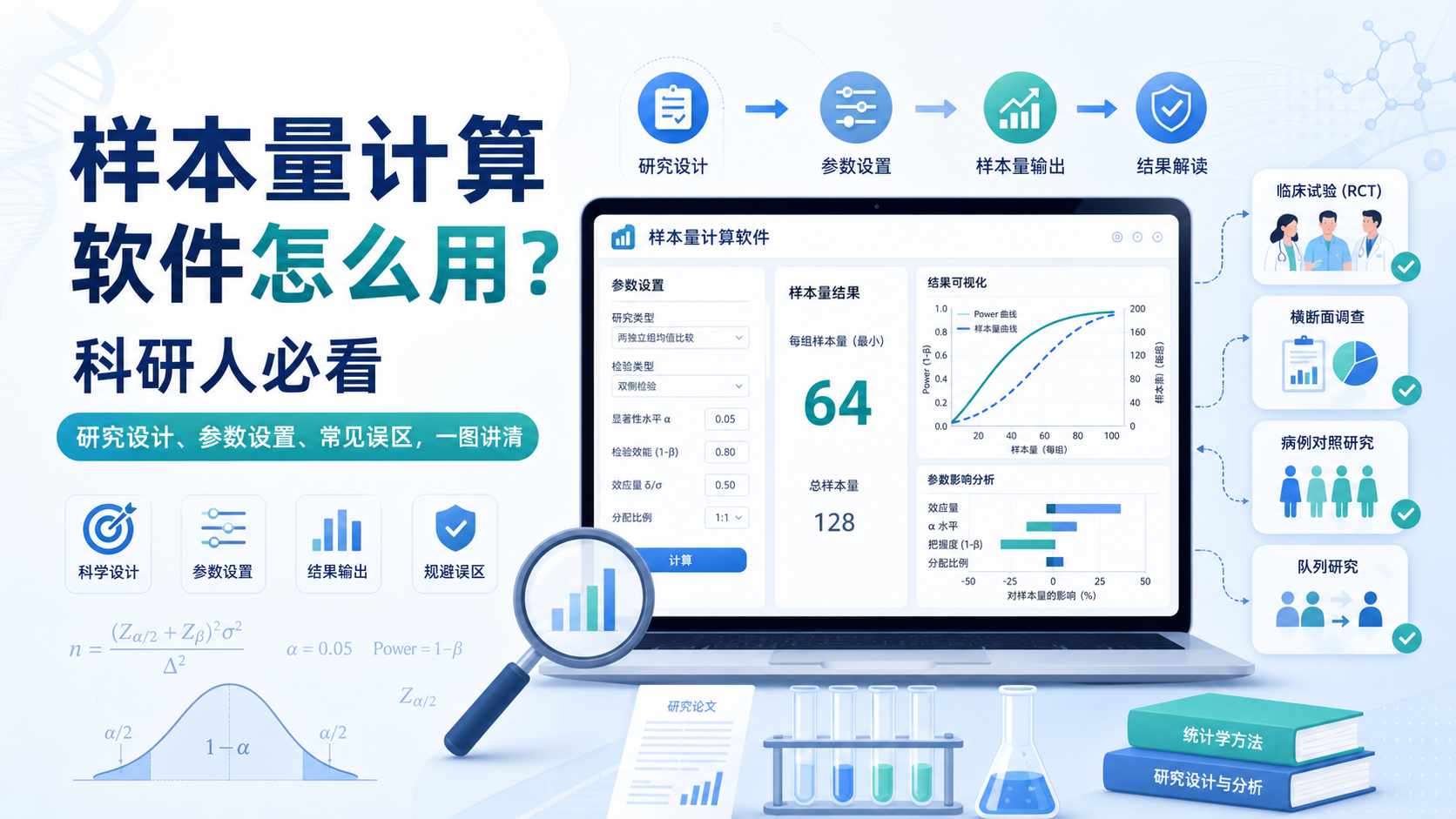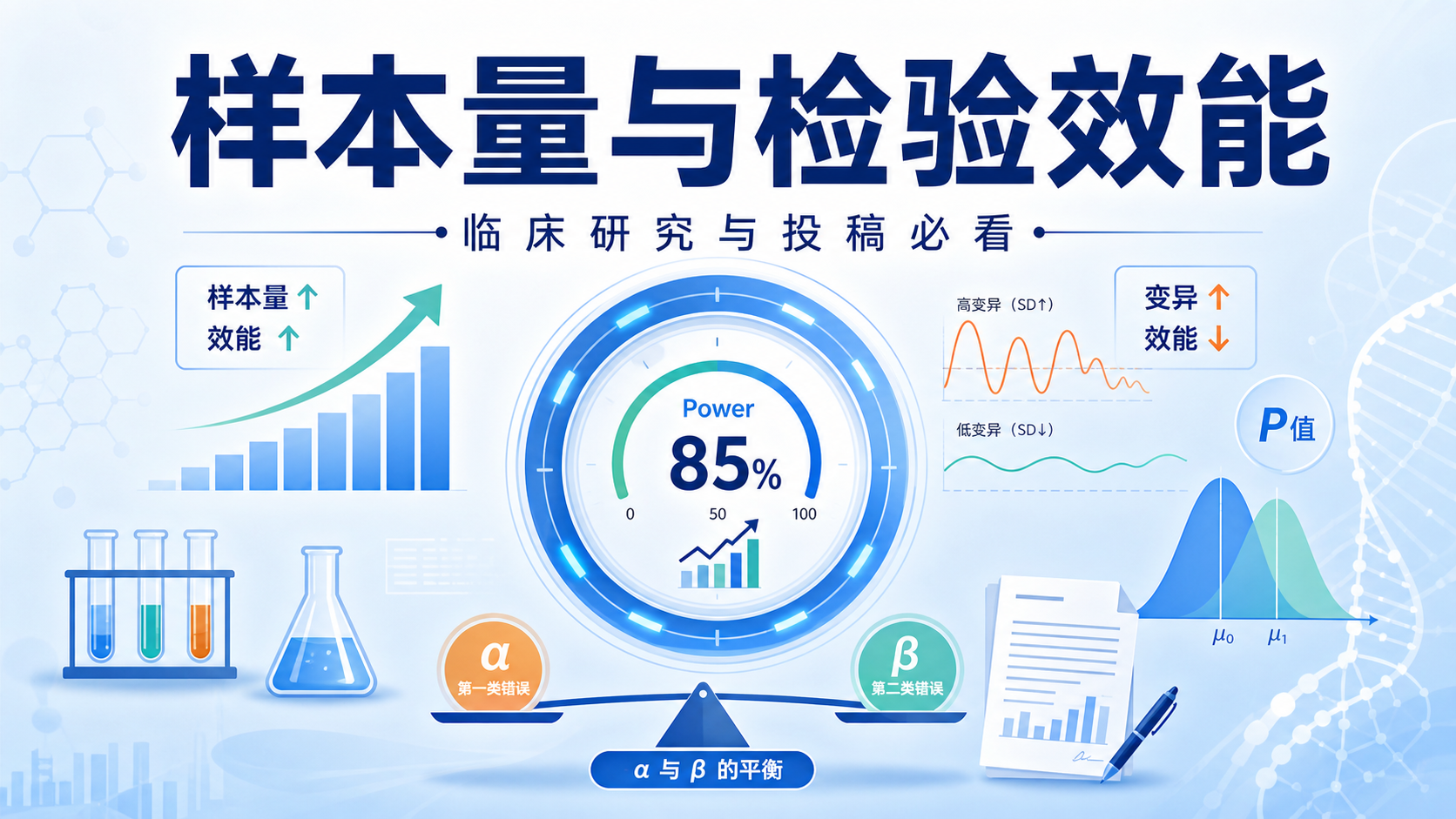
引言Introduction
很多研究者在投稿时都会被问到:样本量与检验效能 是否合理。样本量不足,结果可能不稳定。检验效能过低,真有差异也可能检不出来。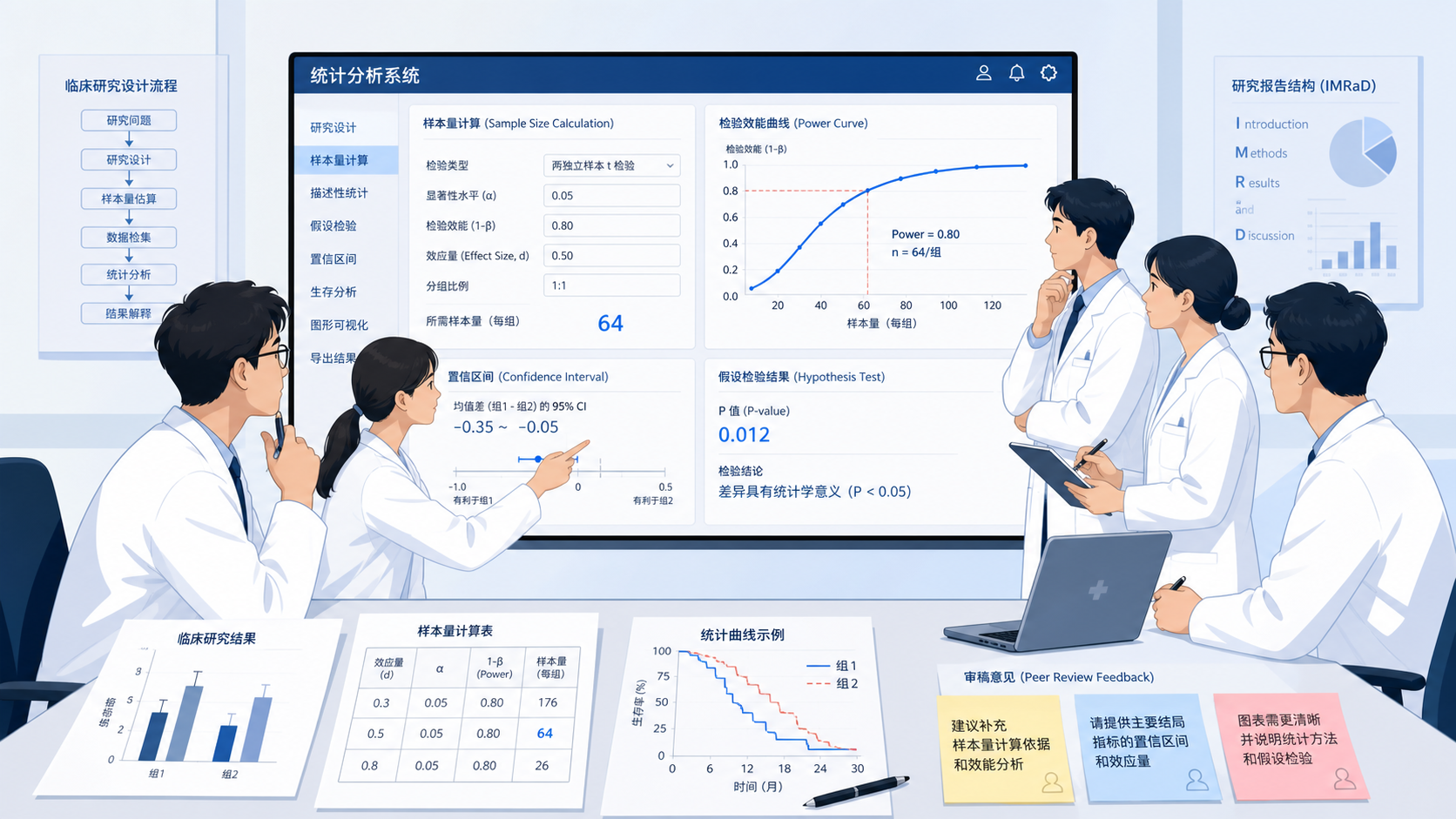
本文用临床研究视角,带你抓住样本量与检验效能 最关键的3个核心点,帮助你在设计、分析和投稿时少走弯路。
1. 先理解样本量与检验效能是什么
1.1 检验效能的定义
检验效能,也叫把握度,指的是当两总体确有差别时,研究能够发现这种差别的能力。 它通常用1-β表示。β是第二类错误概率,也就是“真实有差异,却没检出来”。
这一定义对医学生、医生和科研人员都很重要。因为很多统计问题,本质上不是“有没有做检验”,而是“研究有没有能力发现真实差异”。
1.2 为什么投稿时编辑会关注它
编辑问“你的检验效能是多少”,核心是在问:你的研究有没有足够概率检测到预期效应。
如果效能太低,即使P值不显著,也不能简单等同于“没有差异”。这会直接影响结论可信度。
从临床研究角度看,样本量与检验效能不是两个孤立概念。样本量是设计手段,检验效能是结果能力。 样本量设计得是否合理,决定了研究能否达到预设效能。
2. 影响样本量与检验效能的4个关键因素
2.1 总体差别越大,效能越高
如果研究对象之间的真实差异更大,两个总体分布的重叠就更少,β就更小,检验效能自然更高 。
这也是为什么明确研究问题、选择有效的被试因素和分组标准非常重要。
在实验设计中,研究者要先问自己一个问题:我比较的差异是否具有足够的临床意义?
