





引言Introduction
GFF文件解读对很多医学生、医生和科研人员来说并不陌生,但真正上手时,常卡在“字段太多、层级太乱、信息看不懂”。如果你也在做基因注释、转录本分析或可视化,GFF文件解读就是必须掌握的基础技能。
1. 先搞清楚GFF文件是什么
1.1 GFF文件的核心作用
GFF是基因组功能注释文件,常用于描述基因、转录本、外显子、CDS等特征在基因组上的位置。它本质上是一个“坐标说明书”。GFF文件解读的关键,不是背格式,而是理解每一行在说明什么生物学信息。
对于科研人员来说,GFF常与FASTA序列、测序结果、注释流程一起使用。它可以帮助你把“序列”变成“可解释的基因结构”。
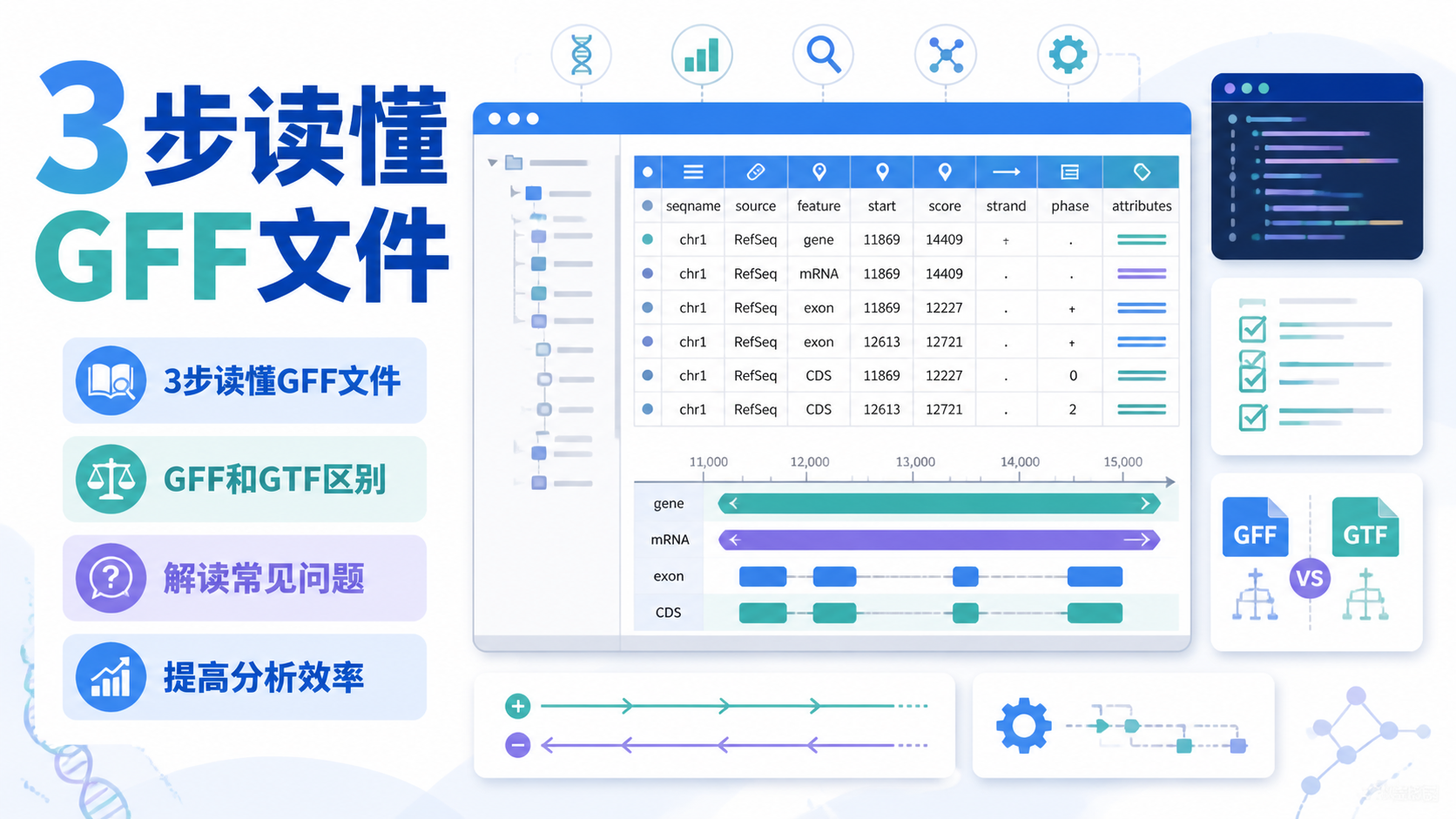
1.2 GFF和GTF的区别
很多人会把GFF和GTF混淆。两者都用于基因注释,但结构并不完全一样。
- GFF通常更通用,版本常见为GFF3。
- GTF更偏向转录本和基因模型分析。
- GFF文件解读时,最先确认的是文件版本。因为不同版本的字段规则不一样。
如果版本没看清,后面的解析很容易出错。尤其是在脚本提取基因、外显子或CDS时,字段名和属性写法差异会直接影响结果。
2. 3步掌握GFF文件解读
2.1 第一步,先看每一列
标准GFF文件通常有9列。可以把它理解为一张表,每列负责一个信息。
常见字段包括:
- Seqid,染色体或序列名称。
- Source,注释来源。
- Type,特征类型,如gene、mRNA、exon、CDS。
- Start,起始坐标。
- End,终止坐标。
- Score,得分。
- Strand,链方向。
- Phase,阅读框信息,主要用于CDS。
- Attributes,附加信息,如ID、Parent、Name。
GFF文件解读的第一原则,是先判断这9列分别在描述什么。
坐标决定位置,Type决定对象,Attributes决定层级关系。
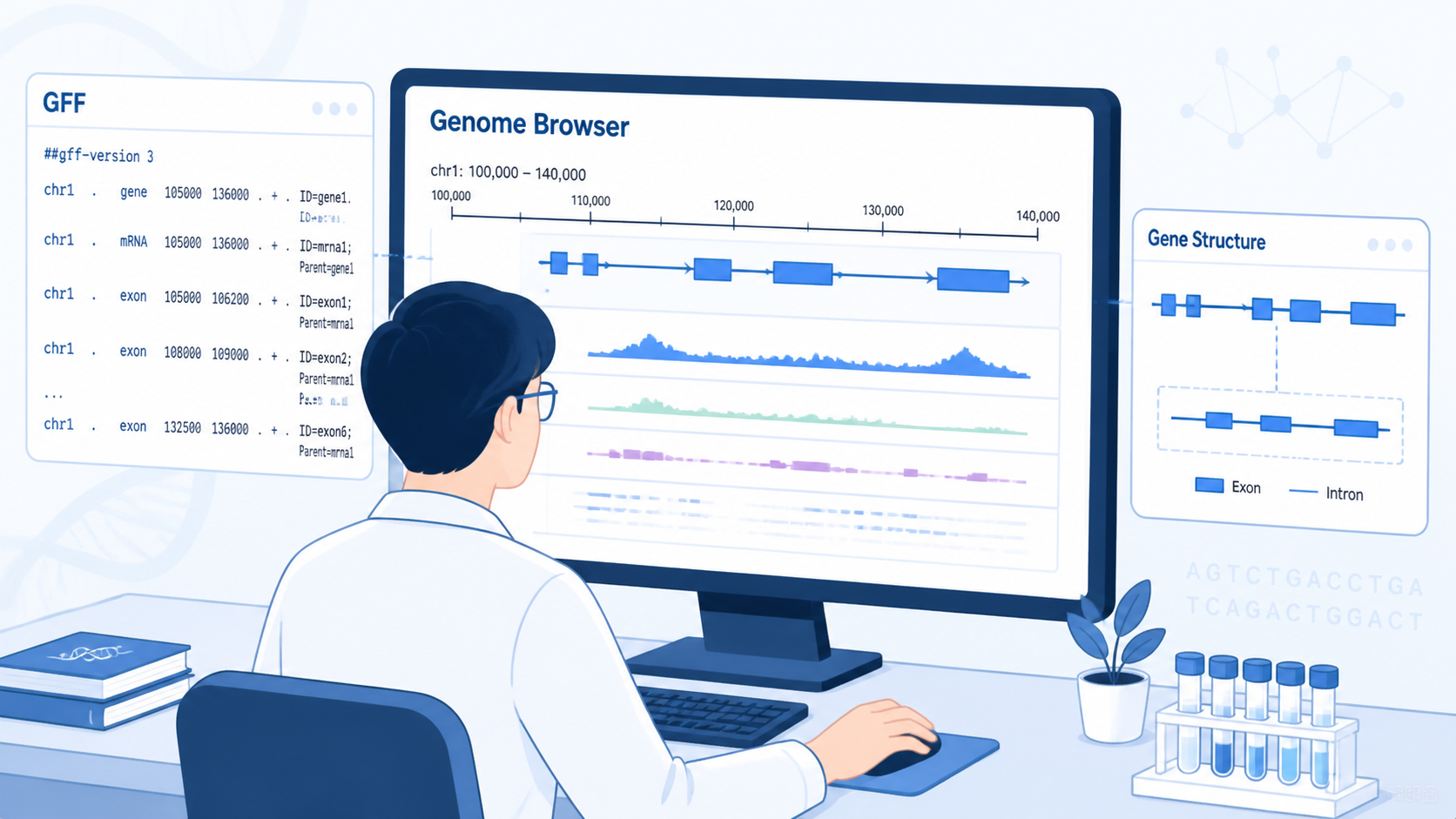
举个简单例子。一个gene下面可能有多个mRNA,每个mRNA下面又有多个exon和CDS。你看到的不只是“位置”,而是“结构树”。
2.2 第二步,理解层级关系
GFF3最重要的特点之一,是用Parent和ID建立父子关系。这个关系决定了基因结构如何组织。
