引言Introduction
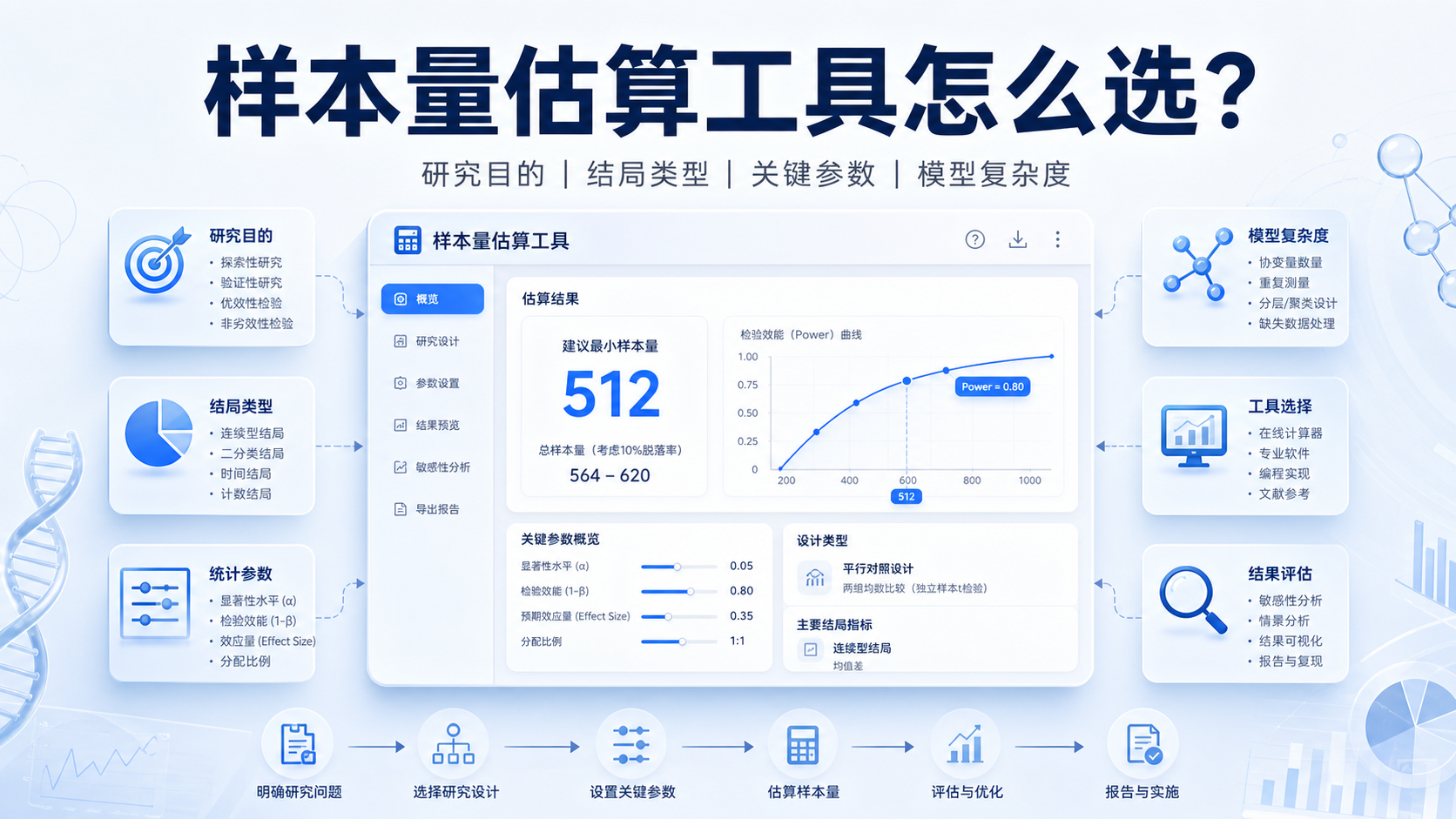
样本量算不准,研究就容易被审稿人质疑。样本量计算步骤 看似只是代入公式,实则先要明确研究设计、结局类型和参数来源,才能得到可解释、可复核的结果。
1. 先定研究设计,再谈样本量
1.1 研究设计决定公式
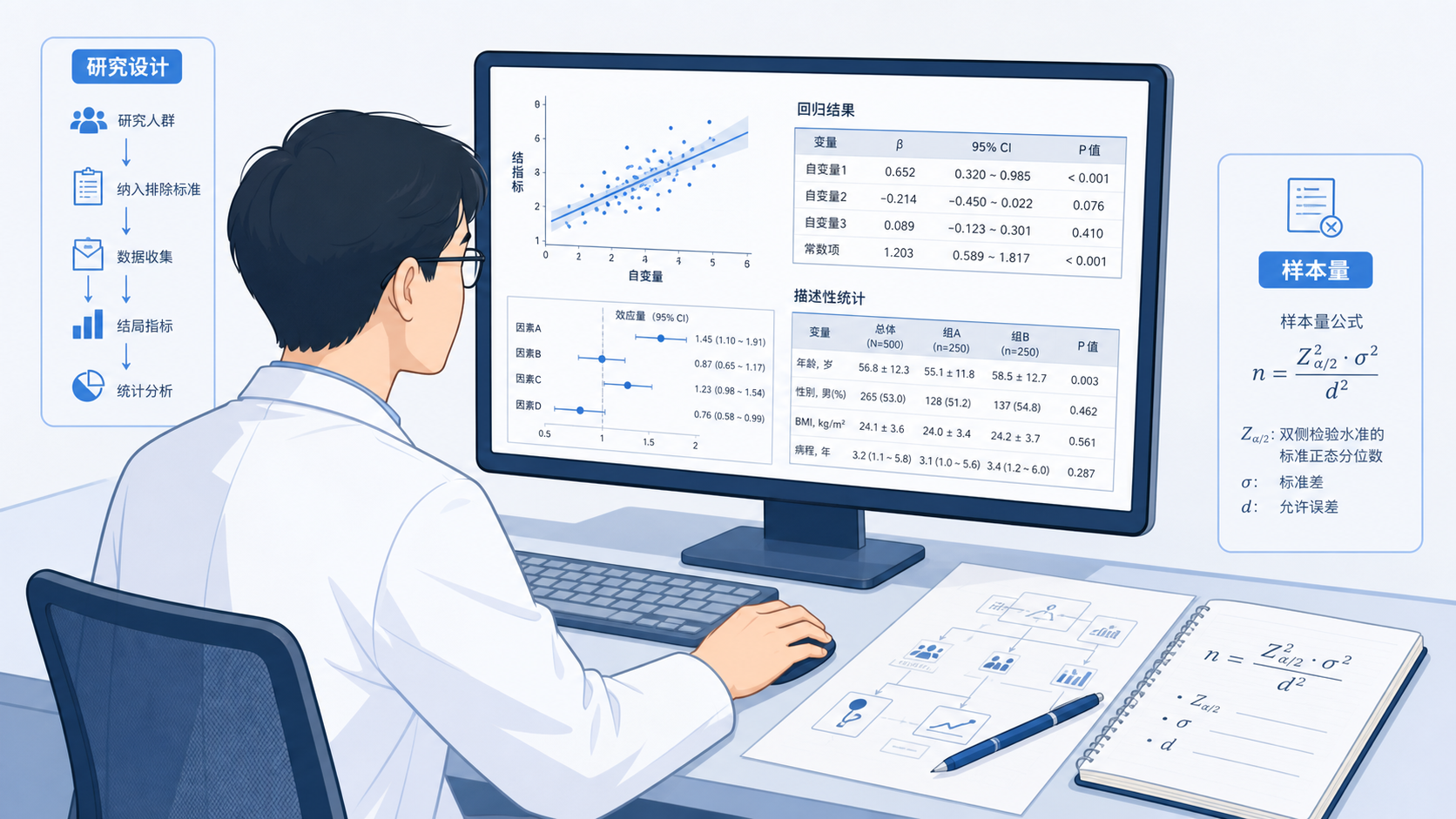
样本量计算步骤的第一步,不是打开软件,而是先明确研究设计。 这是因为不同设计对应不同公式。横断面调查常用于估计患病率或平均值。病例对照研究、队列研究、临床试验和非劣效性试验,计算逻辑都不同。
如果一开始只问“病例研究怎么计算样本量”,问题是不完整的。更准确的做法是先说明研究类型,再查对应章节或公式。解螺旋课程也反复强调这一点。研究设计不清,后续样本量就没有依据。
1.2 明确你要估计什么
横断面调查常见目标有两类。
- 估计某人群患病率。
- 估计某指标的总体均数。
例如,乙肝表面抗原携带率、糖尿病患病率、青少年平均身高,都属于这一类。研究目标不同,样本量计算步骤就不同。 如果你是比较两组率,参数就会变成两组差异、效应量和把握度。
1.3 设计决定可行性
临床研究中常见一个现实问题。研究者手里只有100例病例,却担心审稿人要求200例。此时不能只用“医院一年就这么多例”来解释。你需要先用研究设计推导出理论样本量,再讨论现实可得样本是否足够。
如果理论样本量低于现有样本,结果通常更稳。若理论样本量更高,就要补充病例或说明研究边界。
2. 参数要有来源,不能凭感觉
2.1 先确定核心参数
样本量计算步骤的第二个关键点,是把参数说清楚。 最常见的参数包括检验水准α、允许误差、预期率或标准差、把握度。不同研究还会加入效应量、失访率、分组比例等。
对于总体率估计,常见思路是:
- 预期患病率来自文献或专家经验。
- 允许误差决定精度。
- 检验水准通常按0.05设定。
对于总体均数估计,重点往往不是均数本身,而是标准差。标准差越大,所需样本量通常越大。
