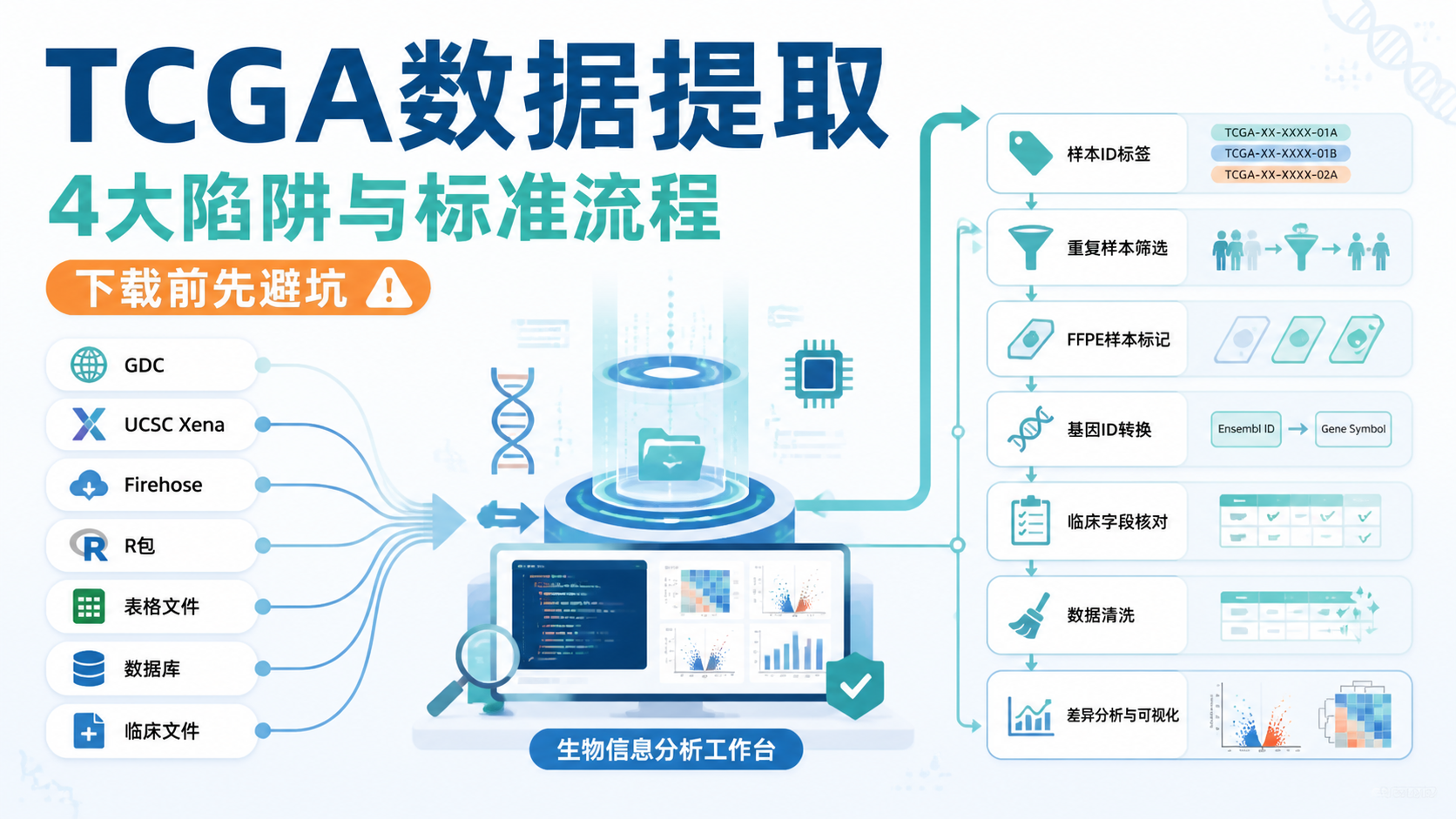
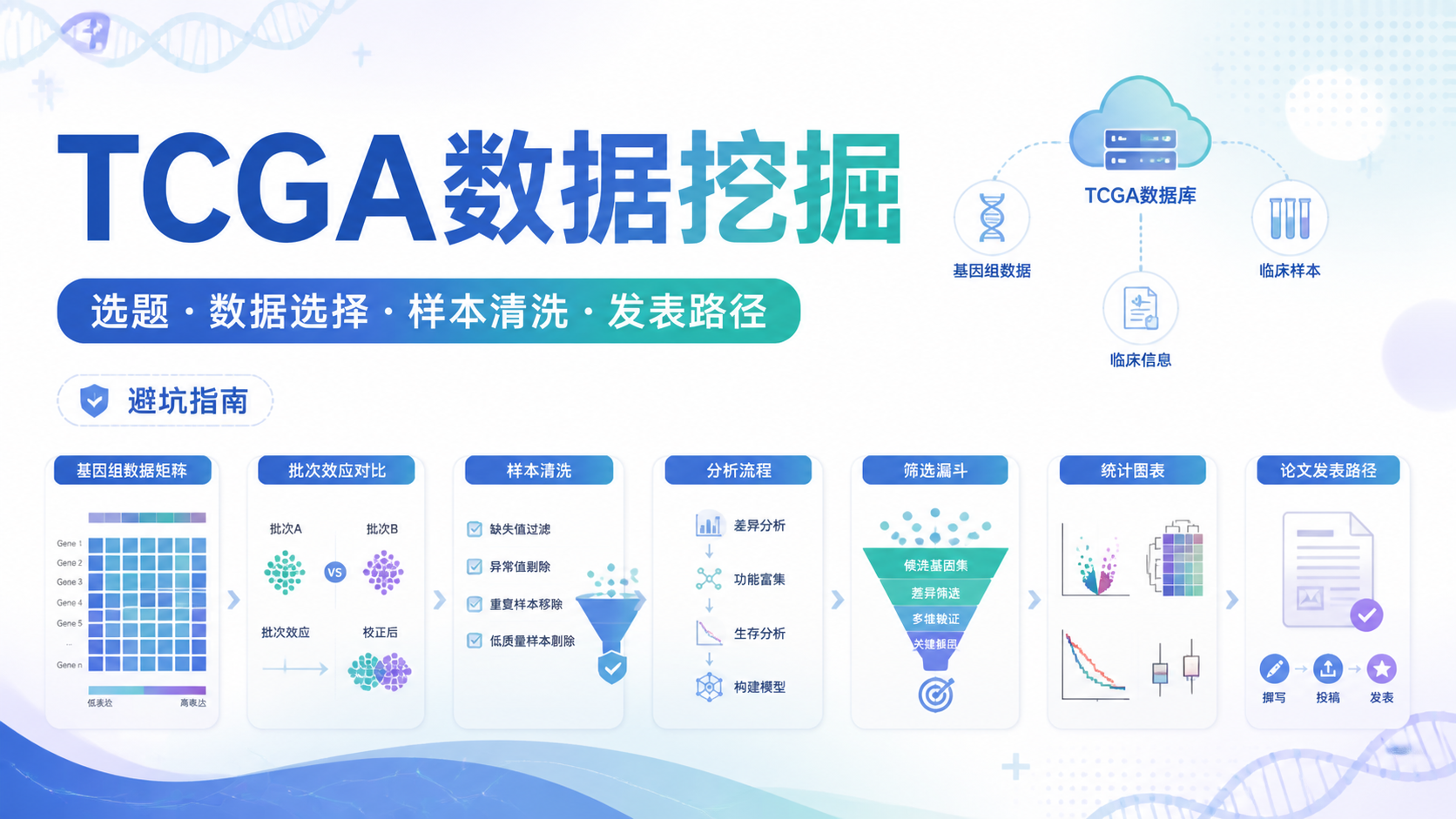
引言Introduction
TCGA数据筛选做不好,后面的差异分析、分组比较和批次校正都会被放大误差。很多问题不是模型不行,而是样本注释、barcode、基因过滤没处理对。想让TCGA分析更稳,第一步就是把筛选规则做对。 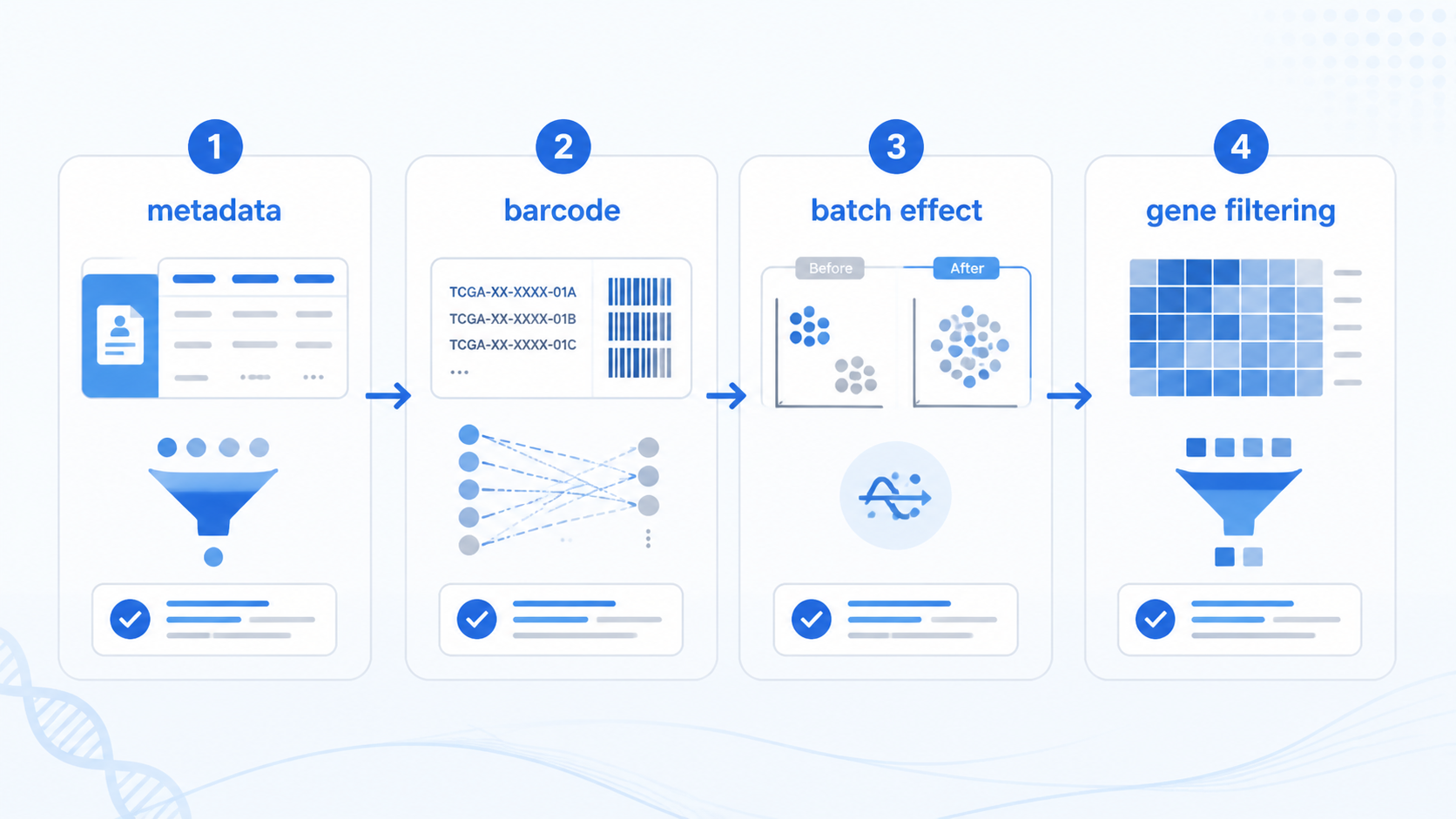
1. 先从Metadata入手,别直接下载就分析
1.1 先建立样本与文件名的对应关系
TCGA数据筛选的第一步,不是看表达矩阵,而是看Metadata。Metadata里通常包含样本名字、样本ID、组织类型等信息。课程中强调,先下载JSON格式文件,再用R里的 jsonlite 包读取,能把文件名和sample ID准确对应起来。
这一步的核心价值,是避免“拿错样本还不自知”。 例如同一项目里,原始文件名和样本ID可能并不是一一直观看出来的。先整理对应关系,后续筛选才有依据。
1.2 manifest文件和注释表要一起用
做TCGA数据筛选时,单看表达矩阵远远不够。manifest文件能帮助整理样本与文件名的关系,annotation表格则能提示哪些样本应该保留,哪些样本需要剔除。
常见做法是:
- 下载Metadata JSON。
- 提取样本ID、文件名、组织来源。
- 用manifest补齐文件对应关系。
- 再进入后续筛选。
