引言Introduction

在临床研究和实验设计中,Ⅰ 类错误 α 常被提起,却也最容易被误读。很多人只知道“P<0.05 就显著”,却忽略了它背后真正的风险。** 如果把随机波动误判为真实效应,研究结论就可能偏离事实。** 这正是理解Ⅰ 类错误 α 的关键。
1. Ⅰ 类错误 α 的基本定义
1.1 什么是Ⅰ 类错误 α
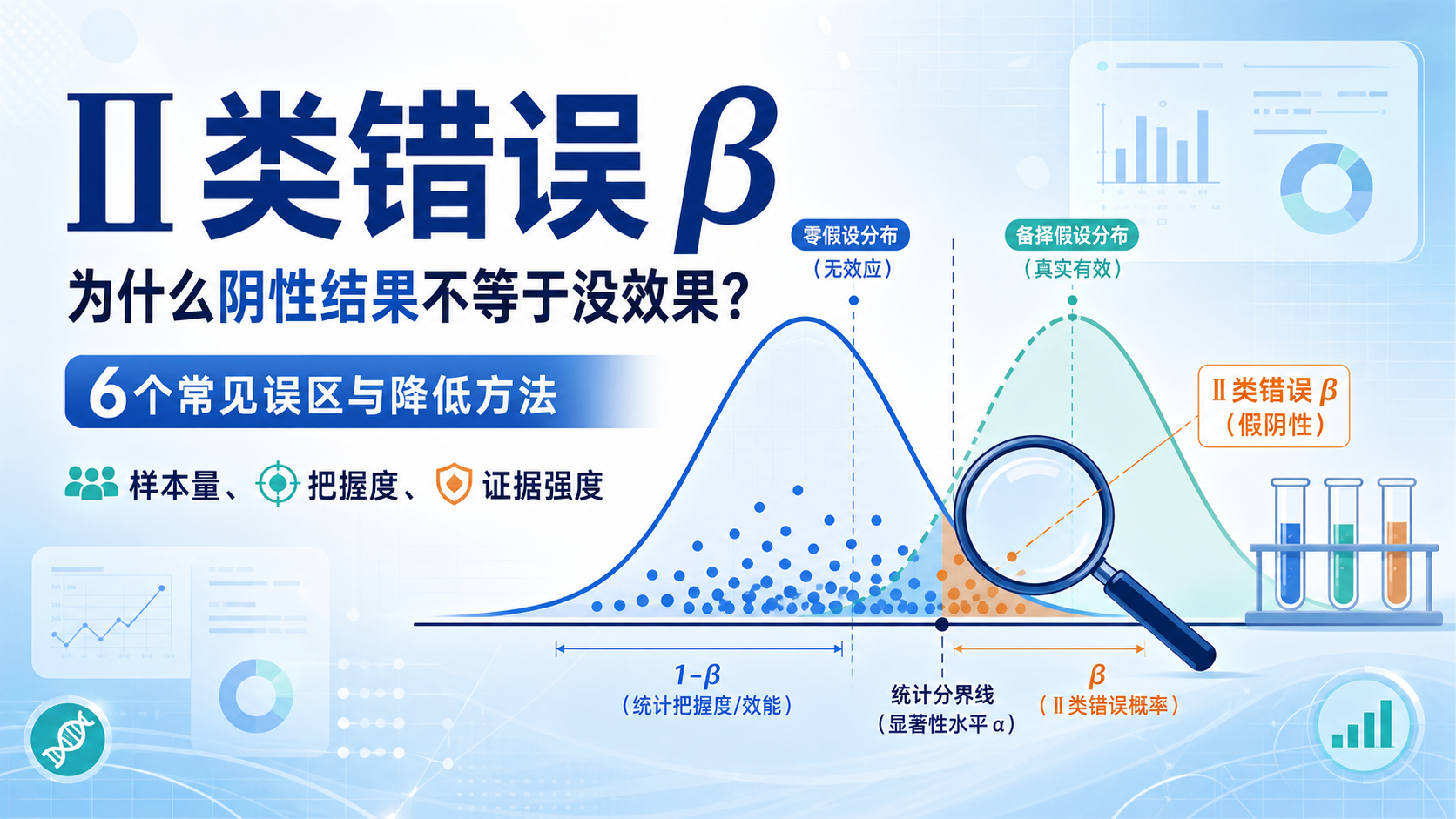
Ⅰ 类错误 α,指在原假设为真时,错误地拒绝原假设。
通俗说,就是“把没有差异,判成了有差异”。在医学研究里,这意味着可能把无效干预误认为有效,把偶然波动误读为真实结果。
这类错误的概率通常用 α 表示。常见阈值是 0.05,表示在原假设真实成立时,最多允许 5% 的概率出现误判。这个设定不是“证明正确”,而是控制假阳性的上限。
1.2 为什么医学生和研究者必须重视
在药物临床试验、队列研究、基础实验中,Ⅰ 类错误 α 直接影响结论可信度。
如果 α 控制不严,文章可能看起来“显著”,但实际上无法重复。对于临床决策来说,这类错误会放大资源浪费,甚至影响患者获益判断。
科研中的“显著”,本质上是概率控制,不是绝对真理。 这句话对论文写作、统计解释和结果讨论都很重要。
2. Ⅰ 类错误 α 的5大机制
2.1 机制一,阈值设定带来的误判风险
α 本质上来自人为设定的显著性水平。
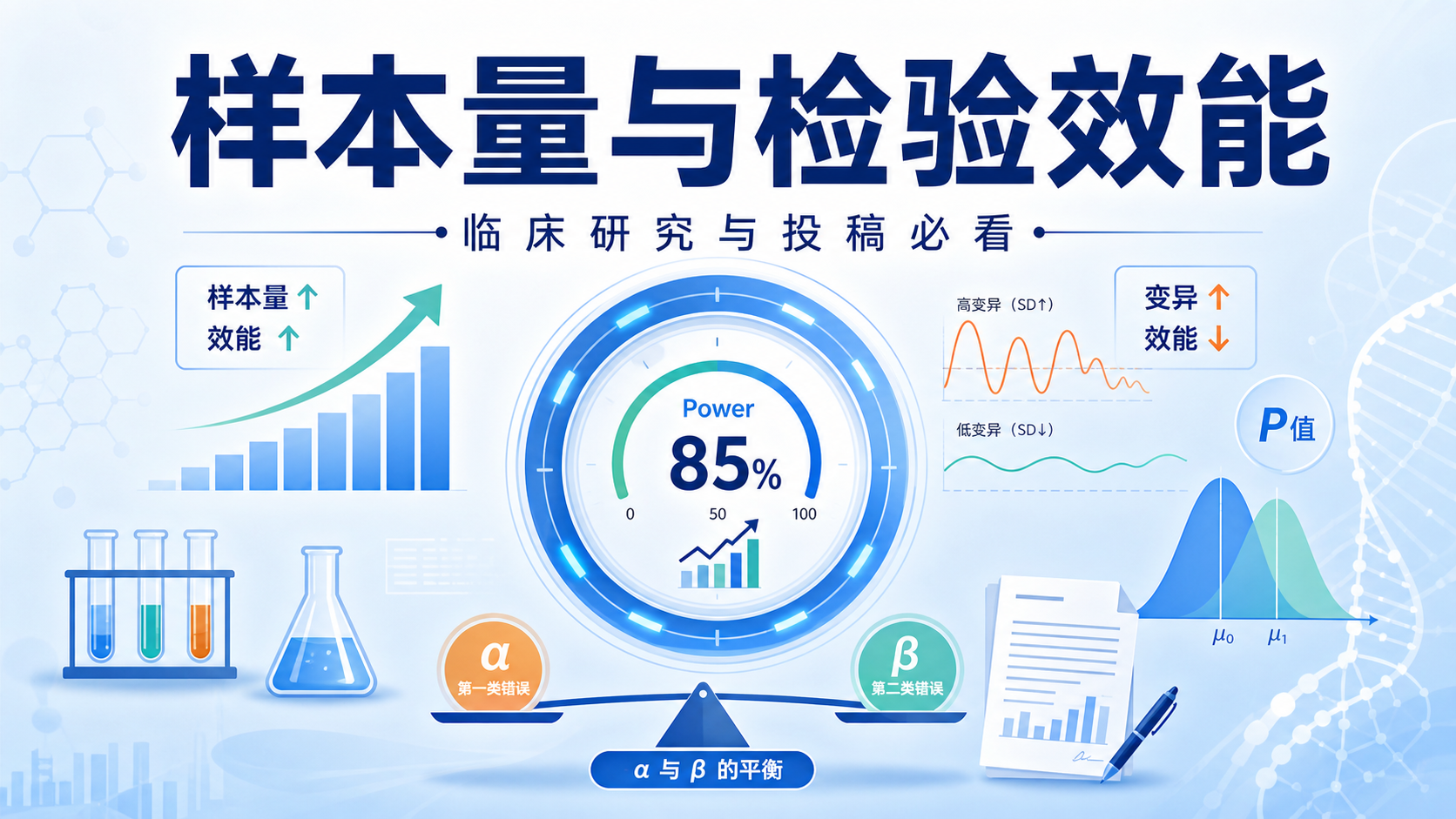
当研究者把阈值设为 0.05 时,就等于接受 5% 的假阳性风险。阈值越宽松,Ⅰ 类错误 α 越容易发生;阈值越严格,误判风险越低,但也可能提高Ⅱ 类错误风险。
这体现了统计学中的平衡问题。
α 不是越小越好,而是要结合研究目的、样本量和临床意义综合设定。
2.2 机制二,重复比较造成累积偏差
在一项研究里,如果反复查看数据,或做大量分组比较,Ⅰ 类错误 α 会被悄然放大。
每一次检验都带来一次误判机会,累计起来,整体假阳性概率明显上升。
这在多终点分析、亚组分析、探索性分析中尤其常见。
例如,只要对多个指标不断筛选,总会出现某些“偶然显著”的结果。如果不进行多重比较校正,Ⅰ 类错误 α 就会失控。
