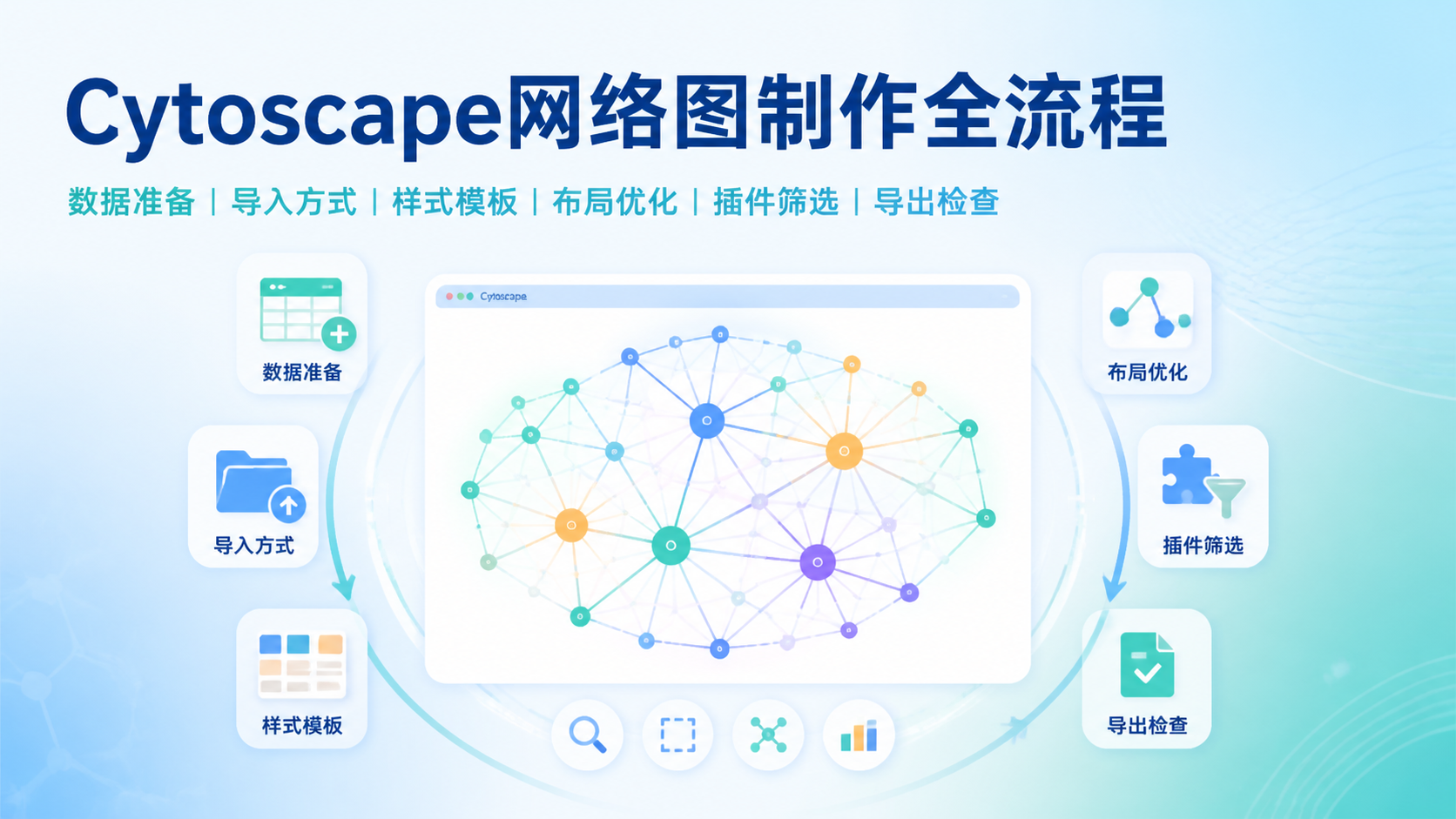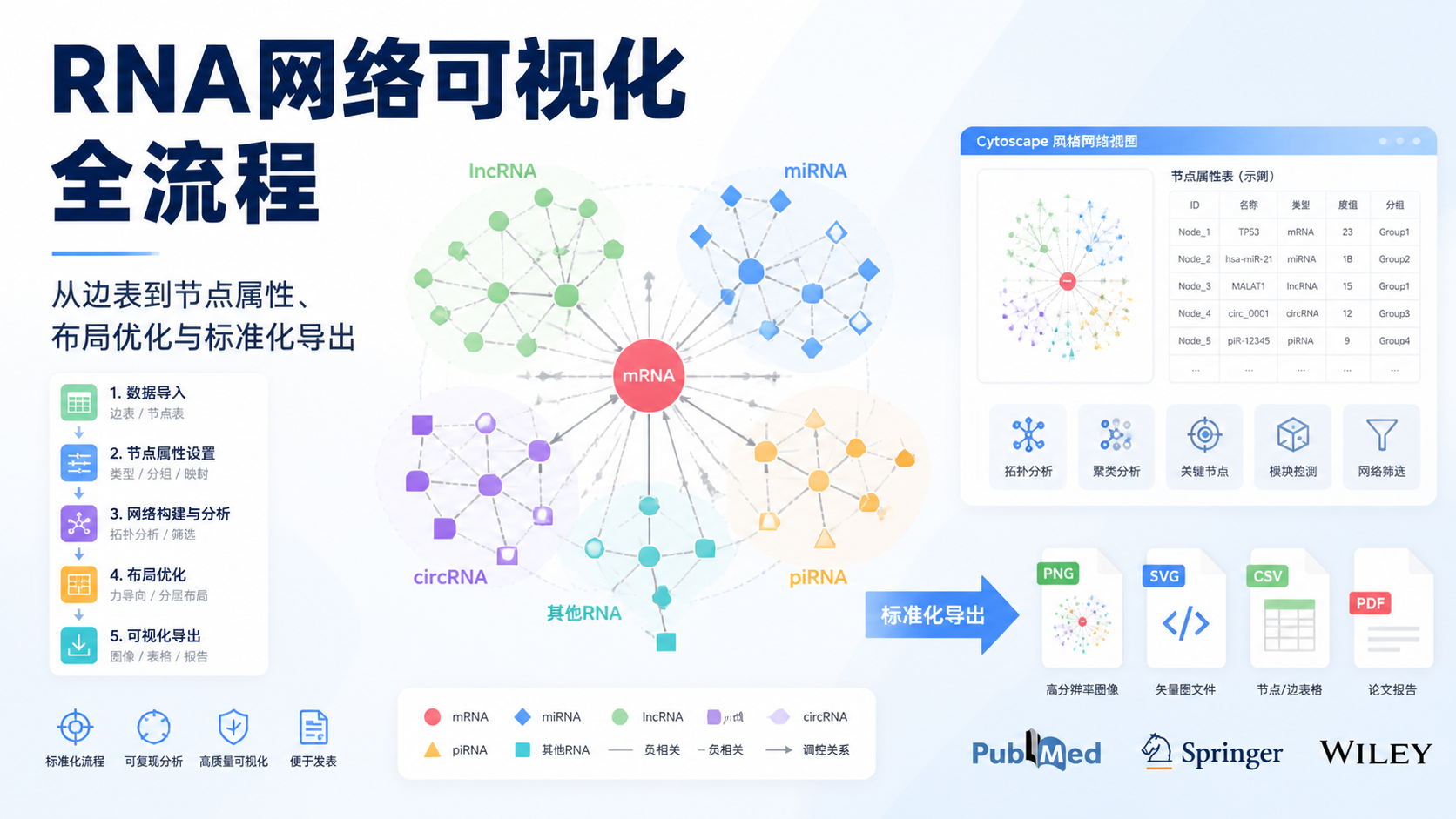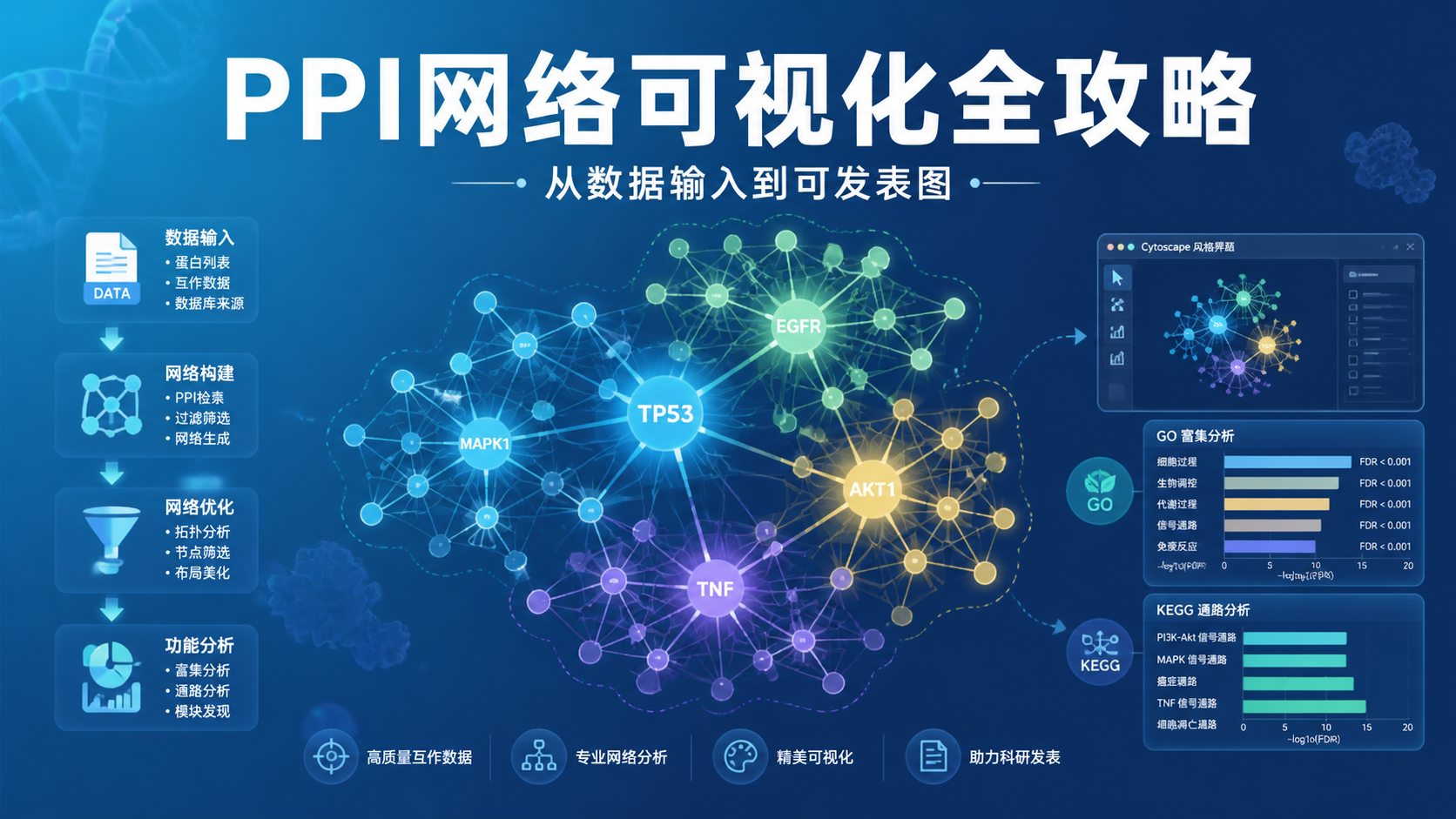
引言Introduction
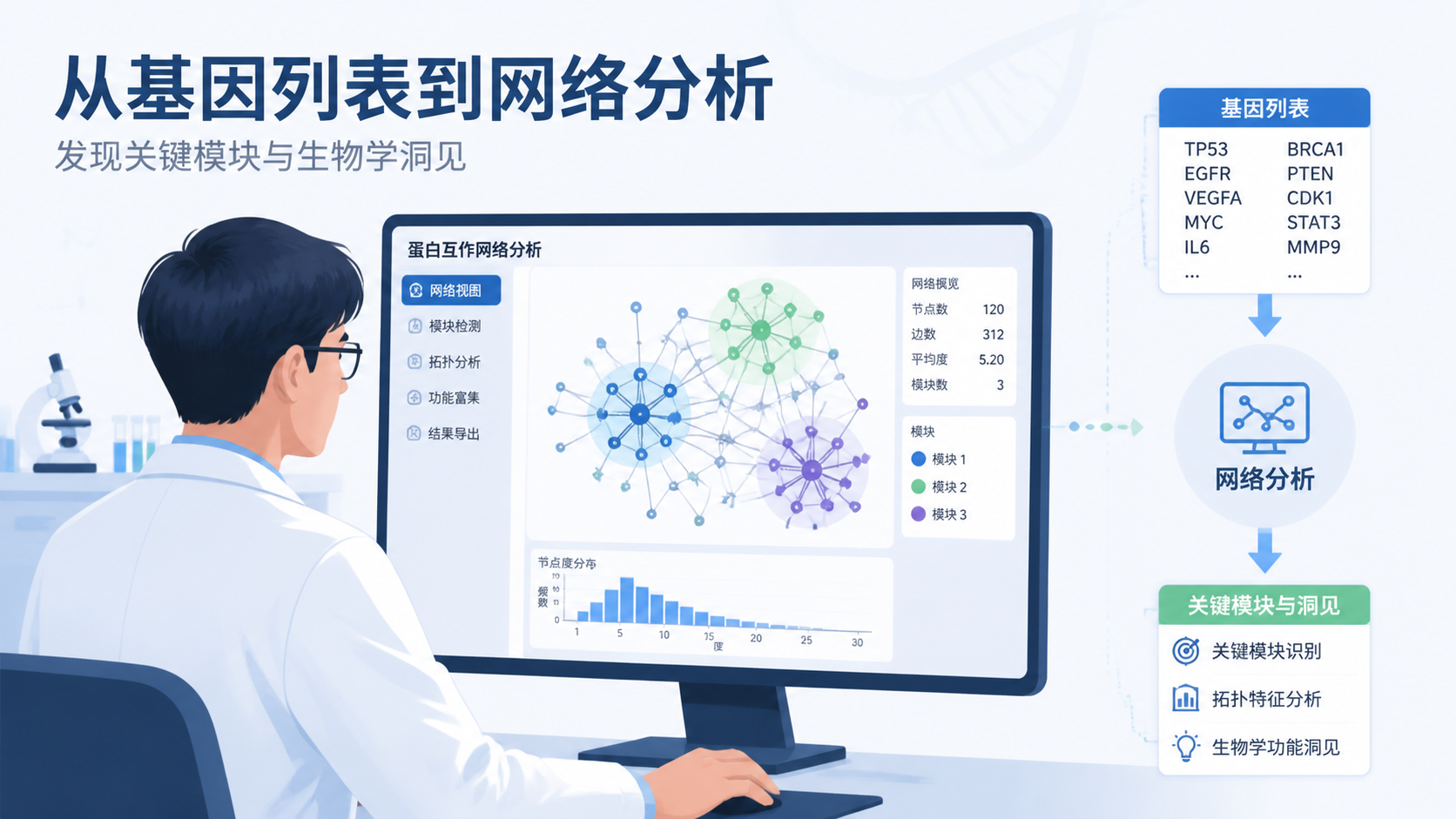
PPI网络可视化是理解差异基因、生物通路和疾病机制的关键一步。很多人能拿到基因列表,却不知道如何把数据转成可解释的网络图。真正有价值的不是“画出图”,而是用对方法,让网络结果可复现、可解释、可发表。
1. 明确PPI网络可视化的输入类型
1.1 先判断你手里是什么数据
做 PPI网络可视化 之前,第一步不是选数据库,而是先确认输入类型。常见输入包括两类。
一类是带表达值的基因列表。另一类是芯片或测序表达谱数据。前者适合快速做互作网络和功能分析。后者更适合先做差异分析,再筛选显著基因进入网络。
输入类型不同,后续分析路径也不同。 如果是基因列表,可以直接进入网络构建。如果是表达谱数据,建议先完成差异筛选,再把显著基因映射到互作数据库。
