引言Introduction
蛋白序列格式是蛋白组学、质谱分析和数据库检索的基础。很多医学生和科研人员在处理序列时,常会混淆FASTA、纯文本序列和比对文件,导致分析出错、结果难复现。先搞清楚蛋白序列格式,能显著提升后续注释、比对和投稿效率。

1. 蛋白序列格式的核心定义
1.1 什么是蛋白序列格式
蛋白序列格式,指的是用于存储和表达蛋白质氨基酸序列的标准文本或数据结构 。在生物信息学中,最常见的是FASTA格式。它以文本方式记录氨基酸序列,便于检索、比对和数据库收录。
蛋白质序列本质上是氨基酸的线性排列。其信息价值不在于字符本身,而在于序列顺序决定蛋白质结构、功能和相互作用位点 。因此,格式是否规范,直接影响后续分析质量。
1.2 为什么格式重要
在实际研究中,蛋白序列常用于以下场景。
- 数据库检索。
- 序列比对。
- 同源蛋白分析。
- 结构域预测。
- 质谱结果注释。
如果格式不规范,软件可能无法识别,或者误读序列名称、长度和注释信息。 对于需要复现的科研工作,这会直接影响数据可信度。
2. 最常见的蛋白序列格式:FASTA
2.1 FASTA格式的基本结构
FASTA是最常用的蛋白序列格式。它通常由两部分组成。
- 第一行是说明行,以“>”开头。
- 后面是氨基酸序列正文。
例如,说明行通常包含蛋白ID、物种名或简短描述。正文则是标准氨基酸单字母代码序列。
这种格式的优点很明确。结构简单,兼容性高,几乎可被所有主流生物信息学软件读取。 对蛋白组学、转录组翻译预测和数据库构建都非常常见。
2.2 FASTA在蛋白研究中的应用
在蛋白相关研究中,FASTA格式常用于:
- UniProt、NCBI、Ensembl等数据库下载。
- BLAST同源搜索。
- 蛋白家族分析。
- 蛋白质组学候选序列比对。
- 参考序列整理。
对科研人员来说,FASTA最重要的价值是标准化和可交换性 。无论是提交给平台做分析,还是自己本地处理,FASTA都是最稳妥的起点。
2.3 蛋白序列格式与核酸格式的区别
很多人会把蛋白序列格式与核酸序列格式混淆。二者都可能采用FASTA外壳,但内容不同。
- 核酸序列使用 A、T、C、G。
- 蛋白序列使用20种标准氨基酸字母。
同样是FASTA,核心差异在于序列字母表不同。 这也是为什么在上传文件前,要先确认分析软件接受的是核酸序列还是蛋白序列。
3. 蛋白序列格式与测序文件的关系
3.1 从原始数据到蛋白序列
蛋白序列格式并不是所有研究都直接获得的。很多情况下,先得到的是核酸测序数据,再通过翻译、注释或数据库映射,间接获得蛋白信息。上游知识库提到,原始序列文件如ab1、SRR、BCL等,通常先转成FASTA或FASTQ进行处理。
对蛋白研究来说,常见流程是:
- 测序或数据库获得核酸信息。
- 通过转录本注释或编码区预测蛋白序列。
- 输出为标准蛋白序列格式。
- 再用于比对、功能注释或结构预测。
也就是说,蛋白序列格式往往是分析链条中的中间成果,而不是起点。
3.2 质谱数据和蛋白序列格式
蛋白质测序中,质谱法可通过肽段质量指纹图谱或碎片信息推断序列。最终,研究者常需要将结果整理成可检索、可注释的序列文件。
在蛋白组学中,格式规范尤其重要。因为后续常要与数据库进行匹配,或者与功能位点、翻译后修饰信息整合。序列命名不清、分隔符混乱或物种信息缺失,都会降低分析效率。
