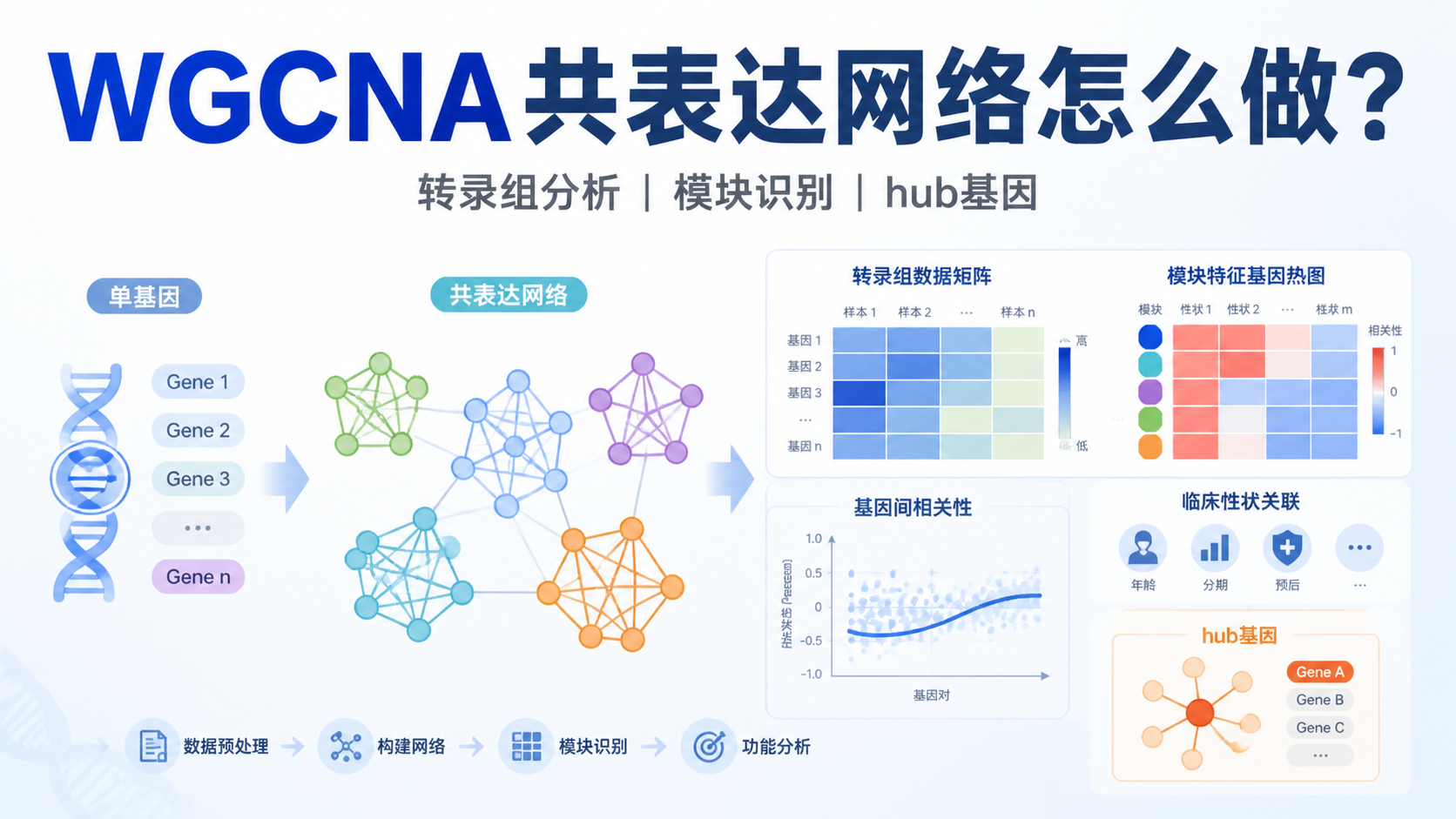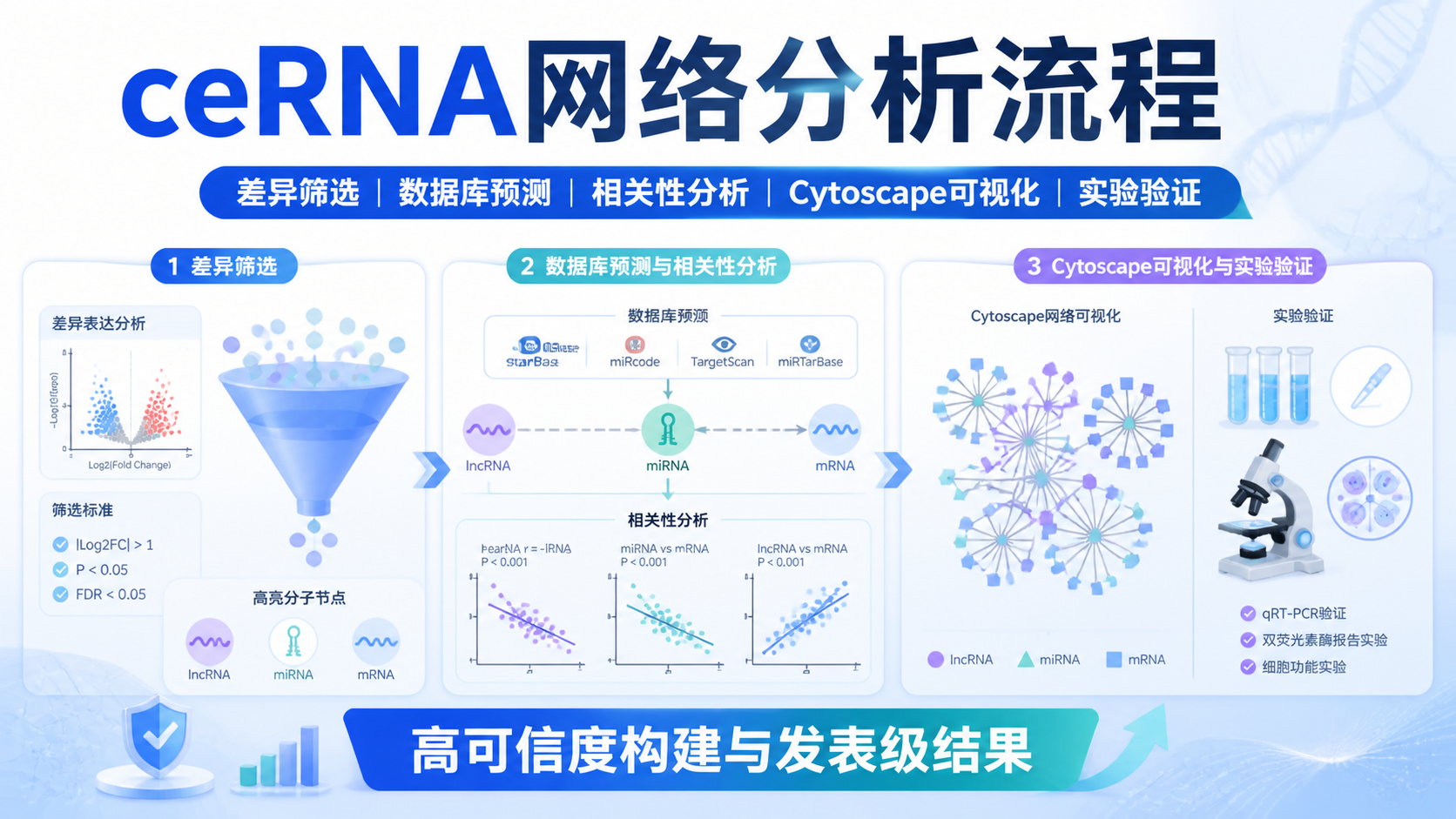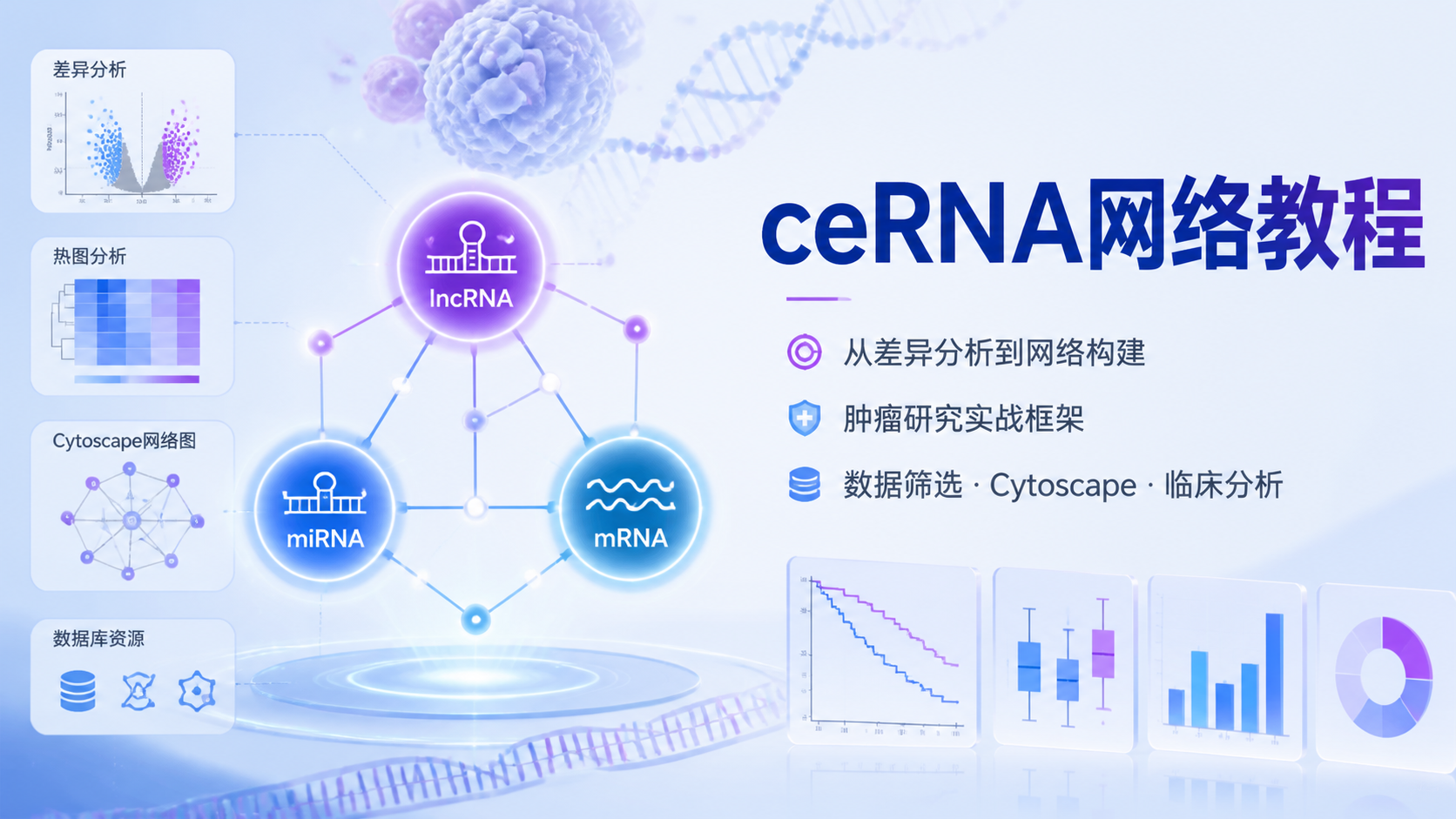
引言Introduction
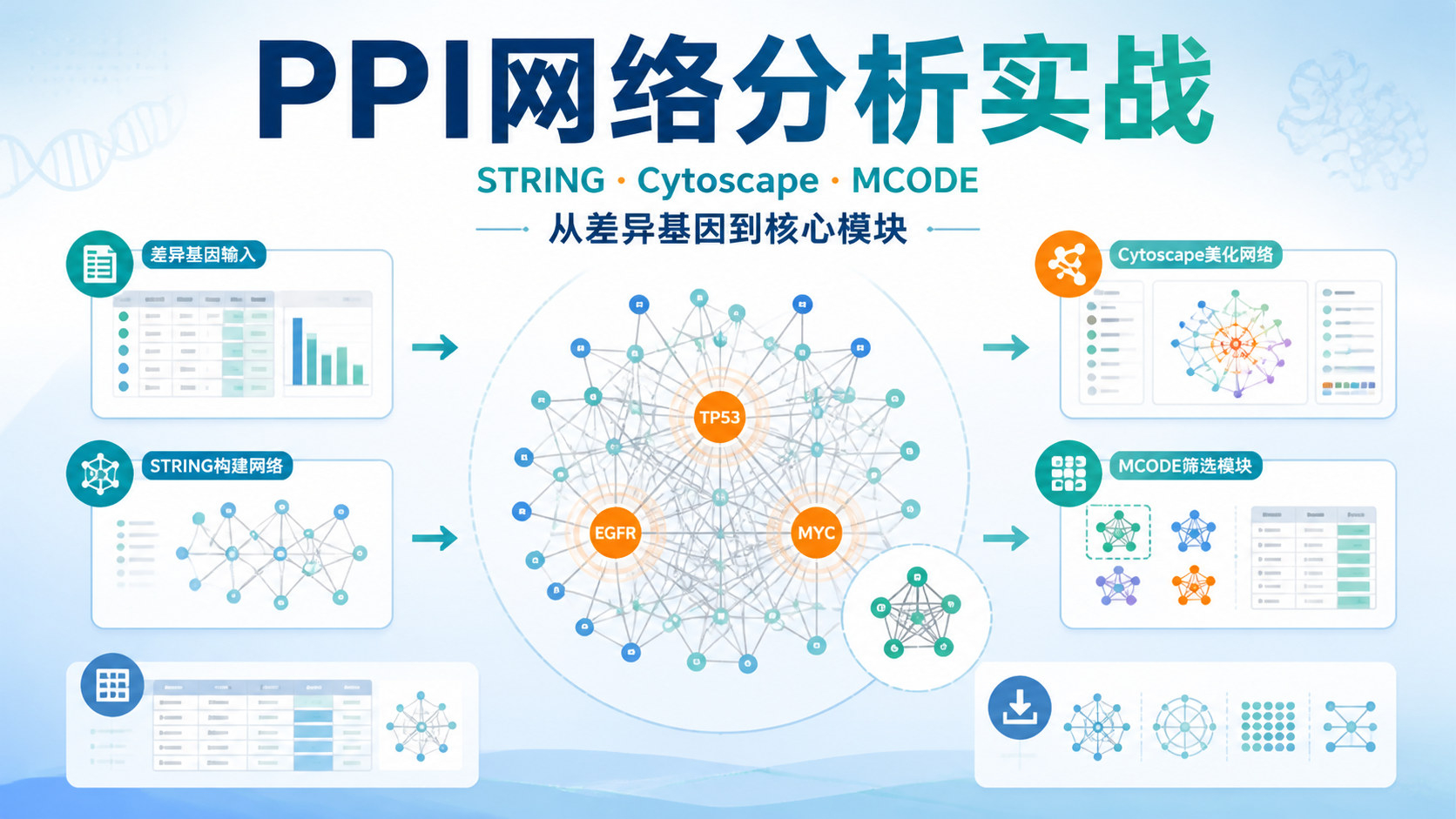
PPI网络构建步骤看似简单,真正难点在于数据整理、参数选择和图形呈现。很多初学者能跑出网络,却做不出可发表的高质量图。本文用STRING和Cytoscape的标准流程,拆解PPI网络构建步骤,帮助医学生、医生和科研人员少走弯路。
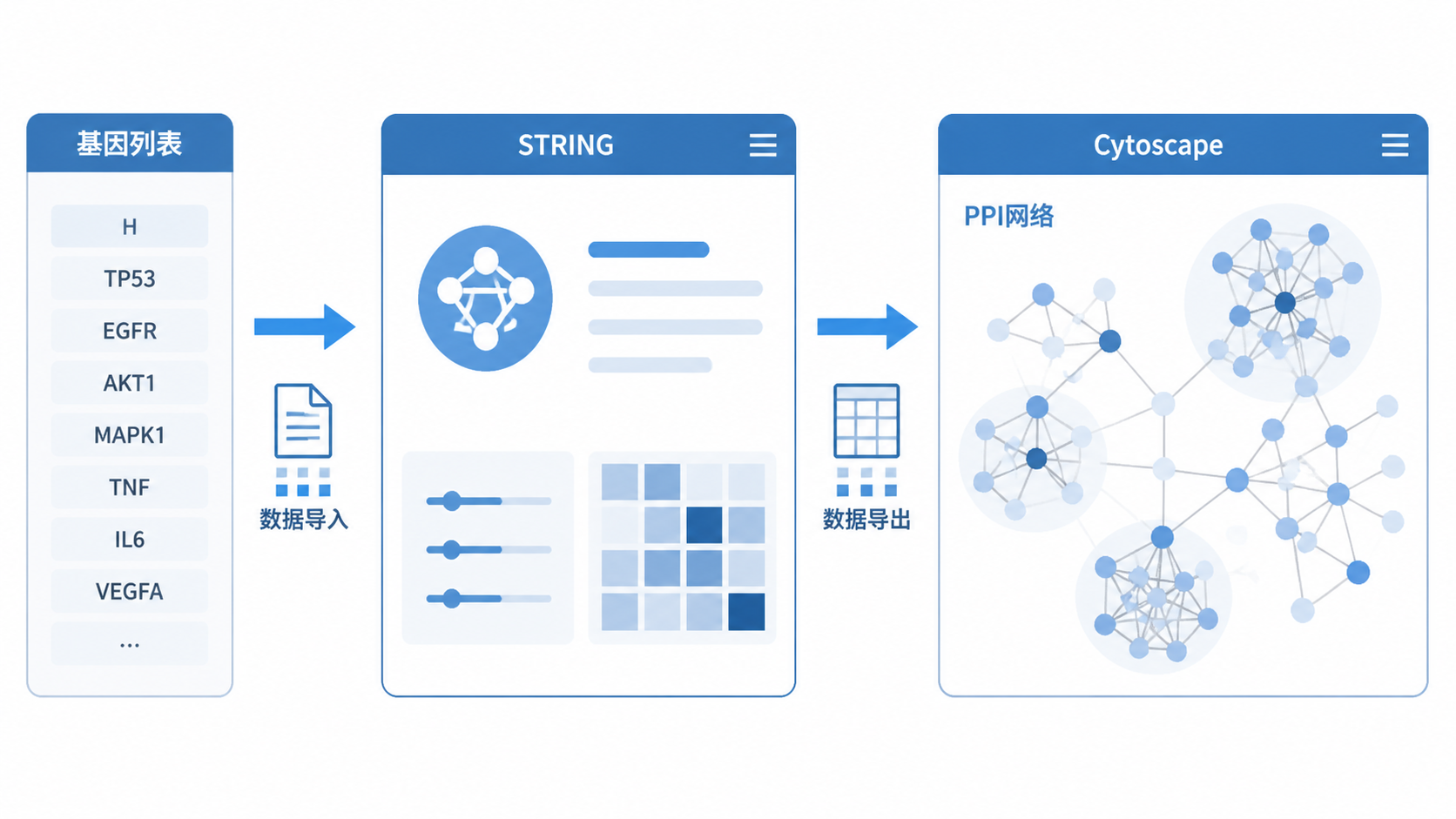
1. 明确PPI网络的输入数据
1.1 先准备差异基因列表
PPI网络构建步骤的起点,不是直接开软件,而是先整理输入数据。常见做法是从差异分析或整合分析结果中,筛选出显著基因,再提取SYMBOL列用于后续分析。
