引言Introduction
临床研究里,很多课题不是“做不出来”,而是“样本量算错了”。样本量计算影响因素 一旦判断偏差,研究就可能出现把握度不足、结论不稳、审稿被质疑等问题。对医学生、医生和科研人员来说,先弄清这些因素,比盲目套公式更重要。

1. 为什么样本量不是“越多越好”
1.1 研究不是无限抽样,样本量要兼顾准确性和可行性
临床研究本质上是抽样研究。样本太少,代表性差,结果容易受偶然波动影响。比如横断面研究中,如果只调查很少的人,患病率可能只出现0%、50%或100%这种极端值,几乎不能反映真实情况。
但样本也不是越大越好。样本过大,会增加时间、成本和伦理负担。 所以样本量的目标不是“尽可能大”,而是“足够支撑结论”。
1.2 研究成败常常卡在样本量
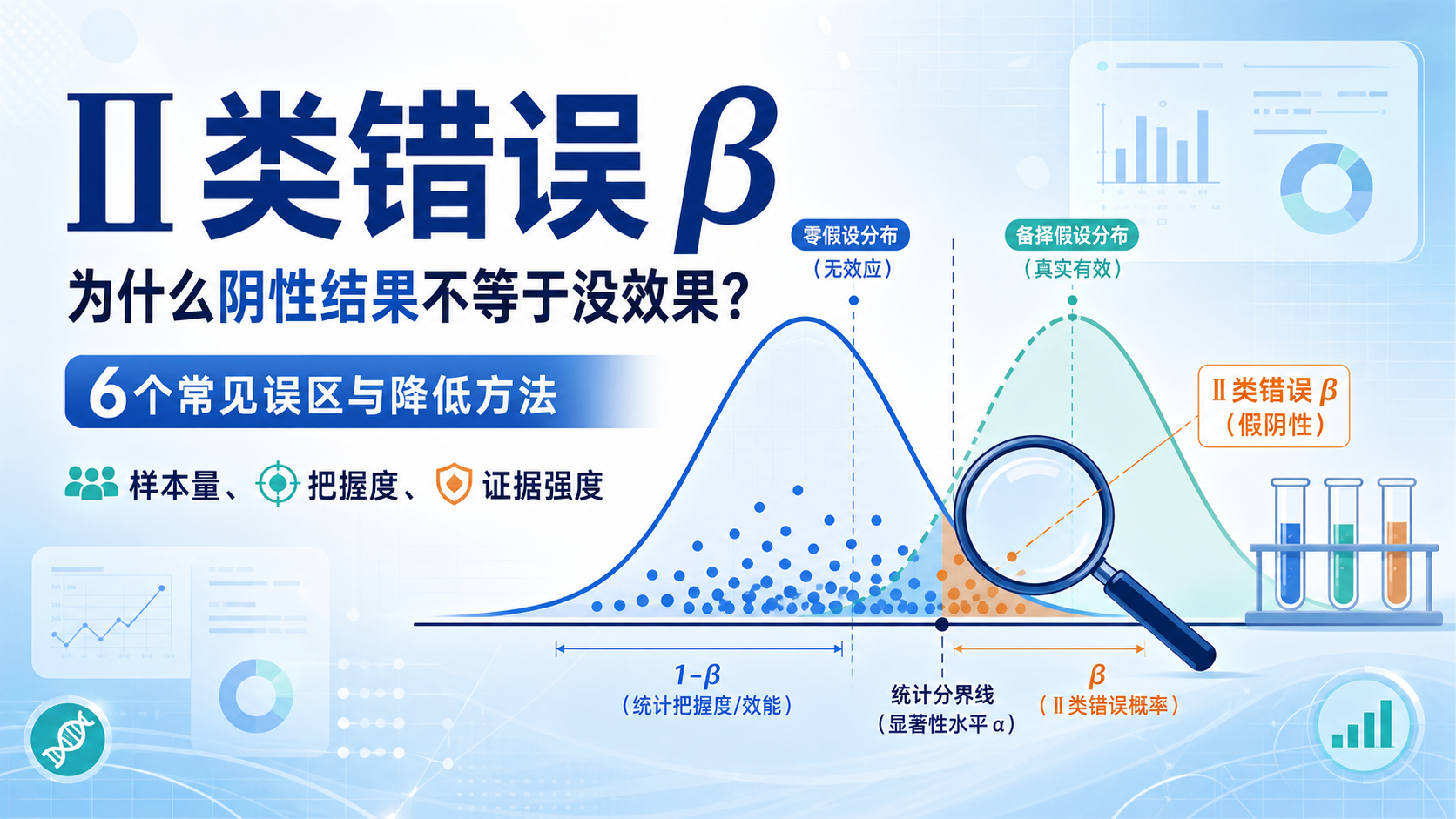
很多阴性结果并不一定说明“没有效应”,而可能是检验效能不足 。在RCT里尤其常见。设计阶段如果样本量不足,后面再做多因素分析、亚组分析,结论都会变得更不稳定。
这也是为什么专家、审稿人和伦理委员会都会先问样本量。因为它直接关系到研究是否有能力回答问题。
2. 样本量计算影响因素有哪些
2.1 把握度,也就是power
把握度表示研究“识别真实差异”的能力,通常写作1-β。常见取值是0.8或0.9,最低一般不建议低于0.75。把握度越高,所需样本量越大。
这是因为你要求研究更敏感,就必须纳入更多对象,减少随机误差。临床上如果希望更稳妥地发现真实差异,通常会优先提高把握度,但代价就是样本量上升。
2.2 α值,也就是检验水准
α代表把真的判成假的风险,通常设为0.05。α越小,样本量越大。
同样条件下,双侧检验所需样本量通常大于单侧检验。
这意味着,如果研究问题本身明确只关注一个方向,设计上可以考虑单侧检验。但前提是必须有充分的专业依据,不能为了减少样本量而随意选择。
2.3 差值,也就是区分度
差值是你希望检出的最小有意义差异。它往往依据专业经验、预试验或既往文献设定。差值越小,样本量越大。
这点非常关键。你想检测的差异越细微,就越需要更大的样本去分辨。换句话说,如果把目标设得太“苛刻”,研究成本会迅速上升。
2.4 数据类型和研究设计
不同研究类型,对样本量的要求完全不同。
常见场景包括:
- 横断面研究,常按患病率或均数估计
- 病例对照研究或队列研究,按暴露率、结局率或效应量估计
- RCT,按主要结局指标计算
- 多因素回归,常需要经验性估计
研究设计越复杂,样本量计算影响因素就越多。 如果设计阶段没有想清楚,后面统计分析会被迫“补救”,这通常不理想。
3. 为什么这些因素会直接影响研究结论
3.1 样本量不足,会放大二类错误
二类错误就是把假的当成真的,或者把真实存在的差异判成“不存在”。样本量不足时,β增大,power下降,研究更容易出现假阴性。
这对临床研究非常危险。因为一个“没发现差异”的结论,可能只是研究没能力检出差异,而不是治疗真的无效。
3.2 样本量过大,也不等于更高质量
很多人误以为样本越大越好。其实不然。样本过大时,哪怕极小、甚至临床意义不大的差异,也可能因为统计学显著而被检出。
统计学显著,不等于临床有意义。
所以样本量设计必须和临床意义绑定。真正重要的是,研究是否能回答临床问题,而不是单纯追求P值漂亮。
