引言Introduction
ceRNA网络教程的核心痛点很明确。很多人知道ceRNA是热门方向,却卡在“怎么选分子、怎么取交集、怎么建网、怎么解释”这四步。若流程不清,文章就容易停在概念层面,难以形成可发表的结果。本文将按纯生信思路,带你从定义、筛选、构网到验证,完整梳理ceRNA网络教程的实战路径。
1. 先理解ceRNA网络的本质
1.1 ceRNA不是一种分子,而是一种调控机制
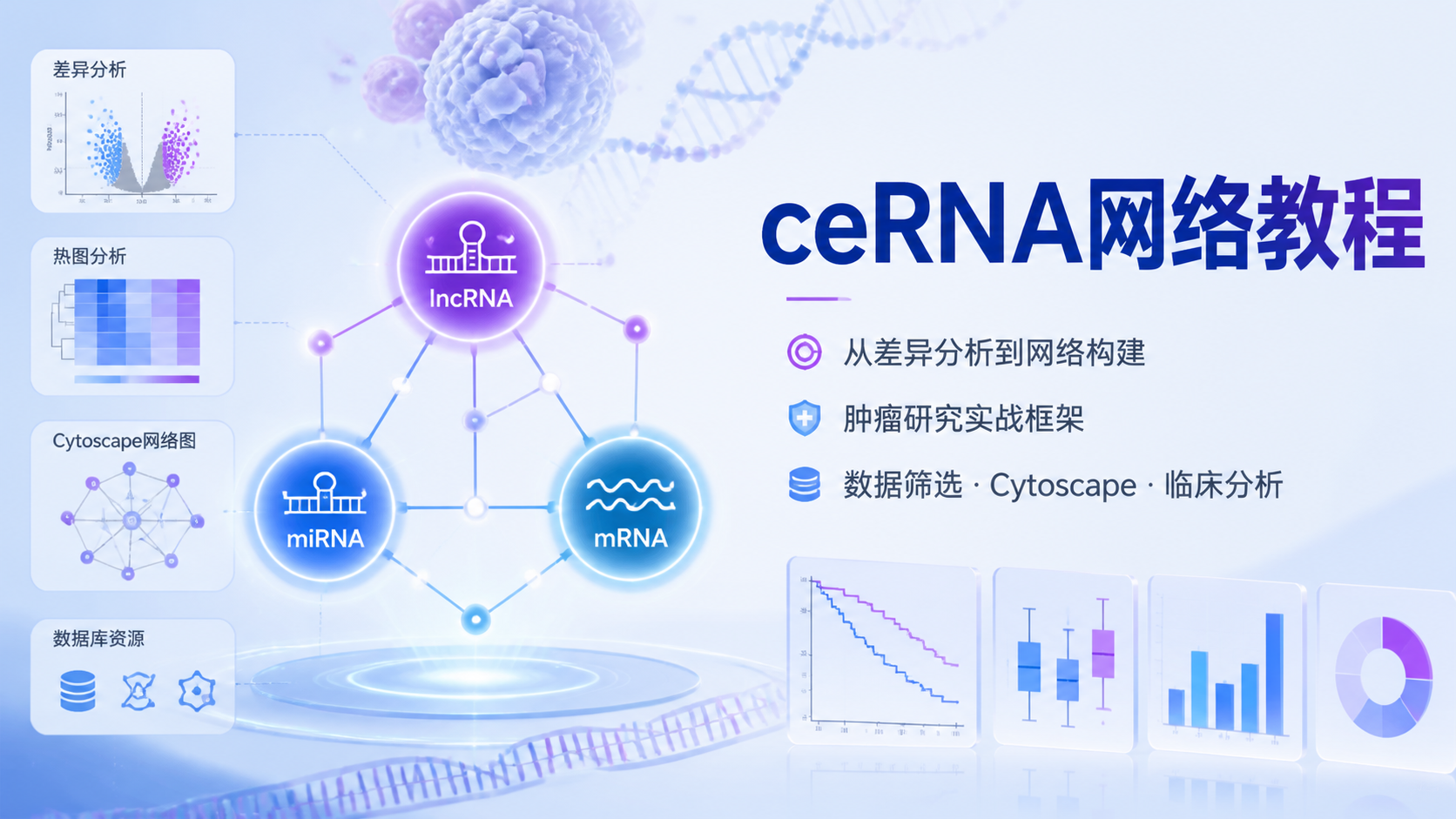
ceRNA的全称是竞争性内源RNA。它不是lncRNA或circRNA这类“分子类型”,而是RNA之间的调控模式。其核心逻辑是,不同RNA通过共享miRNA响应元件,竞争结合同一miRNA,从而影响彼此表达。
在这个机制里,miRNA像“抑制器”。当某个非编码RNA增多时,会吸走更多miRNA,留给mRNA的miRNA就变少。结果是mRNA被释放,蛋白翻译增强。这也是ceRNA网络教程中最重要的基础概念。
1.2 ceRNA网络为什么适合做肿瘤研究