1.2 物种和ID类型要先统一
在 NetworkAnalyst 中,上传基因列表时需要指定物种和 ID 类型。常见 ID 包括 Entrez、Ensembl 等。
如果你的 ID 不在支持范围内,有两种处理方式。
- 保持 ID type 为 Not Specified,继续后续分析。
- 先用微阵列注释文件把探针注释转换为常见基因 ID。
这一步决定了后面能否准确匹配到数据库。 ID 混乱会导致大量节点丢失,也会影响后续富集结果。
2. 选对数据库,比盲目建图更重要
2.1 通用PPI、组织特异性PPI要区分
PPI网络可视化 并不只有一种数据库。常用模块包括通用蛋白互作网络和组织特异性 PPI。
通用 PPI 常见数据库有 IMEx、STRING、HuRI、Rolland。它适合做整体机制探索。
组织特异性 PPI 来自 DifferentialNet,可选择 45 种组织。它更适合研究肺、肝、脑等特定器官相关问题。
如果你的课题关注“某个组织内的疾病机制”,优先考虑组织特异性 PPI。因为同一蛋白在不同组织中的互作关系并不完全相同。
2.2 置信度阈值要合理设置
以 STRING 为例,每条互作都有置信度评分,范围通常在 400 到 1000。
评分越高,证据越强。 你可以通过 cutoff 筛掉低分互作。
如果还勾选 Require experimental evidence,说明只保留实验验证过的互作。
经验上,阈值设得过低,网络会过大,噪音也会更多。设得过高,网络可能过于稀疏,无法形成连通结构。关键是平衡灵敏度和特异性。
3. 控制网络规模,避免“看不懂的大图”
3.1 不是越大越好
NetworkAnalyst 在构建互作网络后,会把显著基因映射到数据库中,形成较大的子网络和多个较小的子网络。
这里常见问题是,网络一大就难以解释。节点太少,又很难提供系统层面的信息。
课程中明确建议,后续分析更适合 200 到 2000 个节点的网络。
这个范围通常更利于识别核心模块,也更适合导出到 Cytoscape 做进一步可视化。
3.2 先看子网络,再做筛选
网络结果页通常会显示子网络名称、节点数、边数、以及上传基因中命中的节点。
建议先关注包含更多种子基因的主子网络,而不是所有孤立小岛。
因为孤立模块往往解释价值较低,且不利于后续功能分析。