2.3 机制三,多重检验放大假阳性
当一个研究同时检验多个假设时,单次 α 虽然仍是 0.05,但整体错误率会升高。
比如同时分析多个结局、多个时间点、多个基因位点,都会增加“碰巧显著”的概率。
这就是为什么统计分析常需要 Bonferroni 校正、FDR 控制等方法。
多重检验不是简单地“多做几个 P 值”,而是要重新管理Ⅰ 类错误 α 的总体风险。
2.4 机制四,样本量与模型设定影响判断边界
样本量不足时,结果容易受随机波动影响。虽然严格来说这更常导致检验力不足,但在边界样本中,数据波动也会让结果更接近显著阈值,从而增加误判概率。
模型设定不当同样会影响Ⅰ 类错误 α。例如协变量选择不合理、假设前提不满足、分布偏离严重,都可能让检验结果偏离真实情况。
统计模型不是装饰,它决定了 P 值是否可信。
模型错了,结论再“显著”也未必可靠。
2.5 机制五,研究者自由度与选择性报告
研究者在数据清洗、变量筛选、终点选择、统计方法选择中,拥有一定自由度。
如果只报告最显著的结果,而忽略不显著结果,就会产生选择性偏倚。
这种行为会显著抬高Ⅰ 类错误 α 的表观水平。
特别是在探索性研究中,如果没有预先注册方案或明确统计分析计划,结果就更容易被偶然性驱动。看似严谨的显著结果,可能只是“筛出来的巧合”。
3. 如何控制Ⅰ 类错误 α
3.1 预先设定研究方案
在研究开始前明确主要终点、次要终点、统计方法和显著性阈值。
这能减少事后选择性分析的空间,也能降低研究者自由度带来的误判。
预注册、方案锁定、统计分析计划,都是控制Ⅰ 类错误 α 的关键工具。
先定规则,再看数据。 这是高质量研究的基本原则。
3.2 使用多重比较校正
对于多个假设检验,需采用适当的校正方法。
常见方法包括 Bonferroni 校正、Holm 方法、FDR 控制等。不同方法适用于不同研究场景,核心目标都是降低总体假阳性风险。
如果研究是临床试验,应优先明确主次终点。
如果是高通量数据分析,更要关注整体错误率控制。不校正的“显著”,通常不够稳健。
3.3 结合效应量与置信区间解释结果
仅看 P 值是不够的。
还要同时报告效应量、95% 置信区间和临床意义。