ceRNA不是少数分子的孤立关系,而是一个网状调控系统。一个miRNA可对应多个靶基因,一个mRNA或非编码RNA也常含有多个MRE位点。因此,ceRNA天然适合解释肿瘤中“多分子协同失衡”的现象。
对于医学生和科研人员来说,这类研究的优势在于:
- 可从高通量数据直接切入。
- 可结合预后、分期、免疫浸润等临床维度。
- 可进一步延伸到机制验证和转化研究。
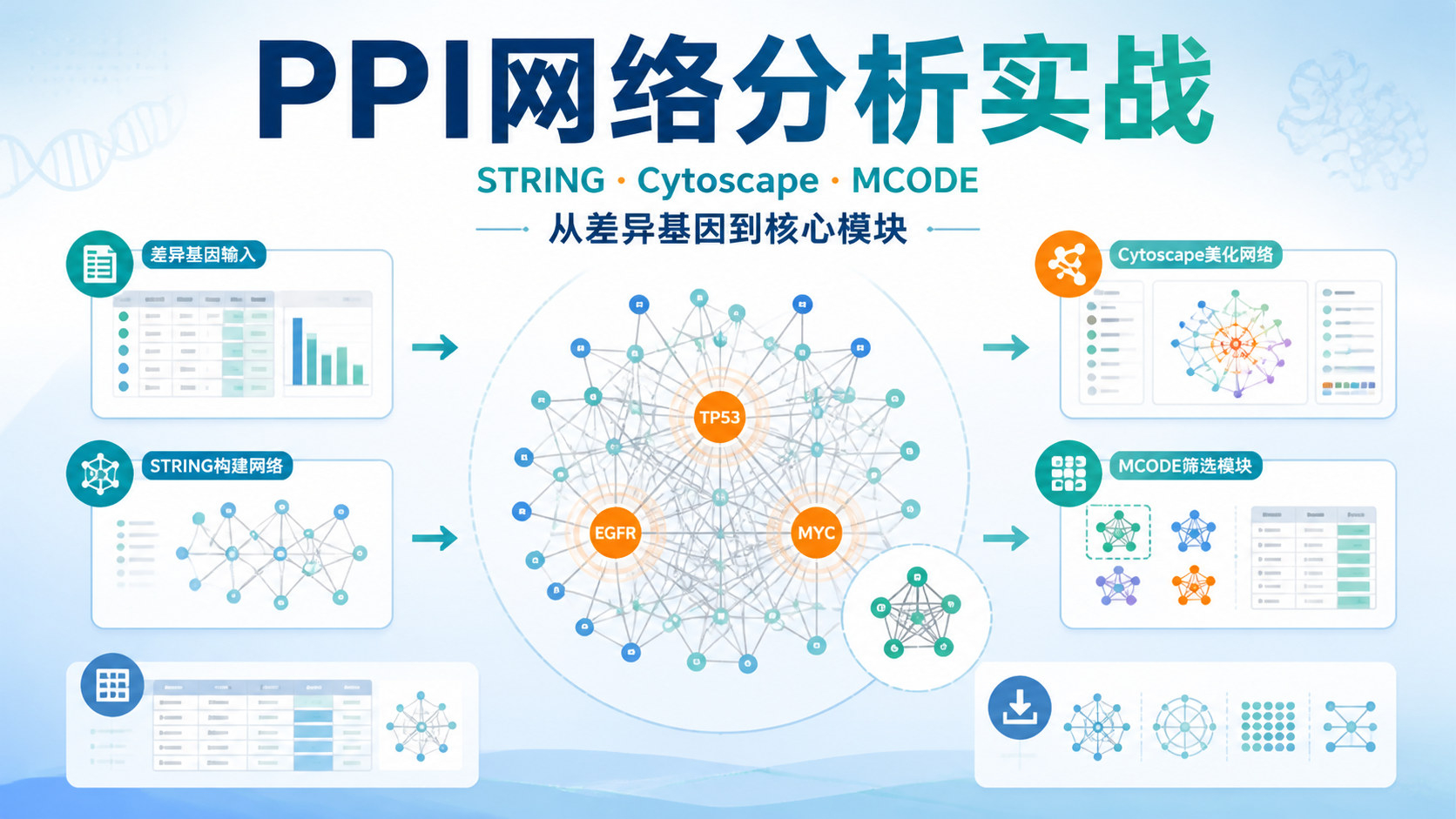
2. ceRNA网络教程的标准分析框架
2.1 先做差异分析,再做功能解释
纯生信套路通常从癌组织和癌旁组织入手。常见做法是对circRNA、miRNA和mRNA进行差异分析,筛出显著变化的分子。根据课程资料,差异分析可采用常规统计标准,如 P < 0.05 且 |logFC| 达到阈值 。
接着,对差异mRNA做GO、KEGG或GSEA富集分析。这样可以先回答“这些差异基因涉及什么功能通路”,再进入网络构建。先功能,后机制,是ceRNA网络教程里最稳妥的顺序。
2.2 按“挑圈联靠”思路构网
ceRNA网络的核心是“挑圈联靠”四步法:
- 挑出差异表达的RNA。
- 圈定可能互作的miRNA。
- 联合数据库预测靶基因。
- 靠取交集筛掉低可信关系。
以circRNA为例,先用数据库预测其可能结合的miRNA,再与差异miRNA取交集。这样能减少大量无关候选。随后再用这些筛过的miRNA去预测mRNA,并与差异mRNA取交集。这个交集策略是提升网络可信度的关键。
2.3 结果输出要清晰
最终你需要得到两类结果:
- 分子列表,包含circRNA、miRNA、mRNA。
- 互作关系表,说明谁和谁相连。
有了这两类结果,才可以导入Cytoscape构建ceRNA网络图。如果节点过多,还可以进一步筛选关键子网络或核心分子,提升文章聚焦度。
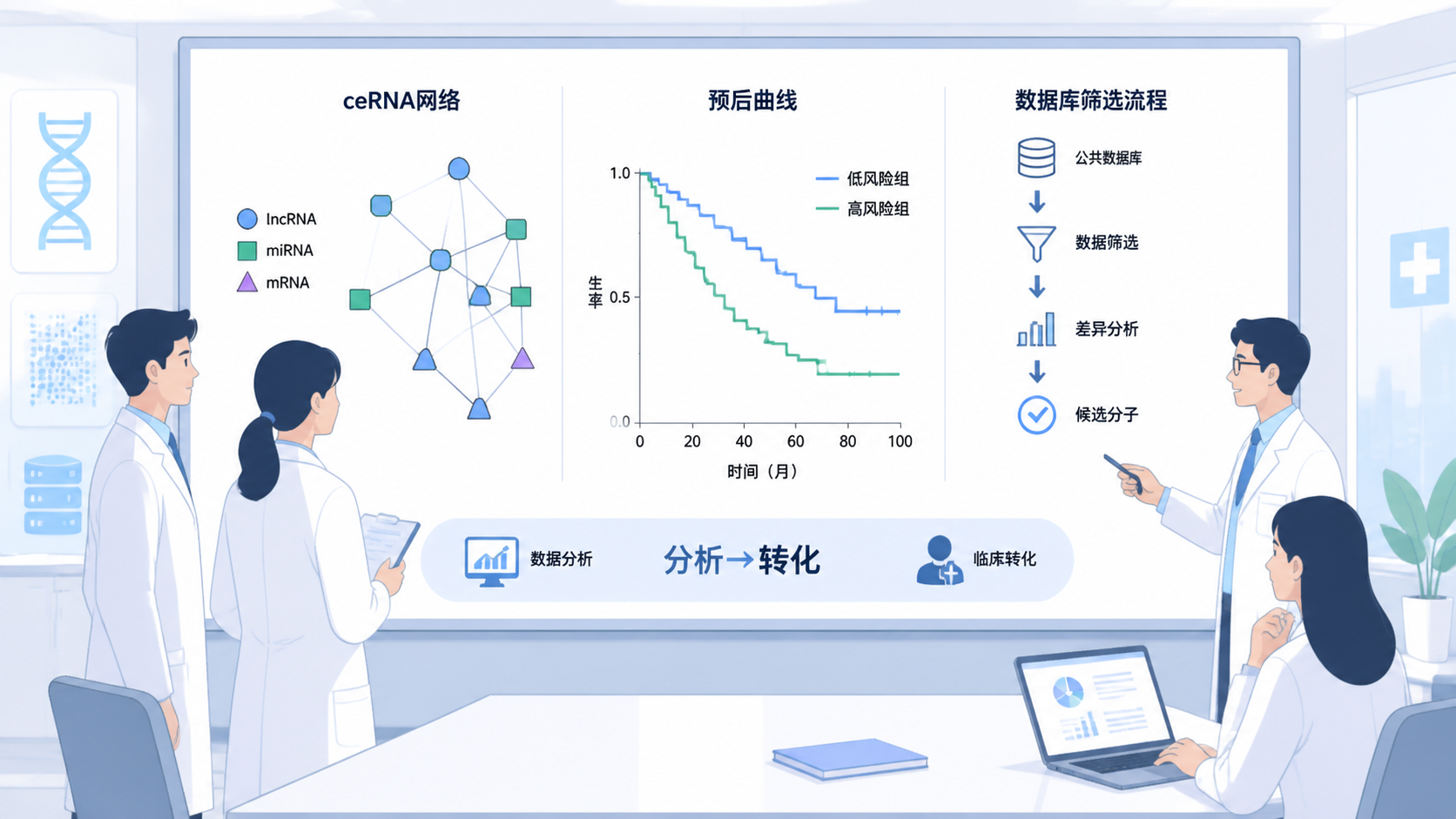
3. ceRNA网络教程中的数据来源与筛选策略
3.1 数据量不是越大越好,但要够用
如果经费充足,推荐做较完整的高通量测序。若预算有限,最简方案也可行。课程中提到,3对3的样本设计仍能完成基本分析 ,但样本较少时,临床信息分析的价值会受限。
