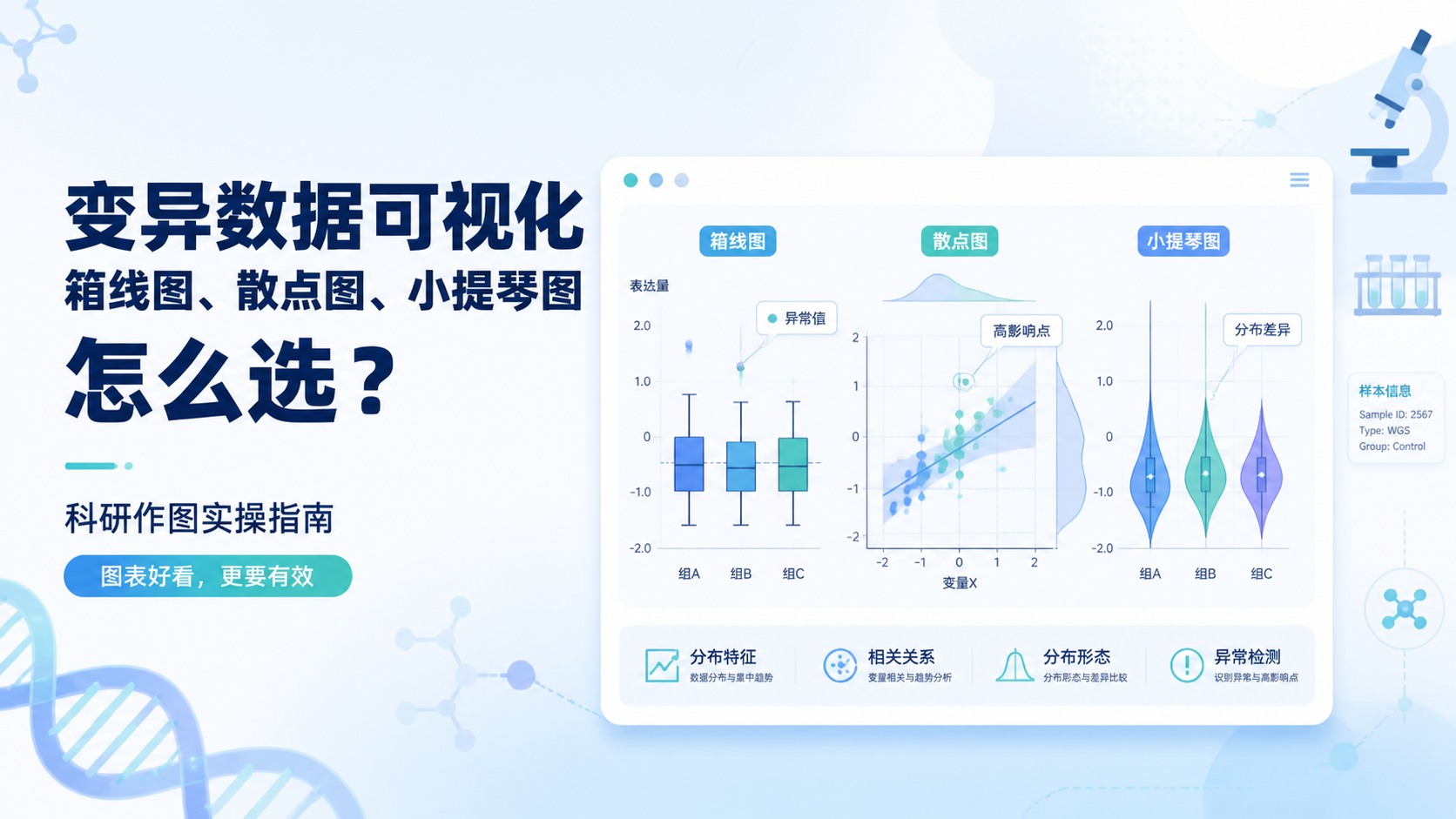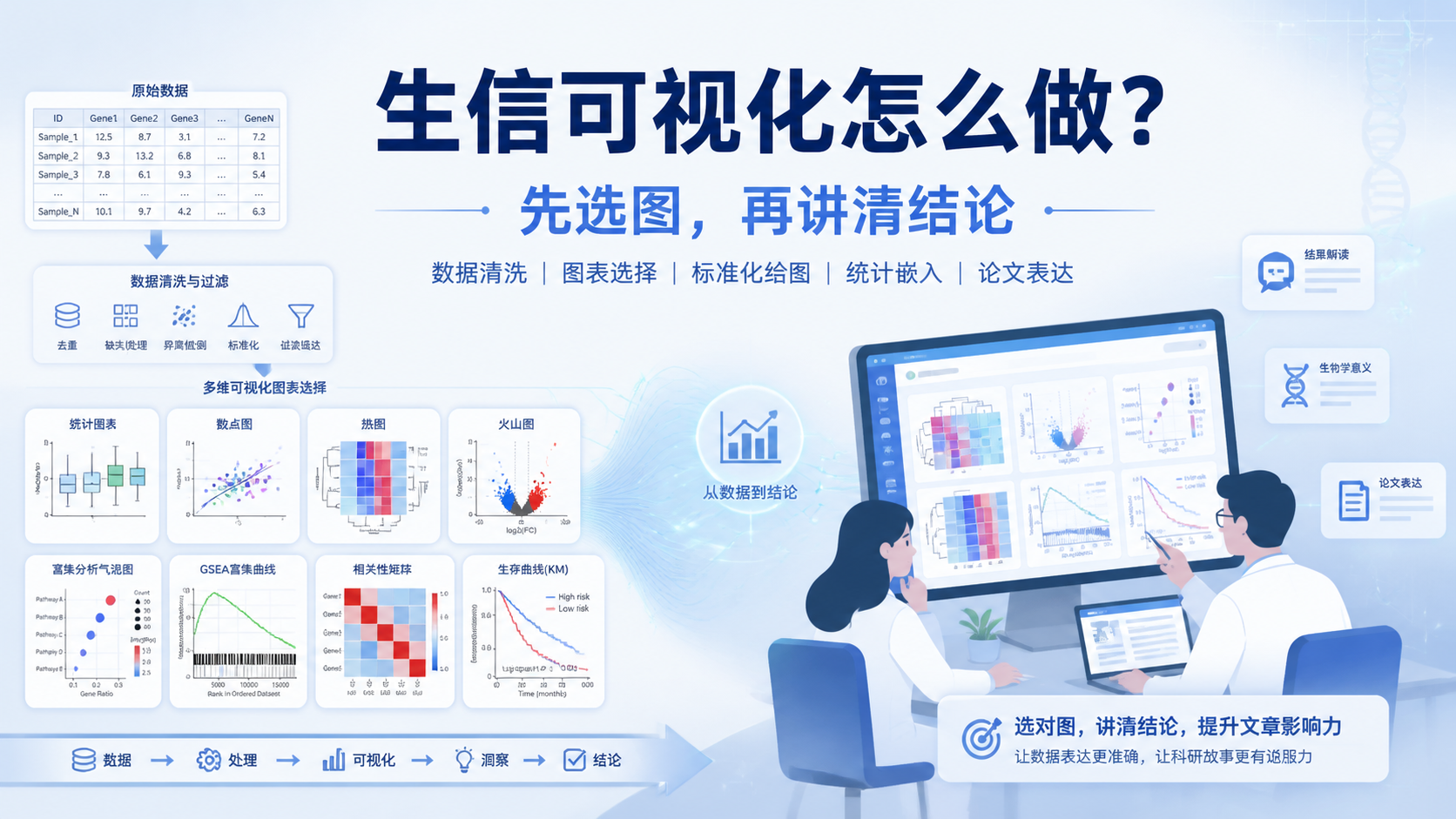
引言Introduction
测序数据可视化是差异分析前的关键一步。很多人直接做火山图或PCA,却忽略了样本质量、批次效应和离群值,最后导致结果不稳。想把测序数据可视化做得严谨,先看数据,再谈结论。
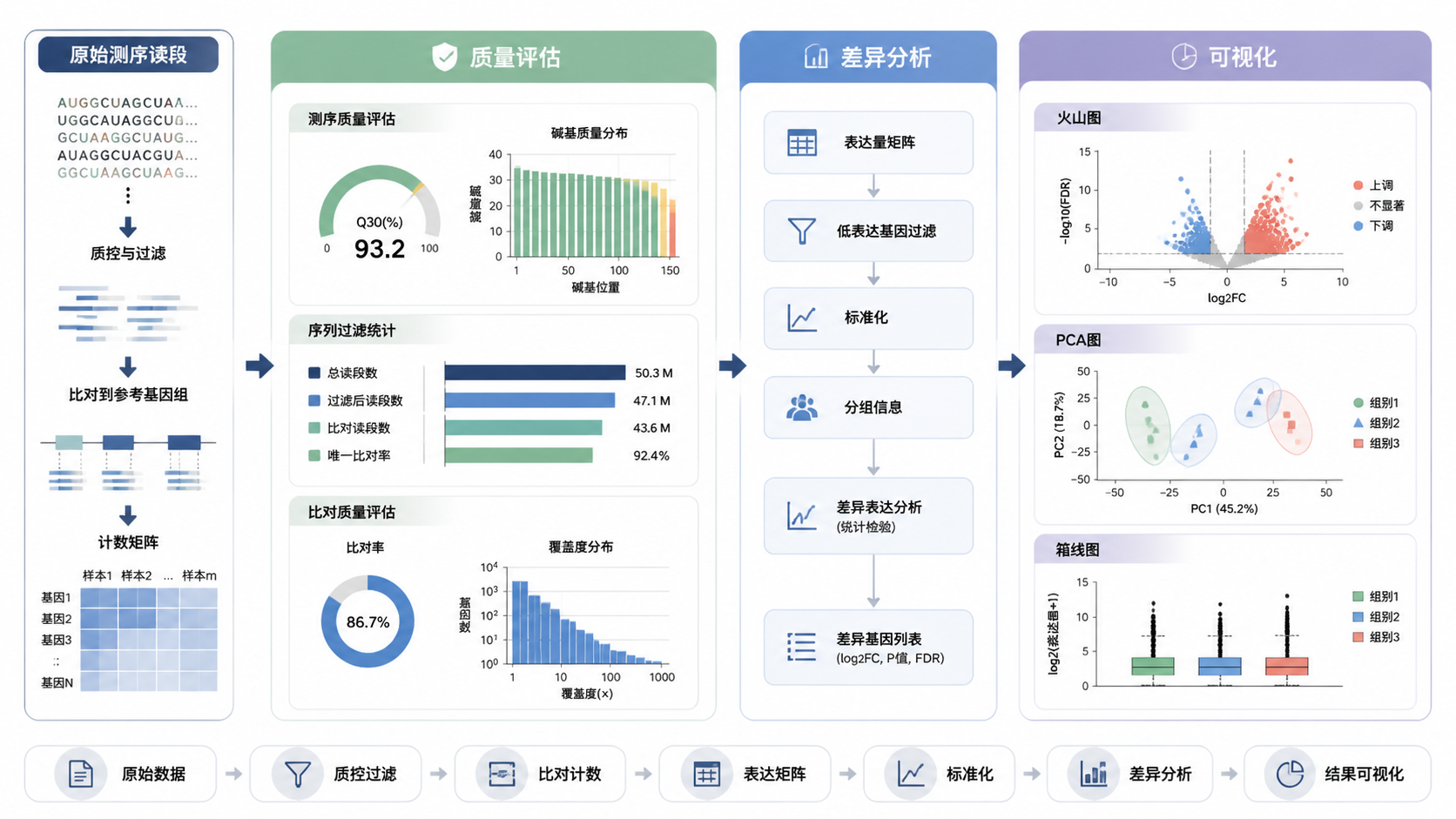
1. 为什么测序数据可视化不能跳过
1.1 先做质量评估,再做差异分析
在真实项目中,测序数据可视化不是“美化结果”,而是分析质量控制的一部分。常用的图包括箱线图、密度图、PCA图和层次聚类图。它们的作用很直接。看分布是否一致,判断样本是否偏离,检查批次效应是否明显。
如果样本分布差异很大,后续差异分析的可信度会下降。
例如,在肝癌TCGA数据中,原始数据的Normal与Tumor中心值可能并不一致。经过VST等方差稳定转换后,分布往往更接近统一。这个变化本身就说明,标准化处理对测序数据可视化非常重要。
1.2 数据不整理,图也画不好