实操原则很简单。先保留连通性,再追求美观。 这是高质量 ** PPI网络可视化** 的前提。
4. 用对布局和样式,提升可读性
4.1 布局决定网络是否容易解读
在网络图页面,Layout 可以调整节点排布。不同布局会影响你对模块、中心节点和边缘节点的判断。
如果图太拥挤,可以先用自动布局,再局部拖动。
如果节点重叠明显,可以减少重叠,或切换到更适合模块识别的布局方式。
布局的目标不是“好看”,而是让结构关系一眼可见。 这是很多初学者最容易忽略的一点。
4.2 颜色、大小、边线要服务于问题
NetworkAnalyst 提供多种显示模式。
- Topology:按 degree 值着色。
- Expression:高亮输入的基因。
- Plain:统一灰色。
- Collapsed:仅显示重要节点。
同时还可以调节点大小、边颜色、边透明度和粗细。
如果研究重点是 hub gene,建议突出高连接度节点。
如果重点是表达变化,建议用 Expression 模式高亮差异基因。
可视化的核心不是堆信息,而是突出你的研究问题。
5. 把功能分析嵌入网络,而不是单独做图
5.1 功能分析能解释“为什么这些蛋白连在一起”
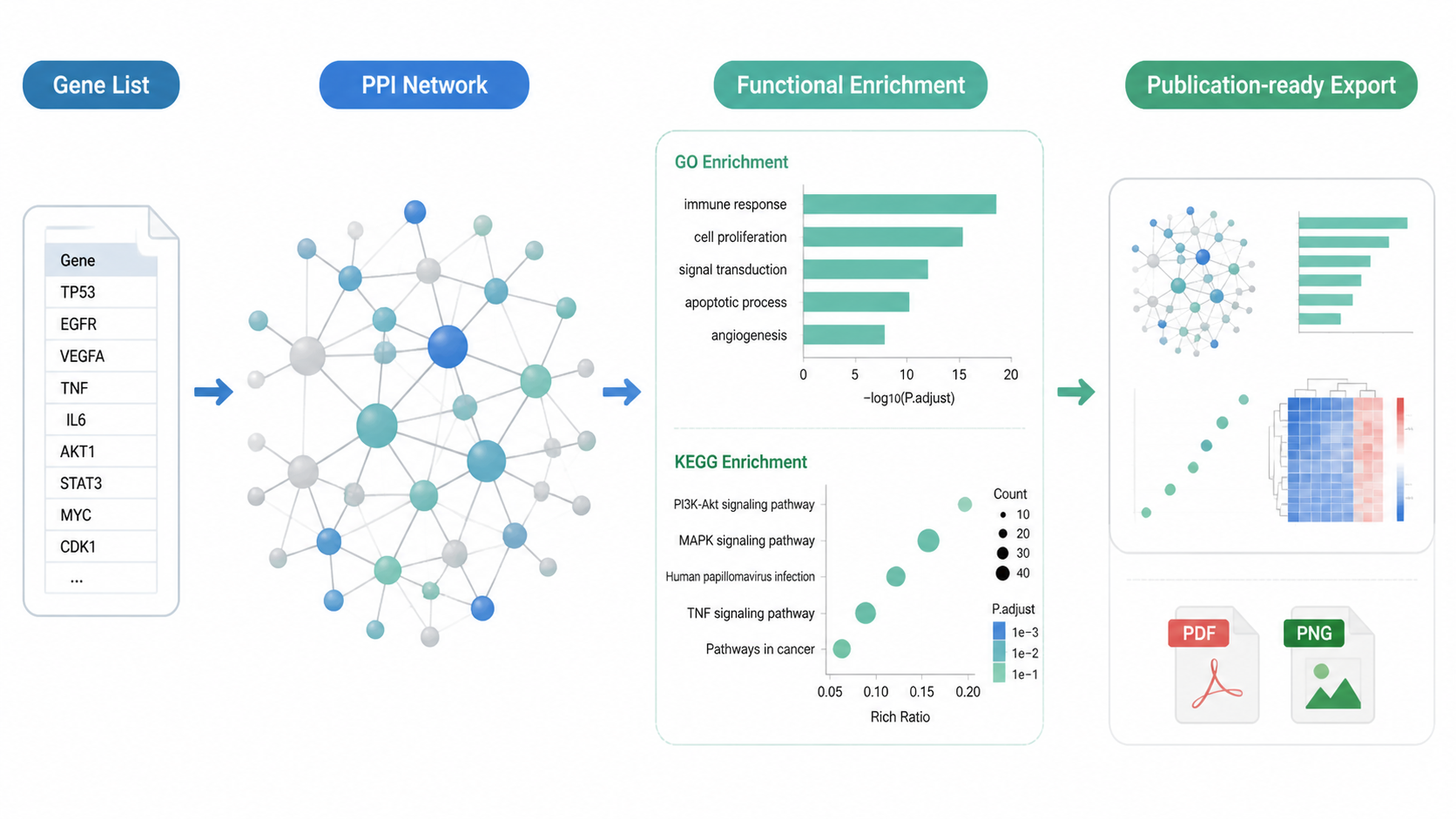
PPI网络可视化 不只是显示互作关系,更重要的是结合功能分析。
在 NetworkAnalyst 中,可以对选中的节点做 GO 或 KEGG 富集。
操作上可在 Node Explorer 中勾选感兴趣基因,再在 Function Explorer 中选择数据库,例如 KEGG,提交后即可得到结果。
这一步非常关键。因为网络图只能告诉你“谁和谁有关”,功能分析才能告诉你“它们为什么一起出现”。
5.2 先网络,后通路,逻辑更清晰
建议的流程是:
- 先构建 PPI 网络。
- 再筛选核心模块或高亮节点。
- 最后做富集分析解释机制。
如果直接对全部基因做富集,结果可能太分散。
而先通过网络筛出核心节点,再富集分析,通常更容易得到与表型相关的通路。这也是论文中更常见的呈现方式。
6. 结果导出要兼顾发表和复现
6.1 不只导出图片,还要导出网络文件
NetworkAnalyst 支持导出 PNG、SVG 等格式。
同时也可以保存 SIF 格式,用于 Cytoscape 等软件继续分析。
图片适合展示,网络文件适合复现。 两者都要保留。