如果样本来源不清楚,后续所有统计都会受影响。
2. 读懂TCGA barcode,才能筛对样本
2.1 第14、15位字符最关键
TCGA barcode 不是简单编号,而是包含项目名称、样本来源代码、患者编码等信息。课程里明确提到,样本组织学类型可从第14、15字符提取。比如,01代表原发肿瘤,11代表正常组织 。
这意味着,做TCGA数据筛选时,你可以直接依据barcode快速区分肿瘤和正常样本。对于差异分析,这一步尤其重要。
2.2 analyte、plate、center也会影响筛选
barcode 里还包含 analyte、plate 和 center 等信息。analyte 可提示样本类型,例如 D 代表DNA,R 代表RNA 。plate 和 center 则与测序板和数据分析中心有关。
同一个患者出现多个样本时,不代表都应该保留。 还要结合重复样本规则和批次信息判断。否则很容易把技术重复当成生物重复,造成偏差。
3. 处理重复样本,避免一人多样本干扰结果
3.1 先看重复样本定义
TCGA中常见问题是一个病例存在多个样本或多个测序版本。课程提到,TCGA对重复样本有明确处理标准,常见筛选依据包括 analyte replicate filter 和 sort replicate filter。
这类规则的意义在于:先按样本类型筛,再按排序规则保留最合适的一条记录。 这比人工凭感觉删样本更可靠。
3.2 样本筛选要结合注释表核查
