引言Introduction
PPI 网络教程 看起来像“高阶生信玩家的黑话”,其实核心只有一句话:把差异基因丢进数据库,看看它们谁和谁爱“串门”。对医学生、医生和科研人员来说,难点不在概念,而在流程。如果你想快速把PPI网络做出来、画得好看、还能找出hub基因,这篇就够用了。
1. 先搞懂PPI网络到底在看什么
1.1 PPI不是“蛋白排排坐”
PPI,指蛋白-蛋白相互作用网络。简单说,就是看某一批蛋白之间有没有功能关联,谁和谁经常一起出现,谁更像“社交达人”。
在生信文章里,PPI网络最常见的用途有三个:
- 找关键差异基因。
- 观察蛋白之间的互作关系。
- 挖掘hub基因和关键模块。
你可以把PPI网络理解成“分子层面的朋友圈”。 谁连接得多,谁往往更值得重点关注。
1.2 为什么大家都爱做PPI网络
因为它很适合把一堆差异基因从“名单”变成“故事”。
单纯列出几十个基因,读者容易困。
但一张PPI图能直接告诉你:
- 哪些蛋白关系紧密。
- 哪些节点更核心。
- 哪些模块可能参与同一条通路。
这也是PPI 网络教程 最实用的价值。它不只是画图,而是帮你把结果变成更像“发现”。
2. 做PPI网络前,先准备好输入数据
2.1 输入什么最合适
课程知识库里反复强调,PPI网络通常用差异表达基因 或筛选后的significant genes 来构建。常见做法是先完成筛选,再把基因名提交到STRING。
准备时,最重要的是两列信息:
- 基因名或蛋白名。
- 物种信息,通常是 Homo sapiens。
如果是从分析结果表中导出,建议优先使用 SYMBOL 列。这样匹配更稳,少踩坑。
2.2 先确认你的基因列表够不够“干净”
PPI网络最怕两件事:
- 基因名写错。
- 物种选错。
尤其是基因名。一个字符错了,STRING可能就开始“装作不认识你”。
所以在进入 PPI 网络教程 实操前,先检查:
- 是否已经筛掉非显著基因。
- 是否统一用了基因标准名。
- 是否明确选择了人类或对应物种。
输入越规范,后面越少返工。 这句话对科研尤其重要。
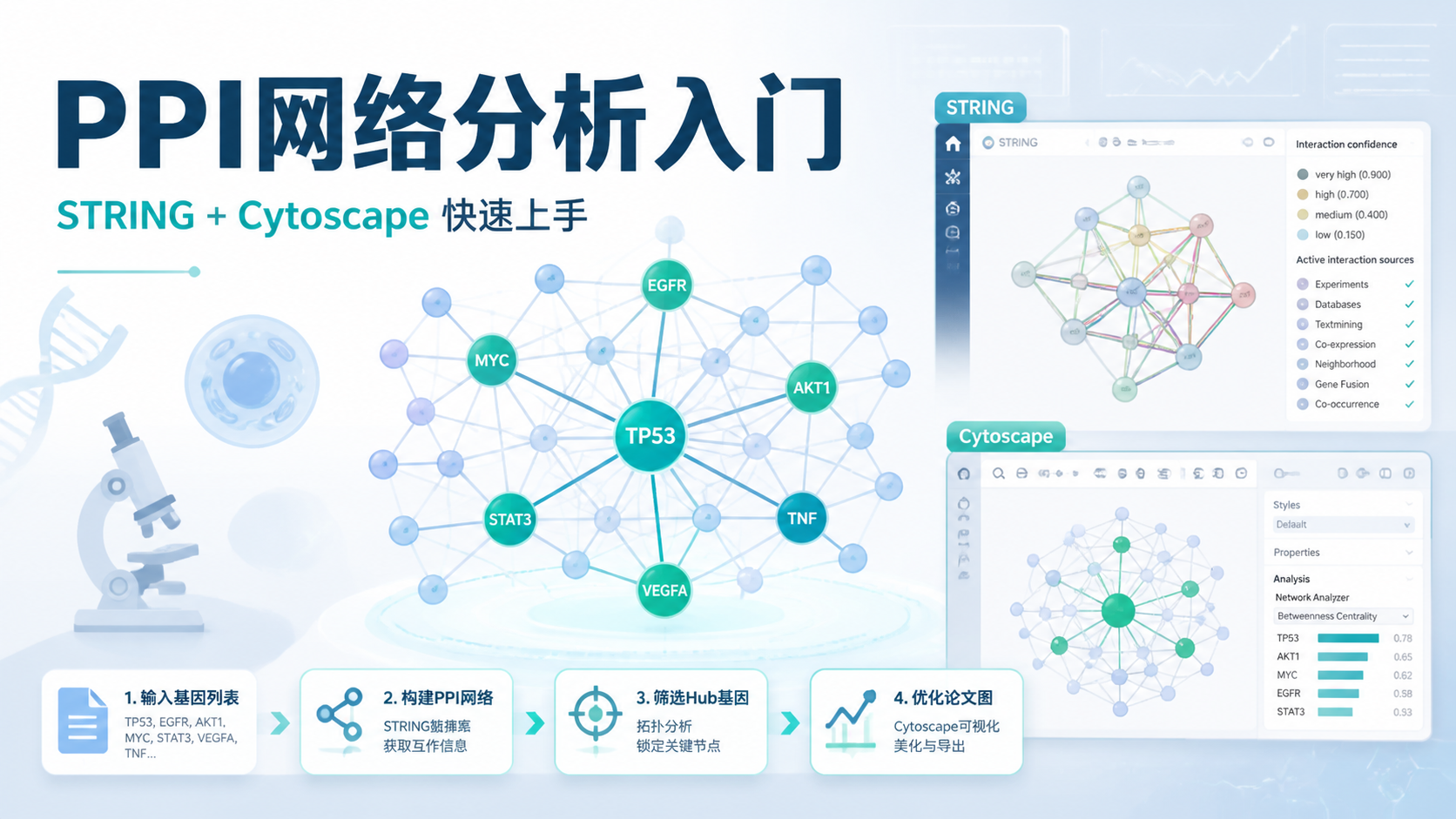
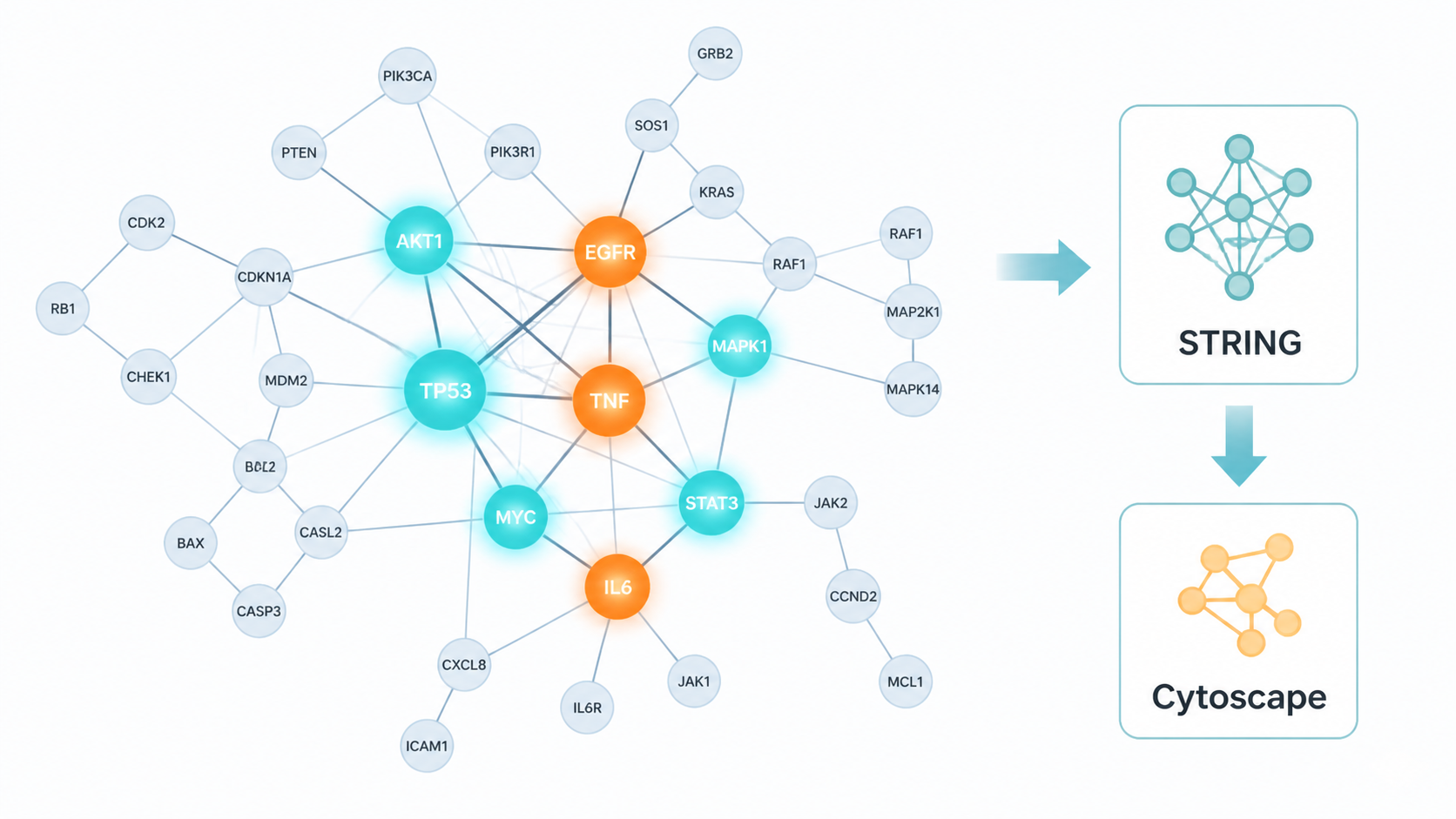
3. 用STRING快速搭出PPI网络
3.1 为什么多数人先用STRING
知识库里给出的共识很清楚。STRING是目前最常用也最方便 的PPI构建数据库之一。
它的优点很直接:
- 在线操作。