2.2 参数要有文献或经验支持
课程中提到,某市区乙肝表面抗原携带率若预计为10%,且希望误差不超过1%,根据公式需要约3458例。这里的10%不是拍脑袋,而应来自文献、地区调查或专家经验。样本量计算步骤中,参数来源必须可追溯。
这也是论文写作中经常被忽视的一点。写研究设计书时,最好同时记录:
- 研究设计类型。
- 使用的公式。
- 参数来源。
- 软件名称与版本。
这样后续答辩、投稿或修改时都更容易解释。
2.3 把握度和误差的关系
样本量不是越大越好,也不是越小越省事。它本质上是在控制误差。
- α越小,样本量越大。
- 把握度越高,样本量越大。
- 容许误差越小,样本量越大。
- 变异度越大,样本量越大。
这四个方向几乎决定了大多数样本量计算步骤的基本逻辑。 如果你把精度要求设得很高,样本量自然会上升。这不是软件的问题,而是统计学要求。
3. 用公式或软件复核,别只看结果
3.1 先手算,再用软件验证
样本量计算步骤的第三个关键点,是复核。 课程中使用PASS软件演示了总体率和总体均数的计算。软件会让你输入研究设计、α值、预期率或标准差,再给出结果。软件的优势是方便,但前提仍然是参数正确。
对于简单的横断面调查,其实很多公式可以手算。比如总体率估计和总体均数估计,都有经典公式。手算的价值在于帮助你理解结果从哪里来。 软件的价值在于提高效率并减少录入错误。
3.2 结果要能写进研究设计书
不是算出一个数字就结束了。样本量计算步骤最终要落到研究设计书或论文方法学部分。 至少要写清楚:
- 研究类型。
- 结局指标。
- 估计值或效应量。
- α值和把握度。
- 允许误差。
- 所用公式或软件。
这样审稿人看到后,能判断你的样本量是否合理。若结果与预期不同,也能追溯原因。比如总体率调查得到15%,不一定说明估计错误,也可能是抽样误差或真实人群差异。
3.3 常见误区要提前避开
很多人把样本量计算简化成“套公式”。这会出问题。常见误区包括:
- 不说明研究设计。
- 参数没有文献支持。
- 只报结果,不报过程。