4. 蛋白序列格式在数据库和分析工具中的常见要求
4.1 数据库检索对格式的要求
在UniProt、NCBI、PIR等数据库中,蛋白条目通常都带有标准化注释。常见字段包括:
- 蛋白ID。
- 参考序列编号。
- 物种来源。
- 分子长度。
- 功能注释。
- 结构域信息。
规范的蛋白序列格式,不只是“能读”,还要“能被准确识别”。 对于后续做同源比对、结构域定位和变体分析,这一点非常关键。
4.2 软件分析中最容易出错的点
在实际工作中,蛋白序列格式常见错误有以下几类:
- 说明行缺少“>”。
- 序列中混入空格、数字或中文符号。
- 把核酸序列误当作蛋白序列上传。
- 序列名称过长,超出软件识别范围。
- 多条序列写法不统一。
这些问题看似很小,但会导致软件报错、比对失败,或者输出异常结果。对于高通量分析,文件规范性本身就是质量控制的一部分。
4.3 蛋白序列格式与FASTA的延伸价值
FASTA不仅用于单条蛋白序列,也可用于multi-FASTA,即把多条序列放在一个文件中。每条序列以前导“>”分隔。这在批量分析中很常见。
例如,进行以下工作时都很实用:
- 多蛋白比对。
- 结构域筛选。
- 家族聚类。
- 批量BLAST。
这类场景中,统一的蛋白序列格式能减少人工整理时间,也能提高分析可重复性。
5. 蛋白序列格式的5个实用要点
5.1 要点一,先确认序列类型
蛋白序列格式对应的是氨基酸序列,不是DNA或RNA。提交前要先判断文件内容是否为蛋白序列。这个判断最基本,也最容易被忽略。
5.2 要点二,优先使用标准FASTA
对于大多数分析场景,标准FASTA是首选。它简单、兼容、通用。如果没有特殊平台要求,优先用FASTA整理蛋白序列。
5.3 要点三,说明行要简洁规范
说明行建议保留必要信息,例如蛋白ID、物种和简短描述。不要把过多无关内容塞进标题里。这样更利于数据库读取和后续脚本处理。
5.4 要点四,保持序列字符纯净
正文只保留标准氨基酸字母。不要加入空格、编号、标点或换行杂项。若存在未知残基,应使用软件或数据库认可的标准标记,并在分析前确认规则。
5.5 要点五,按下游任务选择附加信息
如果后续要做结构分析、修饰分析或位点预测,建议同步保留以下信息:
- 蛋白来源。
- 参考数据库编号。
- 物种信息。
- 异构体信息。
- 结构域注释。
蛋白序列格式不是孤立文件,而是整个研究链条的入口。 前期整理越规范,后续越省时间。
总结Conclusion
蛋白序列格式的核心,是把蛋白质氨基酸信息用标准、可读、可分析的方式表达出来。对医学生、医生和科研人员来说,最常见、最实用的形式就是FASTA。它便于数据库检索、质谱注释、序列比对和功能研究。掌握蛋白序列格式,不只是会看文件,更是提高科研效率和结果可信度的基础能力。
如果你需要进一步把蛋白序列整理成适合数据库检索、质谱分析或下游注释的规范格式,可以借助解螺旋品牌的生信内容与工具服务,减少格式错误,提升分析效率。
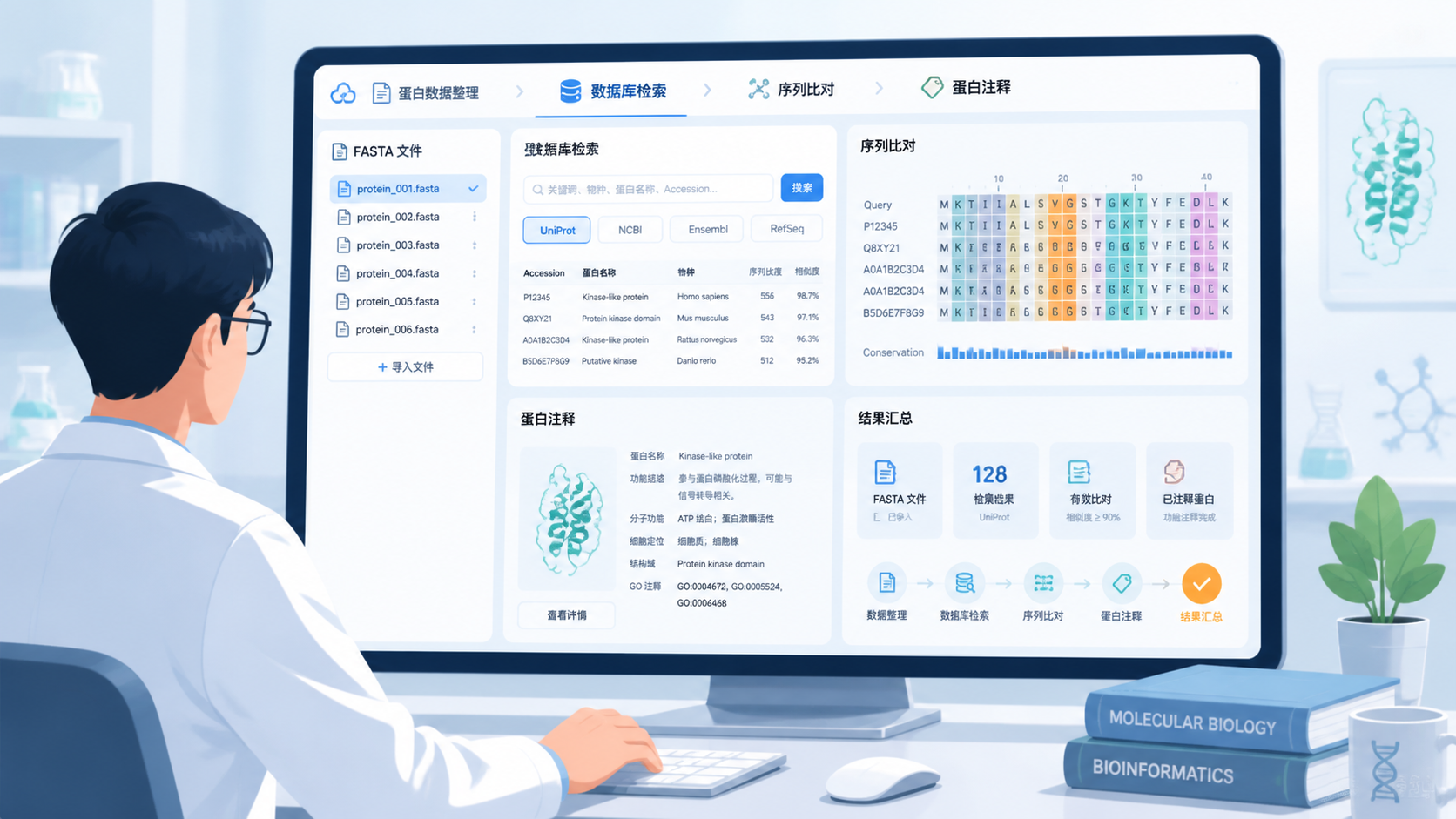
- 引言Introduction
- 1. 蛋白序列格式的核心定义
- 2. 最常见的蛋白序列格式:FASTA
- 3. 蛋白序列格式与测序文件的关系
- 4. 蛋白序列格式在数据库和分析工具中的常见要求
- 5. 蛋白序列格式的5个实用要点
- 总结Conclusion