- 支持多蛋白检索。
- 可直接导出网络和表格。
- 适合后续导入Cytoscape美化。
对于新手来说,STRING就像“PPI世界的快捷入口”。
3.2 STRING的标准流程
一个相对稳妥的做法如下:
- 打开STRING官网。
- 选择 Multiple proteins 。
- 粘贴基因列表。
- 选择物种,通常是 Homo sapiens。
- 点击 Search 。
- 等待映射完成后点击 Continue 。
- 根据需要调整网络参数。
- 导出结果。
课程里还提到一个实用细节。
当输入基因较多时,不要急着点 Continue,最好等页面完全加载后再操作。
否则可能出现部分基因没被正确映射的情况。
3.3 网络参数怎么调更合理
在STRING里,常见设置是按 confidence 来控制互作可靠度。
知识库中给出的示例是 confidence > 0.4 。这属于常见的中等阈值设置。
你还可以做两件事:
- 隐藏未连接的离散点。
- 导出高清图片和文本表格。
隐藏离散点不是必须,但能让图更清爽。
如果你要投稿,图像美观度会直接影响阅读体验。
4. 用Cytoscape把PPI图“打扮”得更像论文图
4.1 为什么还要用Cytoscape
STRING能出图,但Cytoscape更适合“精装修”。
知识库中明确提到,Cytoscape可以用于:
- 重新导入STRING导出的网络表。
- 美化节点和连线。
- 计算网络拓扑。
- 筛选hub基因。
- 挖掘关键模块。
一句话概括:STRING负责建房,Cytoscape负责装修。
4.2 导入和美化的基本步骤
标准流程一般是:
- 打开Cytoscape。
- 点击 File > Import > Table from File 或导入网络文件。
- 选择STRING导出的 tsv 文件。
- 确认 node1 和 node2。
- 点击 OK。
- 在 Style 中调整节点大小、颜色、形状。
- 用 Layout 调整整体布局。
知识库里提到,节点样式可以按 Degree 来调整。
Degree越大,点越大越亮;Degree越小,点越小越暗。
连线则可按 Combined Score 调整粗细。
这样做的好处是,核心节点一眼就能被看见。
不然一张网密得像蜘蛛开会,读者只会想关页面。
4.3 怎么快速找hub基因
在Cytoscape里,常用两种办法:
- NetworkAnalyzer 分析网络拓扑。
