩放到整个染色体。
你可以看单个基因,也可以看一个外显子,甚至整段染色体带。
这种可缩放能力,让基因组浏览器数据适合做精细定位,也适合做宏观比较。
4. 看懂track,才算真正会读图
4.1 不同轨道对应不同生物学信息
UCSC 浏览器通过多个 track 叠加展示信息。常见内容包括:
- mRNA 比对。
- DNA 重复元件。
- 基因预测。
- 基因表达数据。
- 疾病相关数据。
- SNP 和其他变异。
- 保守性信息。
单一轨道的意义有限,多个轨道并置才更接近真实生物学场景。 这也是基因组浏览器数据最有价值的地方。
4.2 用垂直整合思路读图
浏览器把不同来源、不同类型的数据放在同一坐标轴上。
这叫垂直整合。它的优势是,你可以同时判断:
- 某个变异是否落在外显子内。
- 该区域是否有重复序列干扰。
- 是否有保守性信号支持功能重要性。
- 是否与表达或疾病数据重叠。
读图时不要只盯着基因名,要看它周围的注释组合。
5. 调整显示模式,减少误判
5.1 hide、dense、squish、pack、full 各有用途
UCSC 的 track 显示方式通常包括 hide、dense、squish、pack、full。
这些模式决定信息密度和可读性。
- hide:隐藏该轨道。
- dense:压缩为一行。
- squish:压缩显示,但保留更多条目。
- pack:每条信息尽量单独显示。
- full:最完整展示。
解读基因组浏览器数据时,不是显示越多越好,而是要按任务选择模式。
看整体分布,用 dense。
看细节关系,用 pack 或 full。
5.2 先粗看,再细看
建议先用低密度模式快速扫一遍,再切换到高分辨率模式确认关键区域。
这样能减少噪音干扰,也能提高定位效率。
特别是在基因密集区、重复序列多的区域,这一步很关键。
6. 重点关注表达、保守性和变异三类信息
6.1 表达轨道告诉你“有没有生物学背景”
UCSC 浏览器支持显示基于 GTEx 等来源的表达信息。
表达轨道能帮助你判断一个基因在不同组织中的活跃程度。
如果研究的是疾病相关基因,表达背景能帮助解释组织特异性。
6.2 保守性轨道提示功能重要区
比较基因组模块可显示不同物种间的保守性。
进化上保守的区域,常常意味着功能更重要。
尤其是外显子和调控元件,往往比非功能区更保守。
保守性不是功能证明,但它是重要线索。
6.3 变异轨道帮助定位风险位点
Variation 模块可以显示 SNP 和其他变异信息。
当你分析某个候选位点时,应该确认它是否落在已知变异密集区域。
这对后续解释致病性、群体频率和功能影响都很有帮助。
