引言Introduction
转录组上游分析里,很多问题不是不会做,而是转录本序列格式不规范 。格式错一位,后面的比对、定量、去重都会受影响。尤其是从测序数据到表达表这一步,读懂FASTQ、SAM、BAM和表达矩阵的关系,是基础中的基础。
1. 先弄清楚转录本序列格式的基本概念
1.1 FASTQ是最常见的原始序列格式
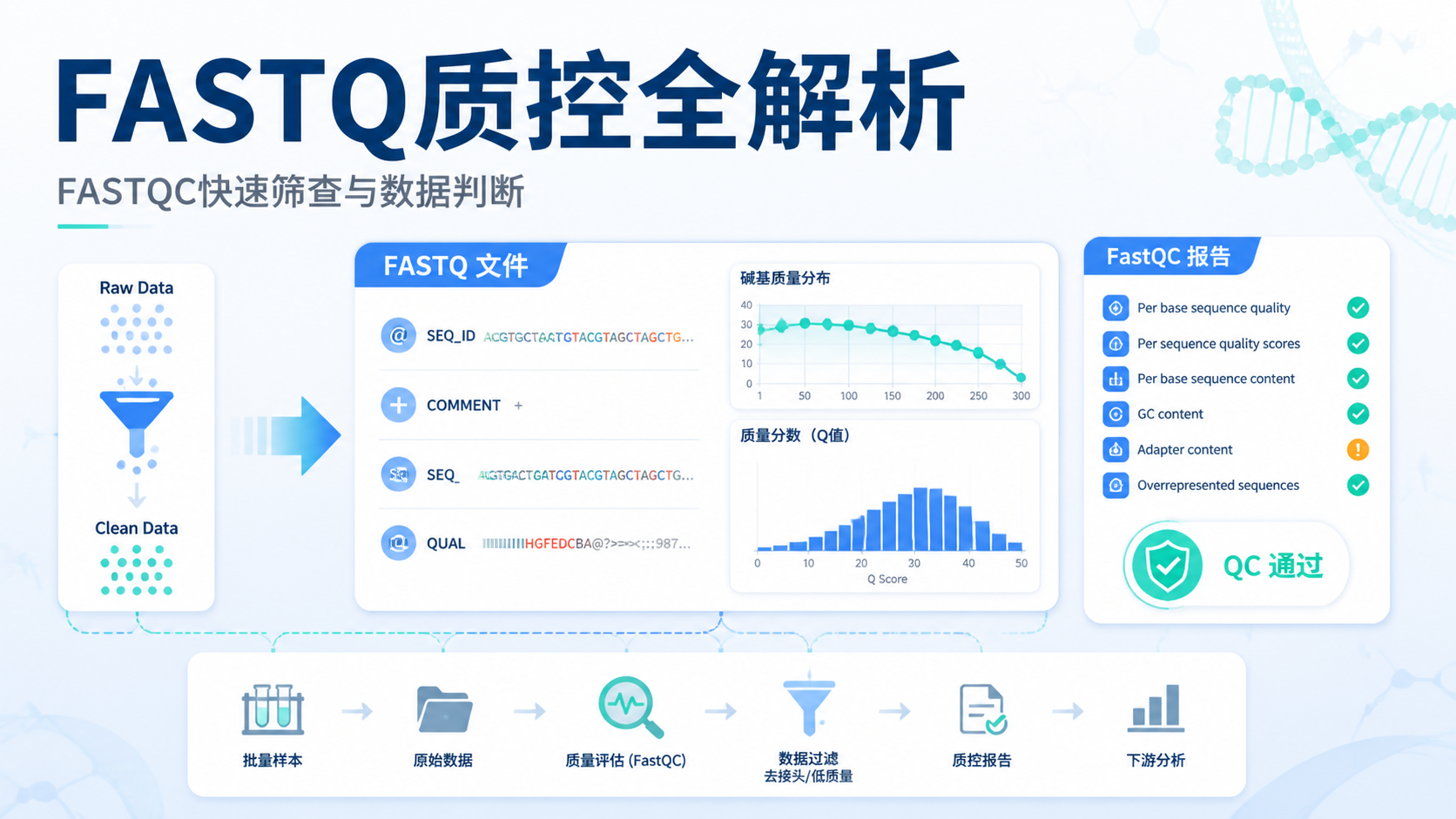
转录本序列格式最常见的起点是FASTQ。它是测序仪输出的原始数据格式。每条序列由4行组成 。第一行是序列ID,第二行是碱基序列,第三行是分隔行,第四行是质量值。
FASTQ的价值,不只在于保存序列,还在于保存质量信息。质量值通常采用Phred评分体系。Q值越高,表示测序出错概率越低 。这也是后续质控和剪切的依据。
在单细胞转录组中,FASTQ往往还分为R1、R2,甚至I1。不同文件承载的信息不同。常见情况是,R2包含barcode和UMI,R1承载转录本序列信息 。这一步如果混淆,后面很难补救。
1.2 FASTA、SAM、BAM各自承担什么角色
除了FASTQ,常见的还有FASTA、SAM和BAM。它们不是同一阶段的文件,但都和转录本序列格式有关。
- FASTA:只保留序列本身,不含质量值。
- SAM:存储比对结果,包含read与参考序列的对应关系。
- BAM:SAM的二进制压缩格式,体积更小,检索更快。
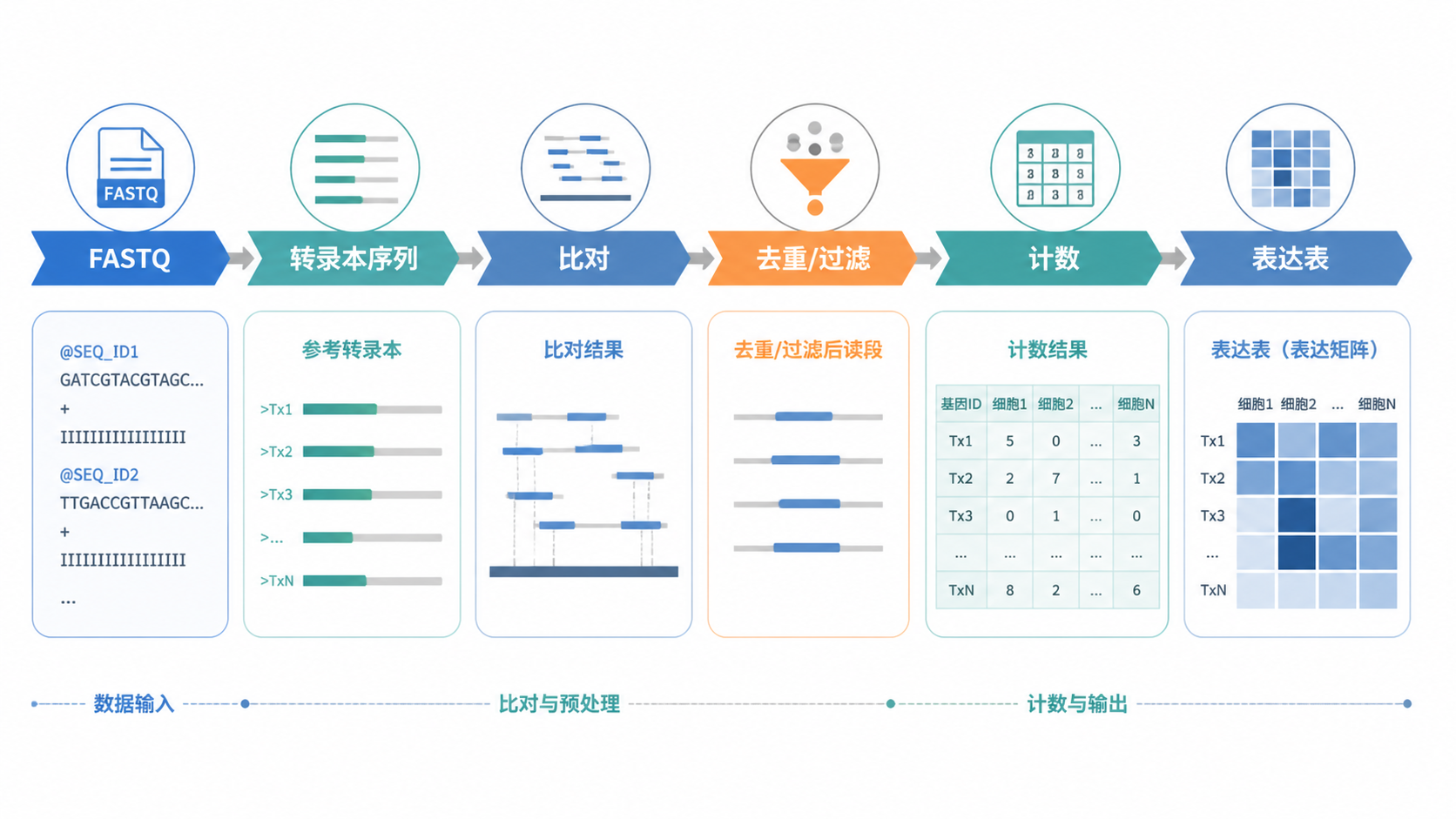
如果目标是做转录本定量,FASTQ通常是起点,SAM/BAM是比对后的中间结果。 理解这一点,就能把文件格式和分析流程对应起来。