- MCODE 或 ** CytoHubba** 筛选核心模块和hub基因。
知识库中给了一个典型思路。
通过 Analyze Network 后,可以看到各节点的连接度。再按 degree 排布成圆圈,最核心的节点会更明显。示例中,** MYC** 被识别为权重最大的基因。
如果你需要模块分析,可以用 MCODE:
- 打开 Apps。
- 安装 MCODE。
- 点击 Analyze Current Network。
- 生成模块。
- 导出关键模块图。
这一步的重点不是“炫技”,而是把一堆点变成可解释的生物学模块。
5. 新手最常见的坑,提前帮你排掉
5.1 网络太散,像“失联社交圈”
如果网络里很多孤立点,通常有几个原因:
- 输入基因和数据库匹配不充分。
- 阈值太高。
- 基因本身互作证据不足。
解决思路很简单:
- 先确认基因名是否标准。
- 适当调整 confidence。
- 必要时隐藏未连接节点。
别一上来就怪软件,先怀疑名单。 这是生信里很实用的排错逻辑。
5.2 图太乱,论文审稿人看了想重开
图乱的常见原因是节点太多,布局没调好。
建议优先做这些优化:
- 用圆形布局或属性布局。
- 按 degree 调整大小。
- 按表达量或分组调整颜色。
- 只保留重点模块。
如果图还是太复杂,说明你需要先缩小分析范围。
比如先从关键差异基因入手,再做PPI。
5.3 只会出图,不会讲结果
这是很多初学者的真实痛点。
PPI图不是终点。你还要回答:
- 哪个基因最核心。
- 哪个模块最紧密。
- 这个模块可能参与什么功能。
图只是证据,结论才是文章的灵魂。
总结Conclusion
PPI 网络教程的核心,其实就是三步。 先准备标准化的差异基因,再用STRING快速构建互作网络,最后用Cytoscape美化并筛选hub基因。对医学生、医生和科研人员来说,这套流程不复杂,但非常实用。它能把零散的基因结果,变成更有结构、更有说服力的机制图。
如果你想少走弯路,直接把PPI网络做得更规范、更适合论文展示,可以借助解螺旋的课程和工具体系 ,把STRING、Cytoscape和模块筛选流程一次理顺。把“会做图”升级成“会讲故事”,这才是真正的生信入门。
- 引言Introduction
- 1. 先搞懂PPI网络到底在看什么
- 2. 做PPI网络前,先准备好输入数据
- 3. 用STRING快速搭出PPI网络
- 4. 用Cytoscape把PPI图“打扮”得更像论文图
- 5. 新手最常见的坑,提前帮你排掉
- 总结Conclusion