差异越清楚,研究越容易被检出。
2.2 α与β存在反向关系
检验水准α通常控制在0.05。α越大,越容易拒绝原假设,检验效能会提高,但假阳性风险也会上升。
相反,α过小会让β增大,检验效能下降 。
因此,样本量与检验效能的设计必须在α和β之间平衡。
不能为了追求“显著”而随意放宽α,也不能为了“保守”而把α压得过低。
2.3 标准差越大,效能越低
标准差反映个体变异程度。若组内波动大,数据分布更分散,两组重叠面积变大,检验就更难发现差异。
标准差越大,样本量通常也需要越大。
这在真实世界临床研究中很常见。比如不同中心、不同测量方法、不同人群背景,都可能放大变异,进而影响样本量与检验效能。
2.4 样本量越大,效能越高
样本量增加后,抽样误差会下降,α和β都可能减小,检验效能随之提高 。
但这不意味着越大越好。样本量扩得过大,会带来资源浪费、伦理负担增加,也可能把临床意义很小的差异放大成“统计学显著”。
真正合理的做法,是让样本量与预期效应、标准差、α和β匹配。
3. 提高样本量与检验效能的实用策略
3.1 优先提高效应的可检出性
最有效的办法之一,是在研究设计阶段提高比较的清晰度。
例如:
- 选择临床意义明确的终点。
- 明确纳排标准。
- 减少混杂因素。
- 优化分组方案。
这些做法会让总体差别更清楚,从而提升样本量与检验效能 的匹配效率。
3.2 控制变异,减少标准差
研究中如果能统一测量流程、培训评估者、固定时间窗、采用标准化工具,就能减少无关波动。
标准差降低后,同样的样本量可以获得更高的检验效能。
这也是为什么高质量临床研究往往不仅关注“收多少例”,更关注“怎么收、怎么测、怎么控偏倚”。
3.3 适度增加样本量,但不能盲目扩增
样本量增加确实能提高检验效能,但必须建立在研究问题清晰的前提下。
先考虑差异是否有实际意义,再决定样本量是否增加。
否则,即使统计显著,也可能没有临床价值。
在科研实践中,样本量与检验效能应当与研究类型一起考虑。队列研究、病例对照研究、优效性检验、非劣效性设计,都有不同的参数逻辑,不能套用同一套经验值。
4. 一个临床研究案例,帮你理解检验效能
4.1 前瞻性队列研究中的Power计算
知识库中的案例是日本溃疡性结肠炎患者研究。研究对象共104例,按1:2设计,比较临床缓解期是否坚持服用氨基水杨酸药物与临床复发风险的关系。
研究预估HR≥2,双侧检验α=0.05,随访1年。
结果显示,HR=2.3,P=0.04。进一步用PASS软件在Logrank检验和Hazard Rate条件下计算,Power=0.94 。
这说明本研究的样本量与检验效能 配置较好,检出真实差异的能力较强。
4.2 这个案例能学到什么
这个案例至少说明三点:
- 效能不是抽象概念,而是可以计算的。
- 样本量设计和实际结果可以互相验证。
- HR、α、分组比例和样本量都会影响最终效能。
对于临床科研人员来说,真正重要的不是“有没有做样本量计算”,而是是否根据研究设计合理设置了样本量与检验效能。
5. 投稿和设计时最容易犯的3个错误
5.1 只报样本量,不报效能
有些研究只写纳入多少例,却没有说明预设效能。这样审稿人很难判断研究是否有足够把握检出差异。
5.2 只追求P值,不看临床意义
如果样本量过大,极小差异也可能显著。
统计显著不等于临床显著。
这会导致结论偏离实际医疗决策。
5.3 过度依赖经验估计
样本量与检验效能不能只靠“差不多”判断。
不同研究设计需要不同参数。最好在研究开始前就明确效应量、标准差、α和目标效能,再进行计算。
总结Conclusion
样本量与检验效能,本质上是在回答同一个问题:研究有没有能力发现真实差异。
记住三个核心要点就够了。第一,效应越大,效能越高。第二,α、标准差和样本量都会影响结果。第三,样本量不能盲目增加,必须结合临床意义和研究设计。
如果你正在准备临床研究、论文投稿或方案设计,建议尽早把样本量与检验效能 纳入方法学部分。也可以借助解螺旋 的科研与统计支持,快速完成样本量估计、效能验证和研究方案优化,让设计更规范,投稿更有底气。

- 引言Introduction
- 1. 先理解样本量与检验效能是什么
- 2. 影响样本量与检验效能的4个关键因素
- 3. 提高样本量与检验效能的实用策略
- 4. 一个临床研究案例,帮你理解检验效能
- 5. 投稿和设计时最容易犯的3个错误
- 总结Conclusion