核心原则是,输入必须干净、统一、可追溯。
如果基因命名混乱,后面的STRING检索和Cytoscape导入都会出问题。
在实操中,建议先确认三点:
- 基因符号是否标准化。
- 是否已经完成显著性筛选。
- 是否保留了原始结果文件,方便回溯。
1.2 网络图至少要有两列
在Cytoscape里,任何复杂网络都可以看成节点和边的组合。
因此,基础数据至少要包含两列。
- 第一列是源节点,常写作node1。
- 第二列是靶节点,常写作node2。
同一行代表两个蛋白之间存在互作关系。
如果还要叠加表达量、上调下调、Combined Score等信息,可以额外准备属性表。
1.3 先想清楚你要展示什么
PPI网络构建步骤并不只是“画图”。
你需要先明确目的。
常见目标有三类:
- 找核心基因。
- 找关键模块。
- 给文章中的机制部分提供支撑。
如果目标是筛Hub基因,后面就要重点考虑Degree等网络指标。
如果目标是模块筛选,就要提前准备MCODE分析思路。
2. 用STRING快速构建PPI网络
2.1 STRING是最常用的起点
在现有流程中,STRING是构建PPI网络最常用、也最方便的数据库之一。
它适合先做初筛,再导出结果给Cytoscape二次美化。
标准做法是:
- 打开STRING网站。
- 进入Multiple proteins分析页面。
- 粘贴基因列表。
- 物种选择人。
- 提交后生成互作网络。
这一步的关键不是“跑出来”,而是“跑得准”。
2.2 参数设置决定网络质量
在PPI网络构建步骤中,参数设置很重要。
知识库中的常用做法是设置 confidence > 0.4。
这个阈值的意义在于:
- 太低,网络会过于松散。
- 太高,可能丢失部分潜在互作。
0.4通常可作为基础分析的起点。
后续是否提高阈值,要根据研究问题和图形稠密度决定。
2.3 处理孤立节点,让图更干净
STRING默认生成的网络中,常会出现一些游离点。
这些点不一定有助于文章表达,反而会让图面变乱。
可根据需要:
- 隐藏未连接节点。