1.3 为什么规范格式比“能打开”更重要
很多人觉得文件能打开就行,但生信分析不是这样。一个标准的转录本序列格式,必须满足后续软件可识别、可比对、可重复分析。
比如,FASTQ中的read ID必须对应,R1和R2要能通过第一行信息匹配。若命名混乱,barcode无法正确拆分,UMI无法正确挂载,表达表就会偏差。格式规范,本质上是在保证数据链条不被打断。
2. 单细胞转录组里,转录本序列格式如何组织
2.1 先按barcode分离细胞
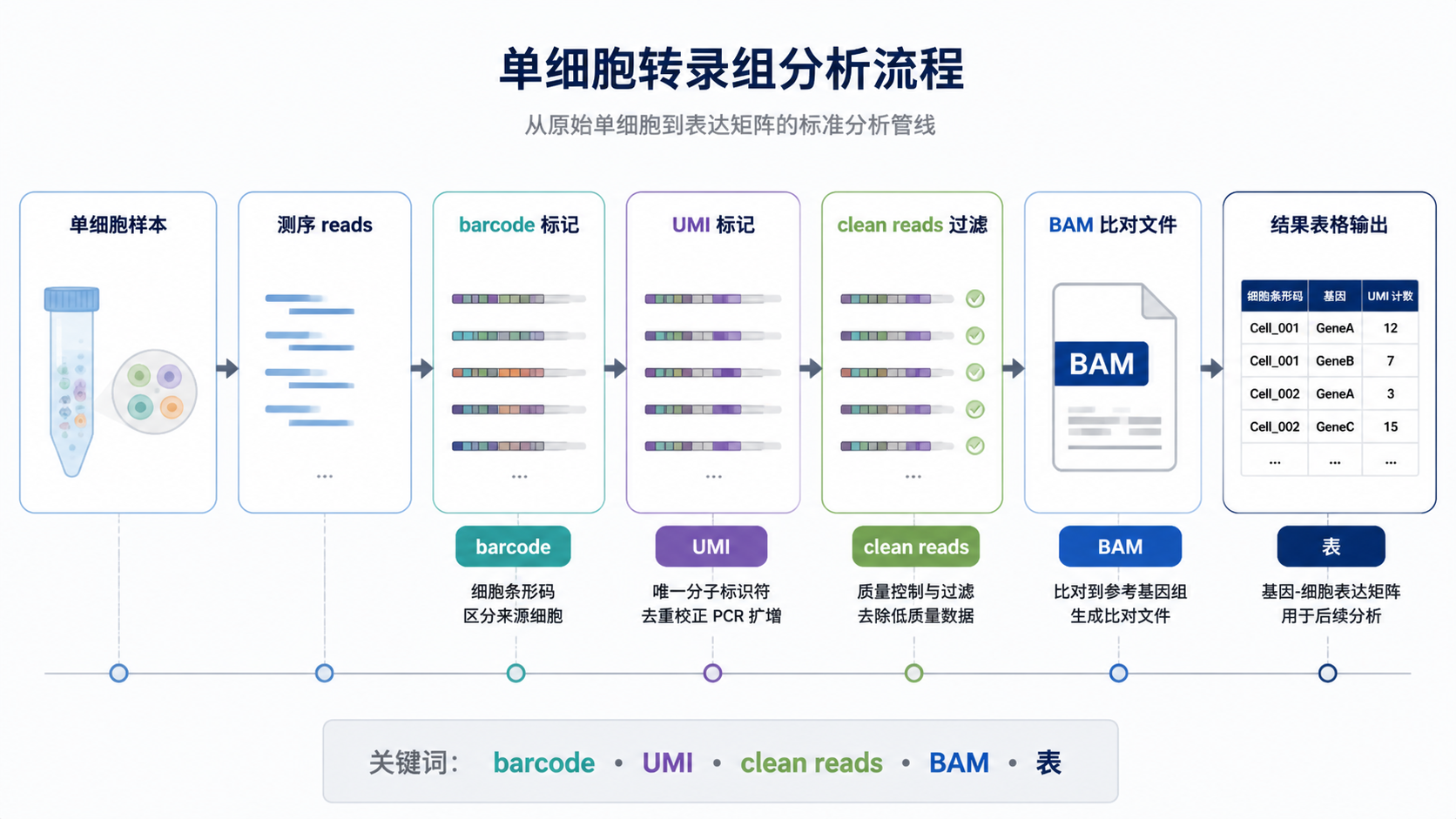
单细胞转录组上游处理中,第一步通常是根据barcode分离细胞。上游知识库中提到,测序公司返回的数据可通过R2前8 bp的barcode进行拆分。
这是因为barcode能区分不同细胞。同一批混合测序的数据,必须先按barcode拆分成单细胞文件,才能进入下一步分析。 在96细胞建库场景中,这一步尤为关键。
2.2 再把UMI信息添加到R1
分离完barcode后,还需要处理UMI。UMI通常位于R2的第9到第16 bp。由于后续主要分析R1,因此常见做法是把UMI信息附加到R1的第一行。
这样做的原因很简单。第一行的read ID会在后续步骤中保留。把UMI挂到R1文件的序列标识中,便于后面去除PCR重复。 这是单细胞表达矩阵构建里的常见思路。
2.3 R1才是真正承载转录本信息的核心文件
在这类建库方案中,R2更多提供信息标签,R1才是转录本主体。R2中的barcode和UMI主要用于区分细胞和分子来源,不直接代表基因表达。