如果你只是导出一张图,后续很难重新调整阈值、布局或节点样式。
而保留 SIF 文件后,后续可以继续做聚类、模块提取和路径分析。
6.2 Cytoscape 适合做深度美化和扩展分析
课程中也提到,STRING 可以和 Cytoscape 联用。
常见做法是安装 stringApp,再从公共数据库导入网络。
随后可调整 confidence cutoff,或通过 Expand network 扩展新的连接蛋白。
这对文章投稿很重要。 因为 Cytoscape 更方便做风格统一的出版级图,也更适合结合注释文件显示 logFC、P 值、分组信息。
7. 把PPI网络可视化做成可发表的图
7.1 发表级图要同时满足三点
一张好的 PPI网络可视化 图,至少要满足三点。
第一,节点和边的含义清楚。
第二,核心模块或 hub gene 一眼可见。
第三,图注能说明数据来源、数据库和阈值。
如果缺少这些信息,图就只能算演示图,不能算论文图。
7.2 常见可发表策略
常见写法包括:
- 用差异基因构建 PPI。
- 用 degree 筛选 hub gene。
- 结合 KEGG 或 GO 解释核心模块。
- 通过 Cytoscape 调整图形输出。
建议始终保留分析参数。 比如物种、数据库名称、confidence cutoff、是否要求实验验证。
这些信息直接影响可重复性,也是 E-E-A-T 中“可信度”的基础。
总结Conclusion
PPI网络可视化的价值,不在于把网络画出来,而在于把分散的基因、蛋白和通路串成可解释的机制链条。 对医学生、医生和科研人员来说,最实用的思路是先明确输入数据,再选对数据库,控制网络规模,结合功能分析,最后导出可复现结果。
如果你希望更高效地完成从数据上传、网络构建到功能分析的全流程,可以借助解螺旋的工具与教程,把复杂步骤标准化,减少重复试错,快速产出更适合论文和汇报的结果。
- 引言Introduction
- 1. 明确PPI网络可视化的输入类型
- 2. 选对数据库,比盲目建图更重要
- 3. 控制网络规模,避免“看不懂的大图”
- 4. 用对布局和样式,提升可读性
- 5. 把功能分析嵌入网络,而不是单独做图
- 6. 结果导出要兼顾发表和复现
- 7. 把PPI网络可视化做成可发表的图
- 总结Conclusion