实际操作中,至少建议保留:
- circRNA或lncRNA。
- miRNA。
- mRNA。
其中,circRNA或lncRNA更偏创新性,mRNA用于功能解释,miRNA用于构桥。缺少miRNA数据时,仍可依赖数据库预测,但网络准确性会下降。
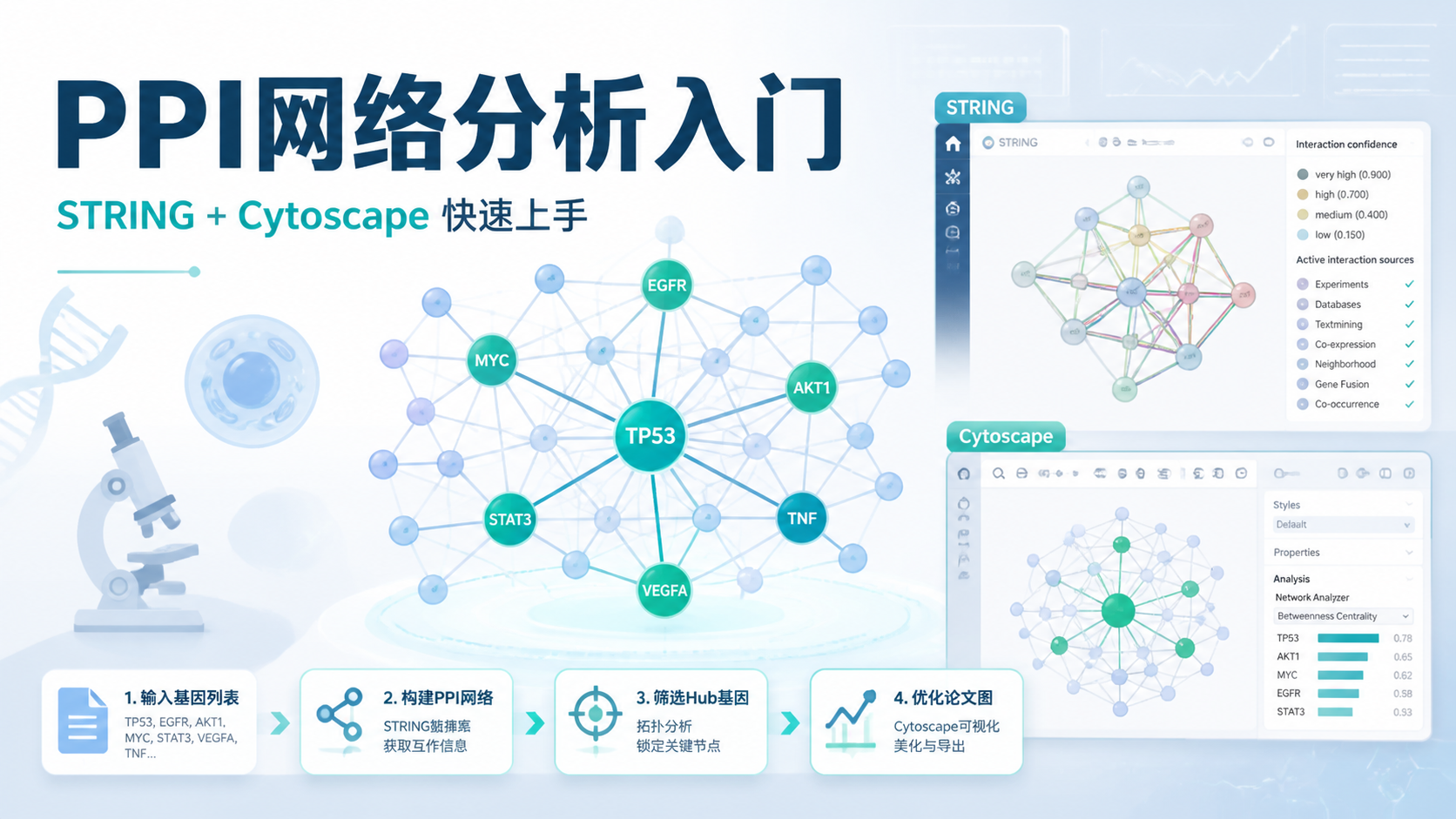
3.2 常用数据库与工具
构建ceRNA网络时,常见数据库包括:
- miRcode,用于lncRNA和miRNA关系。
- miRTarBase,用于可靠的miRNA-mRNA关系。
- miRDB、TargetScan,用于补充预测。
- starBase,可辅助筛选lncRNA-miRNA互作。
课程资料中还提到multiMiR可整合多个数据库,提高候选筛选效率。数据库越多,证据链越完整,但也越需要交集过滤。
3.3 筛选标准要统一
为了减少噪音,建议在构网前统一阈值。常见做法包括:
- 相关性分析:|cor| > 0.4 或 |cor| > 0.5。
- 显著性:P < 0.001。
- 互作证据:优先保留有实验验证或高置信度预测的关系。