在实际筛选中,建议优先检查 annotation 表格,确认样本是否存在 FFPE、重复测序、异常来源或不适合纳入分析的情况。
可以按以下顺序做:
- 先确认样本类型。
- 再确认是否重复。
- 最后检查是否存在异常技术因素。
TCGA数据筛选的关键,不是“删得多”,而是“删得准”。
4. TCGA和GTEx合并前,先解决批次效应问题
4.1 推荐统一使用重新计算过的数据
如果要做癌旁或正常组织比较,经常会遇到 TCGA 和 GTEx 合并的问题。课程建议,优先下载 UCSC 网站上重新计算好的数据,这样技术差异会更小,合并时更稳。
这是非常实用的策略。因为不同来源的数据,测序流程、处理流程、注释版本都可能不同。不先统一处理,后面做差异分析时,批次效应可能比生物差异还大。
4.2 批次效应要提前识别
课程中提到,可结合 phenotypes 文件中的 batch number、TSS 编码和测序板批次信息识别批次效应。常用工具包括 RUVSeq、SVA 等 R 包。
实际操作中,建议:
- 先看样本来源分布。
- 再看批次是否和分组高度重合。
- 若重合明显,先处理批次,再做差异分析。
这是TCGA数据筛选里最容易被低估的一步。
5. 基因筛选要做,但标准不必过度复杂
5.1 先去掉不表达或低表达基因
RNA-seq分析中,基因过滤几乎是必做步骤。课程给出的原则很清楚:去掉表达量为0的基因,或者保留在至少一半样本中表达量大于0的基因,也可以保留中位数大于0的基因。
这些方法的目的都一致:减少噪音,提高差异分析的敏感性和准确度。