因此,规范写转录本序列格式时,最重要的不是“写得像不像序列”,而是能否准确保留转录本本体、barcode、UMI三类信息的边界 。边界一乱,后面的表达量统计就不可靠。
3. 从测序数据到表达表,格式规范要经历哪些步骤
3.1 质控前先识别异常序列
拿到FASTQ后,先看质量,再看结构。常见需要处理的内容包括:
- 低质量碱基。
- 不确定碱基N。
- PolyA尾。
- adapter残留。
- TSO序列残留。
其中,TSO序列和PolyA尾尤其容易影响后续比对 。在单细胞转录组中,转录本往往是3’端片段,不是全长转录本,所以这些污染必须清理。
3.2 修剪后再比对到参考基因组
质控后,clean reads 才进入比对。比对工具中,单细胞转录组常用STAR,速度快,适合大规模数据。也可见HISAT、TopHat等工具,但实际中STAR使用更广。
比对的目的是把转录本序列定位到基因组上。没有准确比对,就没有可靠的count。 而count又是后续差异分析和表达矩阵构建的基础。
3.3 unique mapping和去重决定最终表达表
比对完成后,常常只保留unique mapping,也就是唯一比对上的转录本。随后根据UMI去除PCR重复,避免同一分子被重复计数。
这一步的意义非常明确。表达表要反映真实分子数,而不是扩增次数。 所以,规范的转录本序列格式必须支持UMI追踪,否则去重无从谈起。
4. 写转录本序列格式时,最容易出错的地方
4.1 文件命名不统一
命名混乱是最常见错误之一。比如R1、R2、I1没有严格对应,样本名写法不一致,都会导致脚本批量处理失败。