- gene是上层特征。
- mRNA或transcript通常是gene的子特征。
- exon、CDS、UTR等通常属于转录本的下一级。
GFF文件解读如果只看单行,往往会丢失上下文。
真正有价值的是把同一个基因相关的所有行串起来看。
这一步在实际工作中很重要。比如你想统计某个基因有几个转录本,或者提取某条转录本的外显子结构,都必须先识别Parent关系。否则很容易把不同转录本的片段混在一起。
2.3 第三步,结合生物学问题读文件
GFF不是为了“看格式”而存在的。它的价值在于回答具体问题。
你可以用它做这些事:
- 查某个基因的位置和长度。
- 看某条转录本包含哪些外显子。
- 判断CDS是否完整。
- 和RNA-seq、变异注释结果联合分析。
- 在IGV或基因组浏览器中进行可视化。
GFF文件解读的最终目标,是把注释信息转换成可分析、可验证的生物学结论。
如果你在做课题,建议先明确问题,再回头看文件。这样效率最高。比如你要研究剪接变异,就重点看transcript、exon、splice相关结构。你要做功能注释,就重点看gene、CDS和protein相关属性。
3. 实战中最常见的4个问题
3.1 字段很多,看起来很乱
这是最常见的困惑。解决方法很简单,先固定顺序:
- 先看Type。
- 再看Start和End。
- 然后看Strand。
- 最后看Attributes。
GFF文件解读时,不要一开始就盯着整行属性。先抓主干,再看细节。
这样你会更快识别这条记录属于gene、mRNA还是exon。
3.2 坐标方向容易搞错
GFF使用的是基因组坐标,不是蛋白坐标。Start和End通常表示在参考序列上的位置。Strand会告诉你该特征位于正链还是负链。
这对下游分析非常关键。因为负链基因的转录方向与坐标增长方向相反。如果忽略Strand,GFF文件解读就可能导致外显子顺序、ORF判断和可视化全部出错。
3.3 Attributes太长,不知道看什么
Attributes里常见信息很多,但真正需要优先关注的通常是:
- ID
- Parent
- Name
- Alias
- Ontology_term
- Dbxref
其中,ID和Parent最关键。前者标识当前对象,后者标识归属关系。对于大多数分析任务来说,这两项已经能解决80%的定位和追踪问题。