3.3 不同分析集也会影响结论
在RCT中,ITT、全分析集、PP集的选择会影响结果解释。
有效性试验通常更偏向保守分析,如ITT或全分析集。
等效或非劣效试验中,常更关注PP集,以避免效应被稀释。
这说明样本量不是孤立参数。它和分析集、终点类型、检验策略是联动的。一旦样本量与分析策略不匹配,研究结论就可能失真。
4. 常见误区:为什么很多研究会“算了也白算”
4.1 只给病名,无法准确估算
“我想研究某种病,需要多少样本?”这个问题本身不完整。
没有研究目的、结局指标、预期差值和设计类型,就无法严谨计算。
样本量估计不是按病名拍脑袋,而是按研究问题计算。
4.2 事后补样本量,不等于科学
有些研究是在数据收完、结果出来后,才补做样本量估计。这种做法不能真正证明设计合理。
样本量应在研究开始前完成。
事后更适合评估把握度,而不是反推设计正确性。
4.3 经验公式能用,但要知道边界
对多因素回归,精确计算并不总是容易。文献中常见经验法则是:自变量数的5到20倍。比如10个自变量,样本可能需要100到200例。
但这只是经验估计,不是万能公式。事件发生率、终点类型、模型复杂度都会影响最终要求。科研人员不能只记倍数,还要看研究场景。
5. 实操上,如何抓住样本量计算影响因素
5.1 先明确4个核心问题
做样本量前,先回答:
- 研究目的是什么。
- 主要结局是什么。
- 数据类型是什么。
- 想检出的最小差异是多少。
这4个问题决定了你后面用什么公式、什么参数、什么分析方法。
5.2 再确定统计参数
通常需要明确:
- α,常取0.05
- power,常取0.8或0.9
- 预期差值或效应量
- 方差、标准差或患病率等先验信息
这些参数任何一个设错,最终样本量都会偏离。
5.3 最后做可行性修正
理论样本量算出来后,还要结合:
- 受试者招募难度
- 依从性
- 失访率
- 伦理和经费限制
- 法规要求
这一步非常现实。研究设计不能只停留在公式上,还要落到临床执行。
6. 为什么这一步决定研究成败
样本量不是附属工作,而是研究设计的核心环节。它决定了研究能不能:
- 检出真实效应
- 控制假阴性风险
- 支撑主要结论
- 经得起同行评审
样本量计算影响因素,本质上是在决定你的研究“有没有资格得出结论”。
如果参数设定不合理,再好的课题也可能因为样本不足而失败;如果设计严谨,研究效率和可信度都会明显提升。
总结Conclusion
样本量计算影响因素并不只是统计学细节,而是临床研究成败的前置条件。把握度、α值、差值、研究设计、数据类型和分析策略,都会共同决定最终样本量。对医学生、医生和科研人员来说,真正专业的做法不是套公式,而是先理清研究目的,再做严谨估算。
如果你正在做RCT、横断面研究或多因素分析,但对样本量设计、统计参数和分析集选择仍不确定,可以借助解螺旋 的专业内容与科研服务,把样本量设计前置到研究起点,减少返工,让课题更稳、更容易发表。

- 引言Introduction
- 1. 为什么样本量不是“越多越好”
- 2. 样本量计算影响因素有哪些
- 3. 为什么这些因素会直接影响研究结论
- 4. 常见误区:为什么很多研究会“算了也白算”
- 5. 实操上,如何抓住样本量计算影响因素
- 6. 为什么这一步决定研究成败
- 总结Conclusion