这样能帮助读者判断:结果是否不仅“统计显著”,而且“临床有意义”。
Ⅰ 类错误 α 关注的是假阳性概率,而效应量和置信区间能帮助你判断结果的真实价值。
3.4 保持结果透明与可重复
完整报告纳入标准、排除标准、缺失值处理、亚组分析和敏感性分析。
公开方法细节,有助于同行复核,也能提升研究可信度。
可重复性越高,Ⅰ 类错误 α 的实际危害越容易被识别和修正。
对科研人员来说,这比单纯追求一个“P<0.05”更重要。
4. 常见误区与实践建议
4.1 误区一,P<0.05 就等于结论正确
这是最常见的误解。
P 值只是表示在原假设成立时,观察到当前或更极端数据的概率,并不等于假设为真的概率。
显著不等于真实,真实也不一定显著。
这是理解Ⅰ 类错误 α 的核心。
4.2 误区二,α 固定后就万无一失
即使设定了 0.05,也不能自动保证研究正确。
如果研究设计差、数据质量差、模型选择不当,仍然可能出现高假阳性。
所以,控制Ⅰ 类错误 α 不是一个单点动作,而是贯穿设计、实施、分析和报告的全过程。
4.3 实践建议
对医学生和科研人员,建议记住以下3点:
- 先明确原假设和主要终点。
- 多重比较时必须考虑校正。
- 结果解释要结合效应量和临床意义。
如果你正在写论文、做统计分析,或准备科研申报,建议把Ⅰ 类错误 α 作为统计方案中的核心参数,而不是结果出来后才补充说明。
总结Conclusion
Ⅰ 类错误 α 的核心,是控制“把偶然当真实”的风险。它受到阈值设定、重复比较、多重检验、模型选择和研究者自由度等多种机制影响。对于医学生、医生和科研人员来说,理解这些机制,才能更准确地解释 P 值,更稳妥地设计研究。
在实际科研中,严格的方案设计、合理的多重校正、透明的结果报告,才是降低Ⅰ 类错误 α 的关键。 如果你希望在论文写作、统计分析和科研表达中更高效地处理这类问题,可以借助** 解螺旋**的专业科研支持与内容服务,帮助你把复杂统计问题转化为清晰、可发表的研究表达。
- 引言Introduction
- 1. Ⅰ 类错误 α 的基本定义
- 2. Ⅰ 类错误 α 的5大机制
- 3. 如何控制Ⅰ 类错误 α
- 4. 常见误区与实践建议
- 总结Conclusion