ceRNA网络教程里最常见的错误,不是不会建网,而是筛选标准前后不一致。
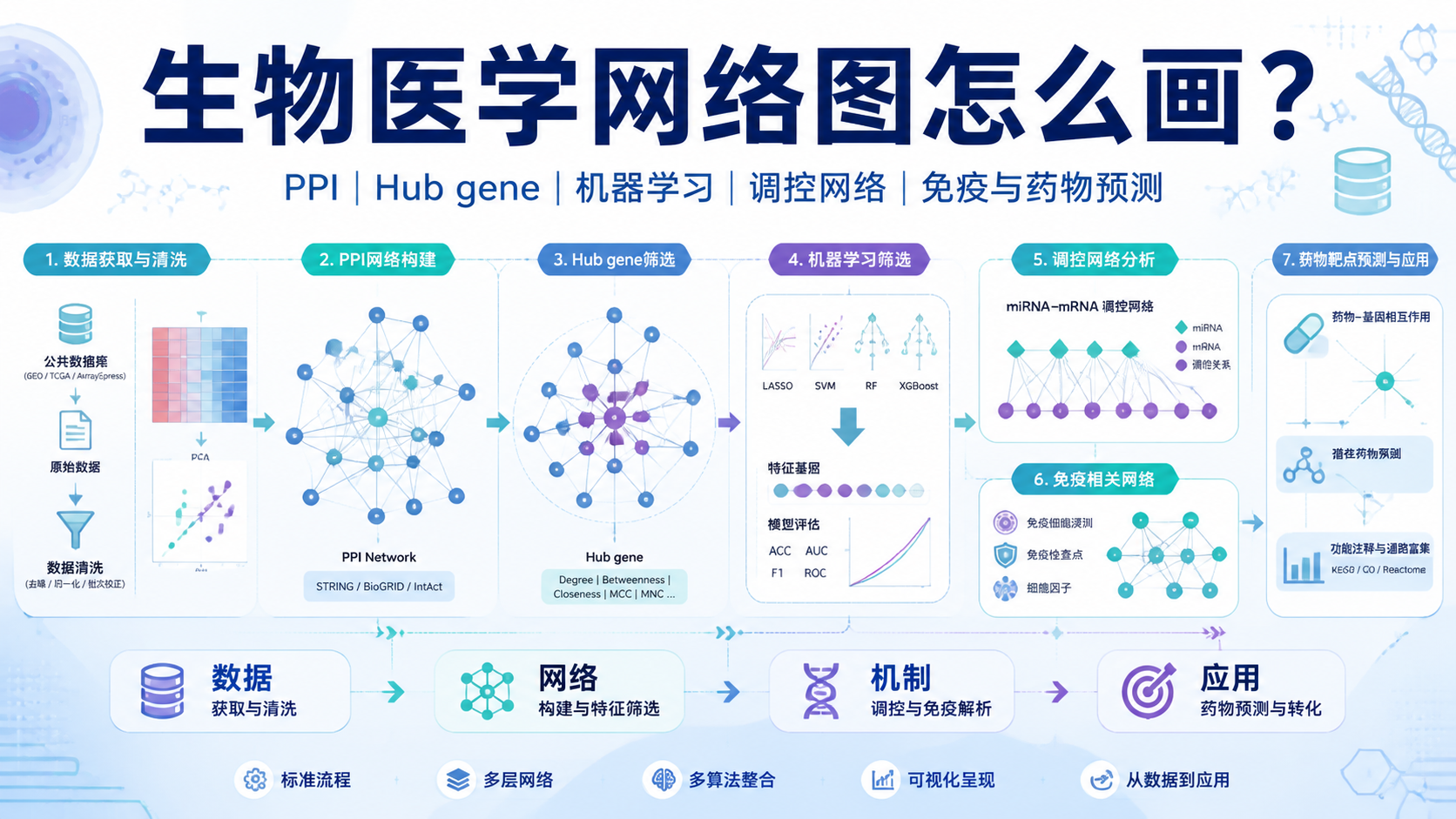
4. ceRNA网络教程的实战流程
4.1 第一步,差异分析
先对测序数据做标准化和差异分析,得到显著差异表达的circRNA、miRNA、mRNA。这个步骤决定后续网络的起点。若起点不稳,后面再复杂的网络也缺乏说服力。
建议同时输出:
- 火山图。
- 热图。
- 差异基因列表。
这些图表不仅用于展示,也便于后续筛选。
4.2 第二步,取靶向关系交集
以差异circRNA为例,先预测它可能结合的miRNA,再和差异miRNA做交集。随后再对这些miRNA预测mRNA,并与差异mRNA取交集。课程中所强调的“挑圈联靠”,本质就是用交集缩小候选范围,保留最可能成立的互作链条。
如果只靠单一数据库或只看预测结果,不做交集筛选,网络往往过大且噪音高。这也是ceRNA网络教程中最值得掌握的核心方法。
4.3 第三步,构建Cytoscape网络