- 去除离散点。
- 再更新网络视图。
这样做的目的,是提升可读性,而不是改变核心生物学结论。
2.4 导出高清图和文本结果
完成基础网络后,建议导出两类文件。
- 高清位图,用于文章展示。
- text output表格,用于导入Cytoscape。
这一步很重要。
因为STRING负责“快速构建”,Cytoscape负责“深度优化”。
两者配合,通常更适合发表级图表。
3. 用Cytoscape完成网络美化与核心基因筛选
3.1 导入STRING结果文件
Cytoscape是PPI网络构建步骤里最重要的美化和分析工具。
它能把STRING导出的互作表格重新构建成更适合论文的网络图。
操作顺序很清晰:
- 打开Cytoscape。
- 选择File。
- 点击Import。
- 选择Table from File或Network from File。
- 导入STRING下载的tsv文件。
导入时要确认:
- node1和node2对应正确。
- 节点颜色设置无误。
- 网络结构已经完整生成。
3.2 用Style统一视觉规则
初步网络生成后,不要急着导出。
先进入Style进行美化。
常见调整包括:
- 节点大小。
- 节点颜色。
- 连线粗细。
- 标签显示方式。
网络图的目标不是花哨,而是让重点一眼可见。
如果表达数据更重要,可以让节点颜色映射表达量。
如果互作强度更重要,可以让线条粗细映射Combined Score。
3.3 用NetworkAnalyzer读取网络指标
在Cytoscape中,可通过NetworkAnalyzer进行网络分析。
知识库中强调,常用的可视化逻辑包括:
- Degree越大,节点越大、越亮。
- Degree越小,节点越小、越暗。
- Combined_Score越大,连线越粗。
- Combined_Score越小,连线越细。
这类规则能把“统计意义”转化为“视觉重点”。
对读者来说,核心基因会更直观。
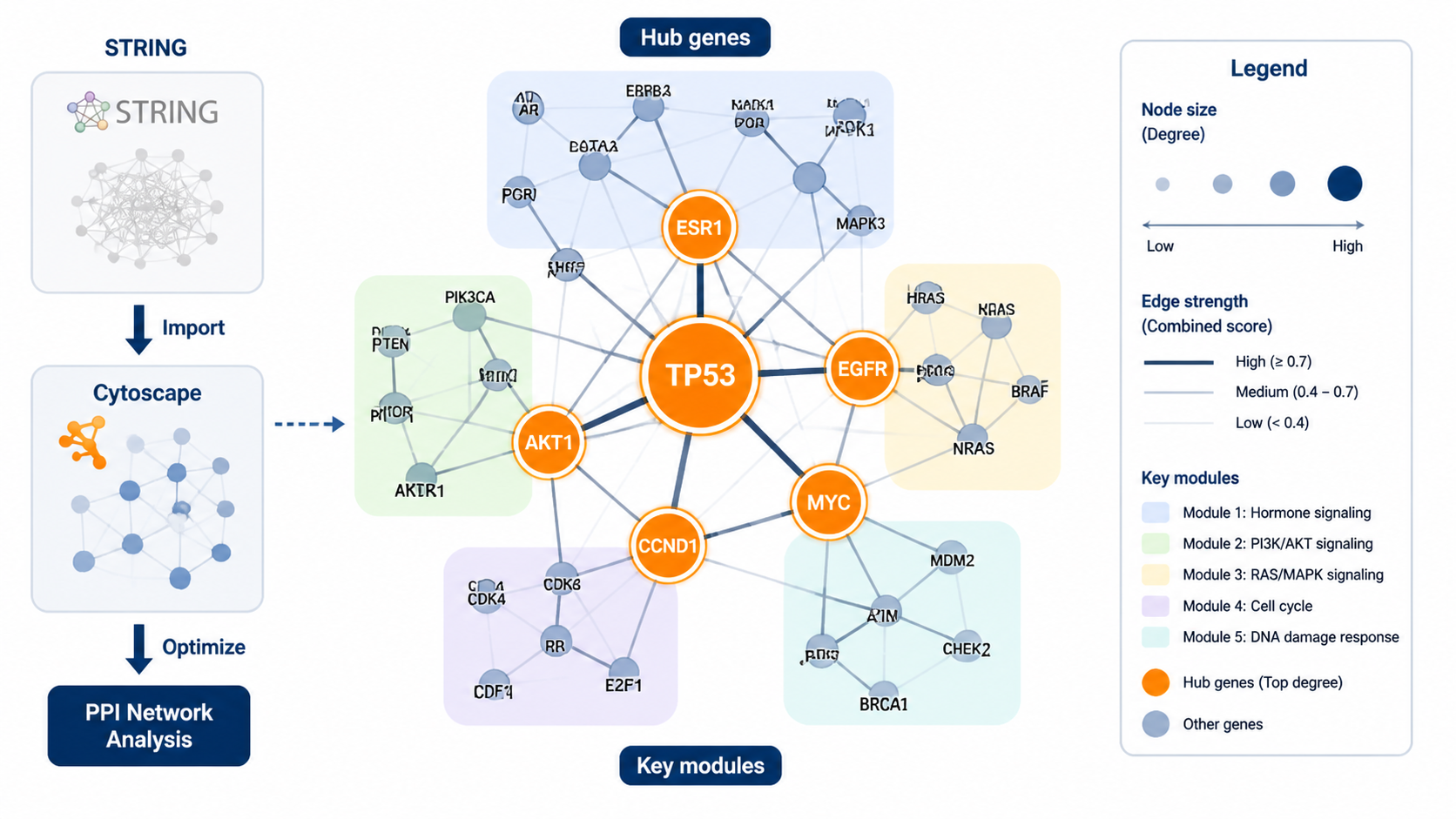