建议固定命名规则,例如:
- 样本名_Rep1_R1.fastq
- 样本名_Rep1_R2.fastq
- 样本名_Rep1_I1.fastq
统一命名不是形式问题,而是可追溯性问题。
4.2 read ID不匹配
R1和R2必须能通过第一行信息对应。上游知识库明确提到,R1和R2的第一行信息是相同的,可以据此调取对应序列。
如果read ID对不上,barcode拆分和UMI添加都会出错。最终可能出现一个细胞的序列被分到另一个细胞,直接影响表达矩阵准确性。
4.3 忽略质量值和污染序列
有些人只关注碱基序列,不看质量值。这样很危险。FASTQ第四行的质量值,直接决定是否需要剪切低质量碱基。
同样,PolyA、TSO、adapter、N碱基都不是可忽略项。 这些内容不清理,会降低比对率,也会增加假阳性。
5. 规范写法的实操原则
5.1 按“信息层”分文件
建议把不同信息分层处理,而不是混在一起。
- 原始层:FASTQ原始文件。
- 标签层:barcode、UMI相关信息。
- 清洗层:trim和clean文件。
- 比对层:SAM/BAM文件。
- 结果层:count或表达表。
分层管理,是规范转录本序列格式的核心原则。
5.2 保留可追溯链条
每一步都要能回溯。也就是说,任何一个表达值,都应能追到原始read。这样在答审稿意见、重复分析、补充质控时,都更有说服力。
对于医学生、医生和科研人员来说,这一点尤其重要。因为论文审稿时,别人常问的不是“你有没有结果”,而是“你的结果能不能复现”。格式规范,就是复现的起点。
5.3 用标准软件和标准字段