5.2 平均值过滤要谨慎
平均值过滤看起来简单,但不一定最稳。因为少数极高表达值可能拉高均值,掩盖大部分样本中的低表达事实。相比之下,中位数和“在多少样本中表达”这类标准,更适合初步筛选。
常见可执行标准有:
- 去除全部为0的基因。
- 保留至少50%样本中表达量大于0的基因。
- 保留中位数大于0的基因。
具体标准可以灵活,但原则必须一致。
6. ID转换不要神化,但版本要统一
6.1 先看基因组版本差异
TCGA数据筛选常涉及ID转换。课程提到,GRCh38与早期版本存在差异,基因注释也会更新。常见做法是下载 GTF 或 GFF 文件,按注释信息完成转换。
这里最重要的不是追求“绝对完美”,而是确保同一分析流程前后一致。版本混用会让基因ID对应关系变得混乱。
6.2 V22和V34的差异通常不是最致命问题
课程中还指出,TCGA与GTEx数据存在版本差异,例如 V23 与最新 V34。对最终分析结果可能有影响,但通常不是决定性问题。真正决定分析质量的,往往还是样本筛选、批次控制和过滤逻辑。
所以,ID转换要做,但不要本末倒置。先保证样本和批次正确,再处理版本统一。
7. 用“筛选三步法”提高TCGA数据筛选效率
7.1 先筛样本,再筛分组,最后筛基因
结合课程内容,TCGA数据筛选可以归纳成三步:
- 样本筛选。 看Metadata、barcode、注释表,排除异常样本。
- 分组筛选。 区分原发肿瘤、正常组织、重复样本,以及TCGA与GTEx来源差异。
- 基因筛选。 去掉低表达、无表达、噪音过高的基因。