3.4 用圆形布局突出Hub基因
完成参数设定后,可使用Attribute circle layout-degree。
也就是按Degree值排列成圆圈。
这样做的好处很直接:
- 最高连接度的基因更容易被识别。
- 网络层次更清楚。
- 文章中的图注更容易写。
在课程案例中,权重最大的基因是MYC。
这说明网络的中心性特征可以通过布局和参数设置更清晰地呈现。
4. 用MCODE筛选关键模块
4.1 关键模块比单个节点更有解释力
PPI网络构建步骤不仅要找单个Hub基因,也可以找功能模块。
在疾病机制研究中,模块往往比单个节点更接近真实生物过程。
MCODE插件就是常用工具。
它可以在当前网络中识别高密度连接区域。
4.2 标准筛选流程
知识库中的常用流程是:
- 安装MCODE插件。
- 打开Analyze Current Network。
- 查看评分排序结果。
- 选择评分靠前的模块。
- 点击Create Cluster Network。
这样得到的模块图,往往更适合放进结果部分。
它可以帮助你从“全局网络”过渡到“局部机制”。
4.3 什么时候适合用模块分析
如果你的研究已经有明确方向,模块分析会更有价值。
例如:
- 炎症相关基因簇。
- 代谢相关基因簇。
- 细胞周期相关基因簇。
模块的价值在于,它能把分散的互作关系,收束成可解释的生物学单元。
5. 提高PPI网络质量的实战建议
5.1 先标准化,再可视化
很多低质量网络,不是因为数据库不行,而是前处理不到位。
所以建议按这个顺序做:
- 标准化基因名。
- 筛选显著基因。
- STRING构网。
- Cytoscape美化。
- MCODE或Hub分析。
顺序错了,后面再怎么修图也难救。
5.2 保持图的简洁度
发表级PPI图有一个共同点。
就是重点突出,信息不过载。
可控制以下内容:
- 不显示无意义孤点。
- 不堆叠过多标签。
- 不滥用颜色。
- 保留最能说明问题的节点和模块。
5.3 让图服务于结论
PPI网络构建步骤的最终目标,不是做出一张“复杂的图”,而是支持论文结论。
因此,每张图都要回答问题:
- 哪些基因处于核心位置。
- 哪些模块可能参与疾病过程。
- 哪些节点最值得后续验证。
如果图不能回答问题,它就只是装饰。
总结Conclusion
PPI网络构建步骤的核心可以概括为三句话。
先整理好输入基因,再用STRING快速构网,最后用Cytoscape做美化、分析和Hub筛选。
高质量PPI图的关键,不在于软件本身,而在于数据规范、参数选择和图形表达。
如果你正在写论文、做课题或准备结果图,可以直接按本文流程执行。
想进一步节省时间,提升图表规范性,也可以结合解螺旋的产品与课程资源,把PPI网络构建步骤做得更快、更稳、更接近发表标准。
- 引言Introduction
- 1. 明确PPI网络的输入数据
- 2. 用STRING快速构建PPI网络
- 3. 用Cytoscape完成网络美化与核心基因筛选
- 4. 用MCODE筛选关键模块
- 5. 提高PPI网络质量的实战建议
- 总结Conclusion