尽量使用通用工具和标准输出格式。比如FASTQ、SAM、BAM这些格式,生态成熟,工具支持丰富。不要随意改动标准字段含义。
标准化格式能显著减少脚本兼容问题,也更利于团队协作。
6. 结尾前再看一遍关键逻辑
转录本序列格式不是单纯的文件排版问题,而是单细胞和转录组分析能否顺利推进的前提。它决定了barcode能不能拆分,UMI能不能去重,reads能不能正确比对,count能不能真实反映表达。
如果你正在做单细胞转录组数据分析,建议把这条链条记牢:
- FASTQ保存原始序列和质量。
- barcode分离细胞。
- UMI挂载到可追踪位置。
- 去除低质量和污染序列。
- 比对到参考基因组。
- 生成count和表达表。
每一步都在为最终的表达矩阵服务。
总结Conclusion
规范写好转录本序列格式,核心是三件事。保留原始信息,保证格式标准,支持后续去重和定量。 对于单细胞转录组而言,barcode、UMI、R1/R2对应关系、质控和比对结果,缺一不可。
如果你希望把这些步骤真正落地,减少格式错误和流程返工,可以借助解螺旋 的系统化生信内容与实战资源,按标准流程搭建你的转录组分析链条。这样,转录本序列格式不再是难点,而是你获得可靠表达表的起点。
- 引言Introduction
- 1. 先弄清楚转录本序列格式的基本概念
- 2. 单细胞转录组里,转录本序列格式如何组织
- 3. 从测序数据到表达表,格式规范要经历哪些步骤
- 4. 写转录本序列格式时,最容易出错的地方
- 5. 规范写法的实操原则
- 6. 结尾前再看一遍关键逻辑
- 总结Conclusion