很多初学者以为作图难,其实真正耗时的是数据整理。上游知识库中明确提到,数据清洗可能占到80%的时间。原因很简单。绘图包通常要求特定的数据结构,而原始表达矩阵往往需要先转成长数据,再合并样本信息和注释信息。
常见准备步骤包括:
- 导入表达矩阵、metadata和基因注释。
- 将基因ID转换成可读的gene symbol。
- 合并分组信息。
- 过滤缺失值和低表达基因。
- 统一表达量尺度后再作图。
只有数据结构正确,测序数据可视化才有分析价值。
2. 第一步:先把数据整理到可视化标准
2.1 建立完整的数据框
做测序数据可视化前,先把分析对象整理成标准数据框。通常需要三类信息。第一类是表达量数据。第二类是样本分组信息。第三类是基因注释信息。三者合并后,才能进入后续绘图。
以DESeq2差异分析结果为例,常见做法是先将结果转为data.frame,再把基因ID从行名提取为一列,随后与GTF注释文件进行join合并。这样可以把基因symbol放到结果中,便于后续标签标注和解读。
这一步的目标,不是追求复杂,而是确保每一列都能解释清楚。
2.2 统一表达尺度,减少假信号
测序原始count数据通常偏离正态分布,且受测序深度影响明显。用于可视化时,建议先做标准化或方差稳定转换。课程中提到的VST,就是常见的处理方式之一。它常用于下游聚类分析和富集分析,也有助于让箱线图和密度图更稳定。
可视化前常见的筛选原则包括:
- 保留表达量足够的基因。
- 去除明显缺失值。
- 排除异常样本。
- 在需要时校正batch effect。
标准化不是可选项,而是测序数据可视化的基础。
2.3 先看分布,再看样本关系
在正式画PCA或火山图前,建议先从最基础的分布图开始。箱线图能看每个样本的整体表达范围。密度图能看表达值是否存在双峰或整体偏移。若原始数据与标准化后数据差异明显,说明数据处理确实改善了分布一致性。
这一步的核心是找问题,不是找“好看的图”。
分布图越早做,越容易在前期发现离群样本。
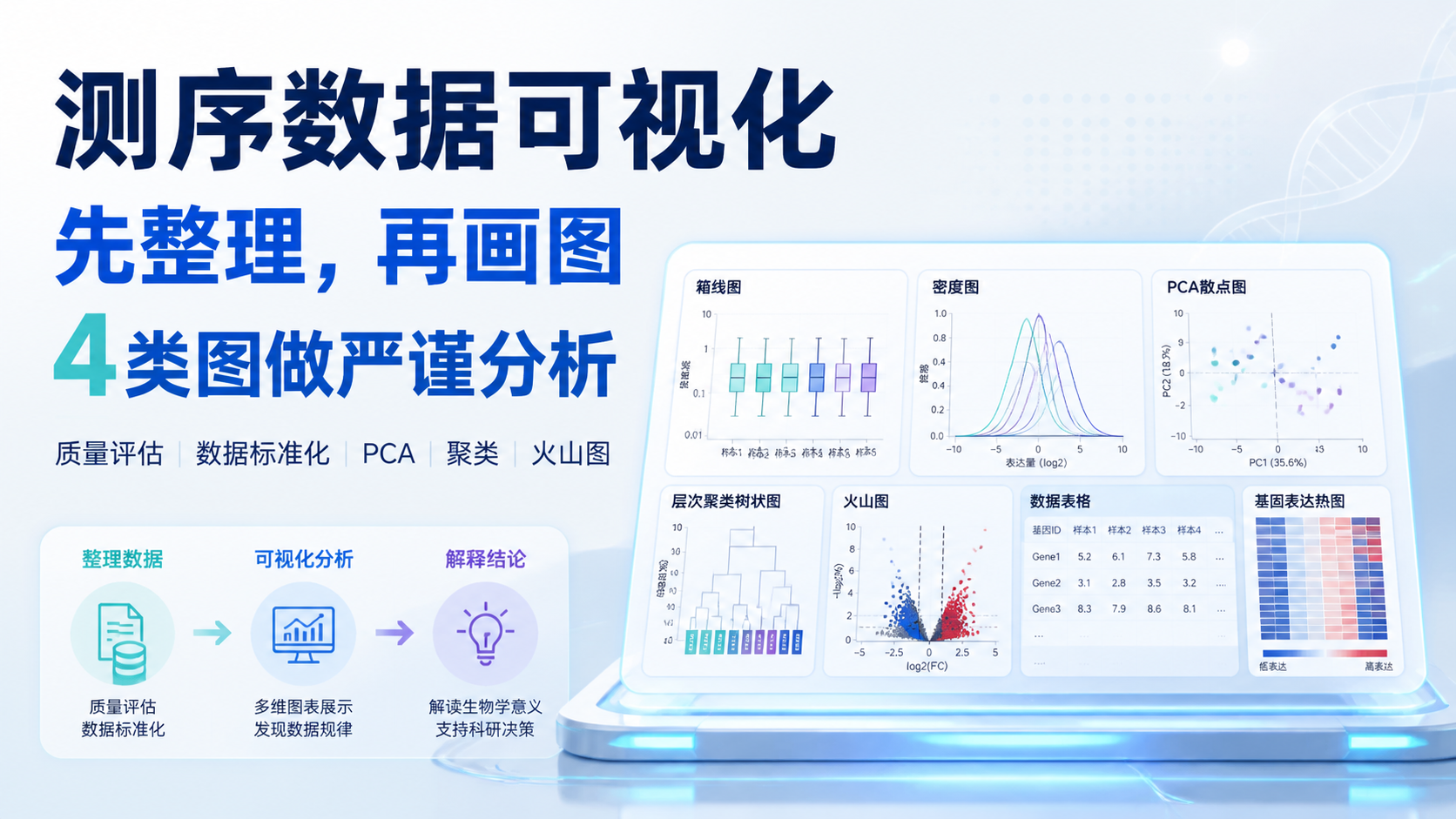
3. 第二步:用4类图完成严谨的测序数据可视化
3.1 箱线图,先看每个样本是否整齐
箱线图适合检查样本间表达范围是否一致。若多个样本的中位数相差明显,或者四分位距差异很大,说明存在批次效应、测序深度差异或样本异常。