将互作关系表导入Cytoscape。设置节点形状、颜色和边的样式后,就可以形成可视化网络。通常可按RNA类型区分:
- circRNA或lncRNA一种颜色。
- miRNA一种颜色。
- mRNA一种颜色。
如果网络节点过多,可以继续做子网络分析,筛选中心度较高的核心节点。这样更利于后续机制阐释和文章聚焦。
4.4 第四步,做临床相关分析
网络建好后,下一步是评价临床意义。可进一步分析:
- 基线资料。
- 单因素和多因素Cox回归。
- 生存曲线。
- 预后模型。
课程资料指出,如果筛到多个有预后价值的分子,还可以构建模型并用公共数据集验证外推性。从网络到临床,是ceRNA网络教程真正走向发表的关键一步。
5. 提升文章质量的几个实战建议
5.1 可以做二次挖掘,但要先查文献
公共数据集是低成本入口,但不是“拿来就用”。在二次挖掘前,应先检索PubMed,确认该数据集是否已被反复挖掘,尤其是否已有类似ceRNA文章发表。否则容易陷入同质化。
5.2 可结合WGCNA或免疫分析
如果样本数达到一定规模,课程资料建议考虑WGCNA,先找出感兴趣模块,再结合miRNA和mRNA构建特定通路相关ceRNA网络。若最终筛出单个关键分子,还可进一步联合GSVA、免疫浸润分析,增强深度。
5.3 结果解释要避免过度推断
ceRNA网络提示的是调控关联,不等于直接因果。写作时应区分:
- 预测关系。
- 相关关系。
- 已验证关系。
这种表述上的严谨性,是E-E-A-T中“可信度”的重要体现。
总结Conclusion
ceRNA网络教程的本质,不是学会画一张网,而是掌握一套可复用的研究流程。它包括差异分析、靶向预测、交集筛选、网络构建、临床关联和模型验证。只要路径清晰,ceRNA就能从概念变成可发表的研究框架。
如果你希望把ceRNA网络教程真正落地到课题设计、数据分析和文章产出,可以结合解螺旋的系统化课程与实战资源,快速减少试错成本,提升出稿效率。
- 引言Introduction
- 1. 先理解ceRNA网络的本质
- 2. ceRNA网络教程的标准分析框架
- 3. ceRNA网络教程中的数据来源与筛选策略
- 4. ceRNA网络教程的实战流程
- 5. 提升文章质量的几个实战建议
- 总结Conclusion