7. 导出和复用数据时,要注意格式与下游分析
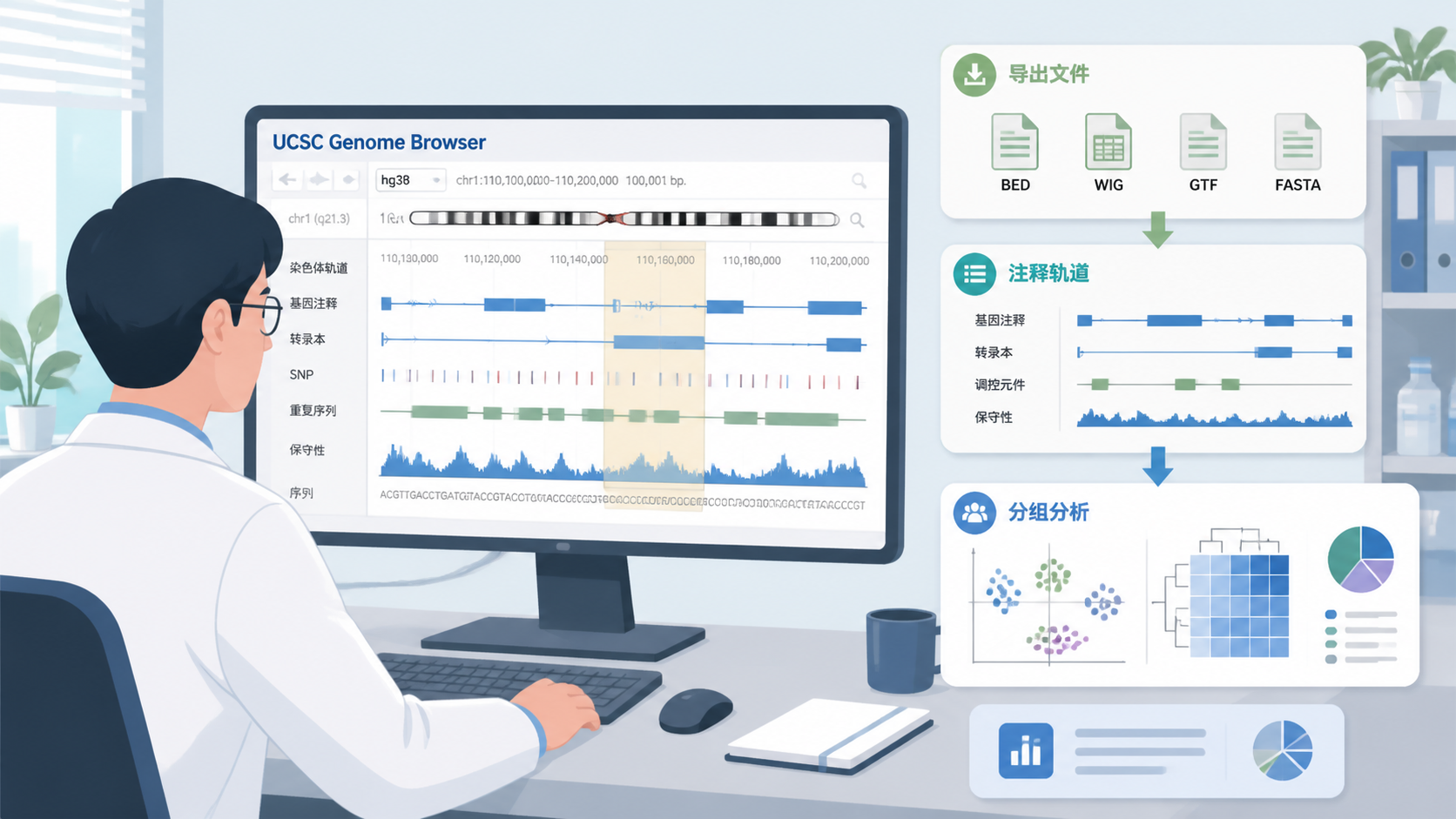
7.1 浏览器不只是看图,也能导出
UCSC 浏览器提供图像导出和数据下载能力。
pdf 或 postscript 输出适合学术发表。
Table Browser 则适合按条件提取表格、序列和注释数据。
常见输出包括:
- 全字段表格。
- 序列。
- BED。
- GTF。
- 自定义 track。
- 多重比对格式 MAF。
如果你要进入后续统计分析,优先考虑标准化格式。 这样更容易导入 R、Python、Galaxy 或数据库系统。
7.2 复杂任务用 Table Browser 更稳
对于更复杂的查询,Table Browser 更适合做筛选、交集和批量导出。
例如,你可以限定染色体区域,筛选重复次数,或与其他表做交集。
这对科研场景特别实用。因为很多问题不是“有没有这个基因”,而是“这个区域有哪些注释共同支持某种假设”。
8. 从浏览到分析,解螺旋可以帮你少走弯路
基因组浏览器数据的价值,来自“看懂”和“用对”。
如果你在物种版本选择、坐标核对、track 解释和批量导出上反复耗时,后续分析就会被拖慢。
更高效的做法,是把浏览、筛选、导出和可视化放到更顺手的工作流里。
这也是很多科研人员选择解螺旋的原因。它能帮助你把基因组浏览器数据的阅读、整理和后续处理串起来,减少重复操作。对医学生、医生和科研人员来说,这意味着更快定位关键区域,更少版本错误,更高的数据复用效率。
如果你希望把分散的基因组浏览器数据整理成可分析、可展示、可发表的结果,解螺旋会是更省时的选择。
总结Conclusion
基因组浏览器数据并不难读,难的是建立正确顺序。先确认物种和版本,再选对检索词,接着读坐标、看track、调显示模式,最后结合表达、保守性和变异信息做综合判断。
抓住这7个要点,你就能把“看图”变成“读懂图”。
如果你正在做基因、变异或疾病相关研究,建议把这些步骤纳入日常分析流程。需要更高效地整理和利用基因组浏览器数据时,可以进一步使用解螺旋品牌的相关工具与服务,帮助你更快完成检索、筛选和结果输出。
- 引言Introduction
- 1. 先确认物种和组装版本
- 2. 选对检索词,结果才会准
- 3. 读懂坐标,是解读数据的核心
- 4. 看懂track,才算真正会读图
- 5. 调整显示模式,减少误判
- 6. 重点关注表达、保守性和变异三类信息
- 7. 导出和复用数据时,要注意格式与下游分析
- 8. 从浏览到分析,解螺旋可以帮你少走弯路
- 总结Conclusion