在肿瘤与癌旁分析中,箱线图常用于比较Normal和Tumor是否整体偏移。
如果一个组整体偏高或偏低,先检查数据处理流程,再考虑生物学解释。
3.2 密度图,看表达值是否集中
密度图比箱线图更适合观察分布峰值。课程中提到,count数据常在低表达区和高表达区出现多个峰。经过VST后,峰形通常更集中,极端低值也会被一定程度压缩。
密度图特别适合做以下判断:
- 样本是否整体左移或右移。
- 是否存在明显双峰。
- 标准化后分布是否趋于一致。
- 是否有离群样本脱离主群。
密度图的价值在于,它能把“看起来正常”变成“分布上正常”。
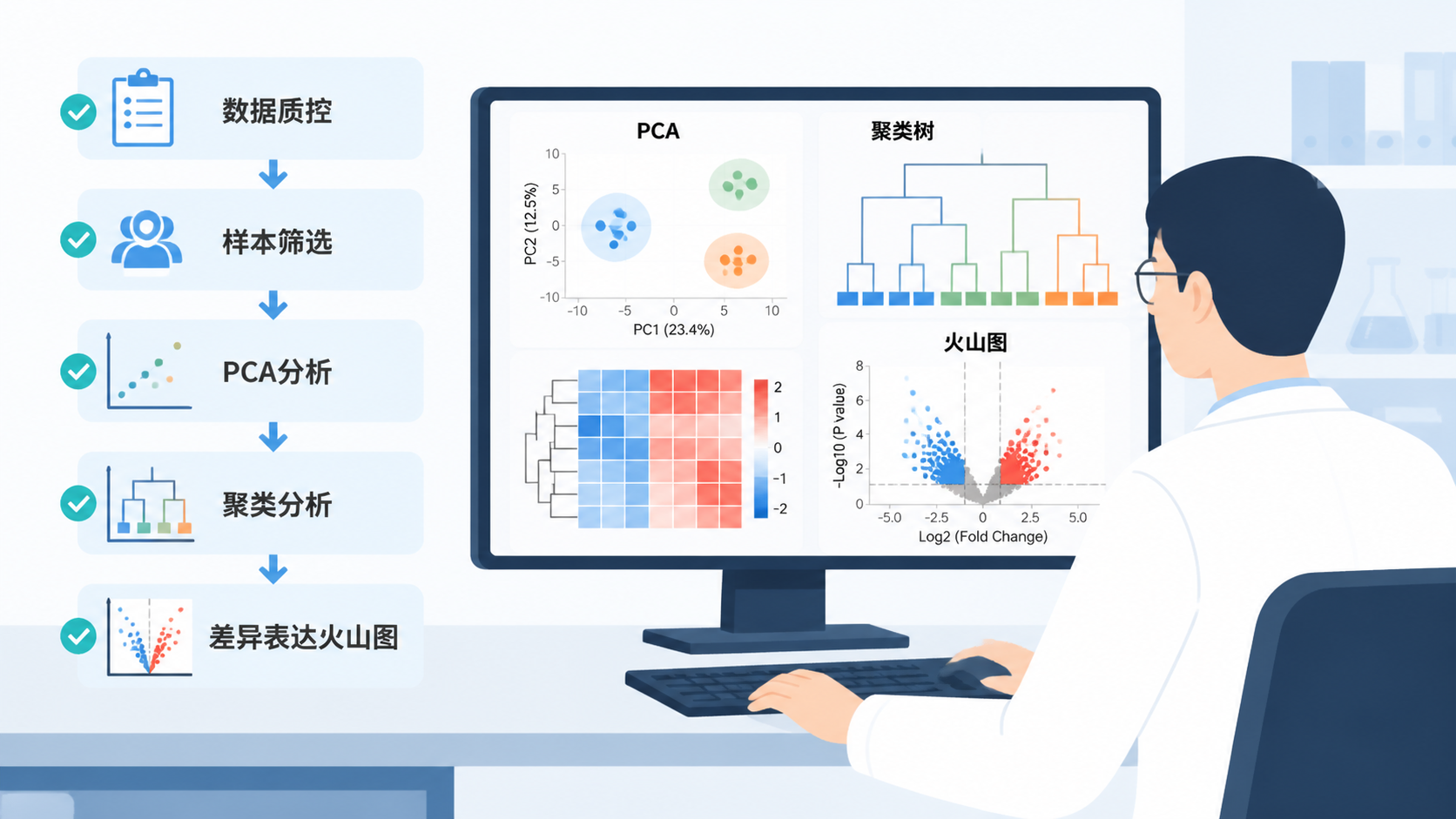
3.3 PCA图,看组间分离是否合理
PCA图是测序数据可视化中最常用的样本关系图之一。它可以直观展示样本是否按分组聚集,是否存在批次驱动的分离。课程中提到,DESeq2、factoextra、ggfortify等包都可以绘制PCA图。
PCA图重点看三件事:
- 同组样本是否靠近。
- 不同组是否分开。
- 是否有明显离群点。
如果Normal和Tumor在PCA图上明显分离,说明分组信号较强。