3.4 不同软件解析结果不一致
这是因为不同工具对GFF版本和字段容错不同。有的软件严格要求GFF3格式,有的软件可以读部分GTF字段,但不会完全一致。
所以在正式分析前,建议你先做三件事:
- 确认文件版本。
- 检查是否有缺失字段。
- 用一个可信工具先做小样本验证。
GFF文件解读不能只依赖“能打开”,还要确认“读得对”。
4. 提高GFF文件解读效率的实用方法
4.1 先用浏览器看,再用脚本提取
如果是初学者,建议先用基因组浏览器或表格工具快速浏览整体结构,再用脚本提取目标区域。这样更容易建立直觉。
例如,你可以先观察某个基因附近有哪些Type,再决定是否提取该区域的exon或CDS。
先看全局,再做局部,是GFF文件解读效率最高的方式。
4.2 建立固定检查清单
每次分析前,建议固定检查以下内容:
- 文件是否为GFF3。
- 是否存在标准9列。
- ID和Parent是否完整。
- 是否有重复或异常坐标。
- 是否与参考基因组版本一致。
这份清单能显著减少返工。特别是在课题组协作、跨平台数据整合时,格式问题往往比算法问题更先暴露。
4.3 和下游分析目标绑定
如果你的目标是论文、课题或数据库整理,GFF文件解读最好和具体分析绑定。
例如:
- 基因结构研究,重点看gene、mRNA、exon。
- 编码区分析,重点看CDS和phase。
- 可视化分析,重点看坐标和层级。
- 变异注释,重点看特征与基因位置关系。
只有把GFF文件解读和研究问题绑定,文件才真正“可用”。
总结Conclusion
GFF文件解读并不难。难点主要在于版本、字段和层级关系。只要记住三个步骤,先看列、再看关系、最后结合问题分析,就能快速上手。对于医学生、医生和科研人员来说,这是一项非常实用的基础能力。
如果你希望更高效地完成基因注释、文件整理和结果展示,可以借助更专业的工具和资源提升效率。解螺旋品牌 持续为生命科学研究者提供实用内容与方法支持,帮助你更快掌握GFF文件解读,减少试错时间,把精力放在真正的科研问题上。

- 引言Introduction
- 1. 先搞清楚GFF文件是什么
- 2. 3步掌握GFF文件解读
- 3. 实战中最常见的4个问题
- 4. 提高GFF文件解读效率的实用方法
- 总结Conclusion