这个顺序很重要。先样本,后分组,再基因。 反过来做,容易把错误放大到下游结果里。
7.2 让筛选规则服务于研究问题
不同研究问题,筛选标准不完全一样。做差异表达分析时,样本纯度和分组准确性优先。做队列分层时,批次信息和来源一致性更重要。做预后模型时,低表达过滤和重复样本去重更关键。
所以,TCGA数据筛选没有唯一答案,但有共同原则:
- 先保证样本真实。
- 再保证分组清晰。
- 最后保证基因质量。
这也是为什么规范的筛选流程,比单纯拿到大数据更重要。
总结Conclusion
TCGA数据筛选的核心,不是复杂技巧,而是流程严谨。先从Metadata建立样本对应关系,再读懂barcode,处理重复样本,识别批次效应,完成基因过滤与ID统一,才能让后续分析更可靠。真正高质量的TCGA分析,始于高质量筛选。
如果你想少走弯路,建议直接参考解螺旋的标准化生信学习路径,把TCGA数据筛选、预处理和差异分析串成完整流程。这样不仅能提高分析效率,也更容易产出可复现、可发表的结果。
- 引言Introduction
- 1. 先从Metadata入手,别直接下载就分析
- 2. 读懂TCGA barcode,才能筛对样本
- 3. 处理重复样本,避免一人多样本干扰结果
- 4. TCGA和GTEx合并前,先解决批次效应问题
- 5. 基因筛选要做,但标准不必过度复杂
- 6. ID转换不要神化,但版本要统一
- 7. 用“筛选三步法”提高TCGA数据筛选效率
- 总结Conclusion