如果样本按批次而不是按分组聚集,就要优先处理batch effect。
PCA不是为了证明假设,而是为了检验数据是否支持假设。
3.4 层次聚类图,看样本是否自然成簇
层次聚类图适合进一步验证样本结构。它把样本之间的距离转化成树状分支,能快速发现哪些样本更接近。课程案例中,正常样本和肿瘤样本大体可以分开,但也可能出现少数混杂样本。这类样本要特别注意。
层次聚类图适合回答:
- 样本是否与预期分组一致。
- 是否存在混淆样本。
- 离群样本是否独立成枝。
- 分组结构是否稳定。
当PCA和层次聚类都支持分组时,数据可信度会更高。
4. 第三步:把可视化结果转成可解释结论
4.1 火山图不是第一步,而是最后一步
很多人一上来就画火山图,但火山图应该建立在前面质量评估通过之后。它的前提是数据已经完成整理、标准化和差异分析。课程中提到,绘制火山图时通常会基于log2FC和校正后的P值筛选显著基因,例如设置adj.P.Val < 0.001且|log2FC| > 2。
火山图的作用很明确:
- 展示显著上调和下调基因。
- 标记重点基因。
- 快速呈现差异方向和强度。
没有质量控制的火山图,往往只是“漂亮的错误结果”。
4.2 用统一标准标记显著基因
在实际分析中,标记基因要有统一标准。不要只凭视觉挑选。课程中给出的做法是先定义方向,再筛选显著基因。这样能避免主观性过强,也方便复现。
建议把以下信息写清楚:
- log2FC阈值。
- P值或校正P值阈值。
- 标注的基因数量。
- 是否去除缺失值。
可复现性,是测序数据可视化的重要组成部分。
4.3 结果要能回到生物学问题
可视化最终不是为了图本身,而是为了回答研究问题。比如,肝癌数据中,Normal与Tumor是否可分。某个候选基因在分组间是否符合预期。批次效应是否已经被控制。异常样本是否需要剔除。
如果图能帮助你回答这些问题,它就有分析价值。
如果图只能展示结果,却不能支持判断,它的价值就有限。
5. 实操中最容易踩的3个坑
5.1 直接拿原始count画图
原始count常受测序深度影响,分布偏态明显。直接拿来画箱线图或密度图,容易误判。建议先做标准化或VST转换,再进入测序数据可视化。
5.2 把离群样本当成正常波动
课程中提到,个别样本可能明显偏离主群。这些样本可能来自样本混淆、批次问题,甚至是不同类型组织混入。不能简单忽略。
离群样本越多,越要优先排查。
5.3 只看图,不看数据结构
图形只是展示形式。真正决定结果的是数据整理是否到位。表达矩阵、样本分组、注释信息、过滤规则,这些都要在作图前明确。否则即便图看起来“很好”,结论也可能站不住。
总结Conclusion
测序数据可视化的核心,不是把图画出来,而是把数据质量、样本结构和差异信号讲清楚。标准流程可以概括为三步:先整理数据,再做质量评估,最后输出差异结果图。箱线图、密度图、PCA图和层次聚类图,分别回答分布、偏差、分组和聚类四类问题。只有前面的检查通过,火山图和后续结论才更可靠。
如果你希望把这套流程做得更规范,可以借助解螺旋 的生信学习与分析资源,把数据整理、可视化和差异分析串成完整闭环。先把测序数据可视化做扎实,再谈发表和转化。
- 引言Introduction
- 1. 为什么测序数据可视化不能跳过
- 2. 第一步:先把数据整理到可视化标准
- 3. 第二步:用4类图完成严谨的测序数据可视化
- 4. 第三步:把可视化结果转成可解释结论
- 5. 实操中最容易踩的3个坑
- 总结Conclusion