- 把横断面资料硬改成病例对照,却不重新计算。
- 忽略抽样方式差异。
真正规范的样本量计算步骤,必须和研究问题、抽样方式、分析方法一致。 如果是分层抽样、整群抽样或多阶段抽样,公式会更复杂,不能直接沿用简单随机抽样的结果。
4. 论文写作中如何表达样本量计算
4.1 方法学部分怎么写
建议用简洁、可复核的方式描述。比如:
- 本研究为横断面调查。
- 主要结局为某病患病率。
- 预期患病率来源于既往文献。
- 按α=0.05、允许误差为1%计算样本量。
- 最终样本量为XXX例。
这样写的核心,是让读者一眼看懂你的样本量计算步骤。
4.2 临床研究者尤其要注意
临床资料研究常遇到样本量不足的问题。此时最重要的不是回避,而是解释。你可以说明病例来源、纳入时间、实际可得样本,以及为何该样本仍具有分析价值。若研究目标是估计患病率或均数,样本量太少会明显降低稳定性。
这类场景下,先做对样本量计算步骤,再决定是否补充样本,往往比事后补救更有效。
4.3 工具可以帮你,但不能替你决定
PASS等软件可以完成常见计算。它们适合做验证和敏感性分析。比如,你可以把预计患病率从5%改到10%,观察样本量变化。这样能帮助你理解参数对结果的影响。
但要记住,软件不会替你判断研究设计是否合理。 这一步只能由研究者自己完成。
总结Conclusion
样本量计算步骤的核心,只有三点。 第一,先明确研究设计。第二,确保参数有依据。第三,用公式或软件复核,并写清楚方法。只要这三步扎实,样本量就不只是一个数字,而是可解释、可投稿、可答辩的证据链。
对医学生、医生和科研人员来说,最实用的做法是先把研究问题说清,再按设计选择公式,最后用工具验证。若你希望更高效地完成研究设计、样本量估算和论文写作,可以关注解螺旋 的系统化课程与工具支持,少走弯路。

- 引言Introduction
- 1. 先定研究设计,再谈样本量
- 2. 参数要有来源,不能凭感觉
- 3. 用公式或软件复核,别只看结果
- 4. 论文写作中如何表达样本量计算
- 总结Conclusion