引言Introduction
做miRNA研究时,很多人会卡在第一步,不知道如何准确查询miRNA信息 。miRBase数据库是最常用的权威入口之一,能帮助你快速找到miRNA名称、序列、基因组位置、成熟体信息和文献证据。

1. miRBase数据库是什么,为什么值得先学它
1.1 miRBase数据库的核心定位
miRBase数据库是收录miRNA信息的权威公共数据库之一。它不仅提供miRNA的序列数据、注释信息、预测靶标链接 ,还支持新miRNA注册。对于做miRNA课题的人来说,它几乎是必备工具。
在实际研究中,很多下游分析都要先回到miRBase数据库确认基础信息。比如,某个miRNA的标准命名、前体序列、成熟链是5p还是3p、是否有已发表文献支持。这些信息如果一开始没查清,后续靶基因预测和结果解释都容易出错。
1.2 适合哪些研究场景
miRBase数据库最常见的用途有4类。
- 查miRNA基本信息。
- 查成熟miRNA和前体miRNA序列。
- 查基因组位置和基因簇。
- 查已发表文献和外部数据库链接。
如果你正在做miRNA靶基因预测、外泌体miRNA研究或文献整理,先掌握miRBase数据库的用法,效率会明显提升。
2. 在miRBase数据库里,最先查什么信息
2.1 先确认名称和编号
进入miRBase数据库后,第一件事不是急着看靶基因,而是确认miRNA标准名称、ID和曾用名 。
同一个miRNA可能有不同写法。比如名称、别名、数据库ID并不总是完全一致。数据库页面通常会给出这些基础字段,方便你统一全文写法。
这一步很重要。因为很多论文、教程和数据库之间的命名格式不完全一样。先统一名称,后面的检索才不会跑偏。
2.2 再看stem-loop和成熟体信息
在信息页中,你会看到stem-loop sequence 和mature sequence 两类内容。前者是茎环结构前体,后者是成熟miRNA。
课程资料中提到,microRNA转录后会先形成约70到90个nt的茎环结构前体,再进一步加工成约22个nt的成熟miRNA。
对科研人员来说,这不是形式信息,而是实用信息。因为很多算法和实验设计依赖的就是前体序列或成熟序列。你要先弄清楚自己研究的是哪一层。
3. miRBase数据库如何按名字或关键词检索
3.1 关键词检索是最常用方式
在miRBase数据库首页,直接输入miRNA名称、ID,甚至部分关键词,就能检索。
例如输入hsa-mir-100,系统会直接进入对应信息页。若输入“mir-100”这类不完整关键词,可能返回多个结果,这时就需要从结果列表中逐条确认。
关键词检索的优势是快。
适合你已经知道目标miRNA名称,或者只记得部分名称的场景。
3.2 如何处理多个检索结果
如果检索结果太多,不要一条条乱点。先看结果列表里的总体描述,再看具体条目。
你可以通过以下方式提高效率:
- 先确认物种。
- 再看ID是否符合你的目标。
- 必要时按列排序,方便定位。
- 点击accession或ID进入详情页。
在miRBase数据库中,一个miRNA可能同时出现前体和成熟体条目。成熟体信息页通常更简洁,主要包含基本信息和已发表文献。前体信息页则更适合做序列和结构层面的分析。
4. miRBase数据库的信息页能看哪些关键内容
4.1 序列、位点和可信度
miRBase数据库的信息页通常会显示:
- 前体茎环结构序列。
- 成熟miRNA序列。
- 基因组中的位置。
- 序列数据的可信度。
- 支持该条目的测序数据。
其中,可信度是很值得关注的一项。页面会依据测序数据给出可信度判断,测序证据越多,可信度通常越高。对于科研选题和结果筛选,这类信息很有参考价值。
如果一个条目的实验和测序支持较弱,解读时就要更谨慎。
4.2 5p和3p代表什么
在成熟miRNA条目中,你会看到5p和3p后缀。
5p表示位于前体发夹结构靠近5’端的一条链,3p表示靠近3’端的一条链。这个命名是miRNA研究里最基础也最容易混淆的部分之一。
实际分析中,不要只看“miR-xxx”这个总称,一定要区分5p和3p。
因为它们的靶基因、表达丰度和生物学作用可能并不相同。
5. miRBase数据库如何按基因组位置、基因簇和序列检索
5.1 基因组位置检索
如果你已经知道miRNA在基因组上的位置,可以用基因组检索模式。
在Search页面选择物种、染色体编号,再输入起止位置,就能查到对应条目。
这个模式适合做定位核对,也适合和测序数据、组装结果交叉验证。对需要精确坐标的研究来说,实用性很高。
5.2 基因簇检索
miRBase数据库还支持基因簇检索。默认可按10000个碱基范围查看附近miRNA,也可以根据需求改成更小范围。
这对研究miRNA共表达、共调控和染色体区域分布很有帮助。
如果你在研究某个miRNA家族,基因簇信息尤其值得看。因为相邻miRNA并不只是“地理位置接近”,还可能提示共同转录和功能协同。
5.3 序列检索
序列检索适合你手里只有一段miRNA序列,却不知道它对应哪个条目。
你可以输入序列,选择查前体还是成熟体,再限制物种范围,最后点击Search miRNAs。
这种方法在处理测序结果、比对未知序列时很有用。尤其是在高通量数据分析中,能帮助你快速把序列和数据库条目对应起来。
6. miRBase数据库能不能直接帮助靶基因分析
6.1 它不是靶基因预测唯一工具
miRBase数据库本身更偏向信息检索和标准化查询 ,不是单独完成所有靶基因预测的工具。
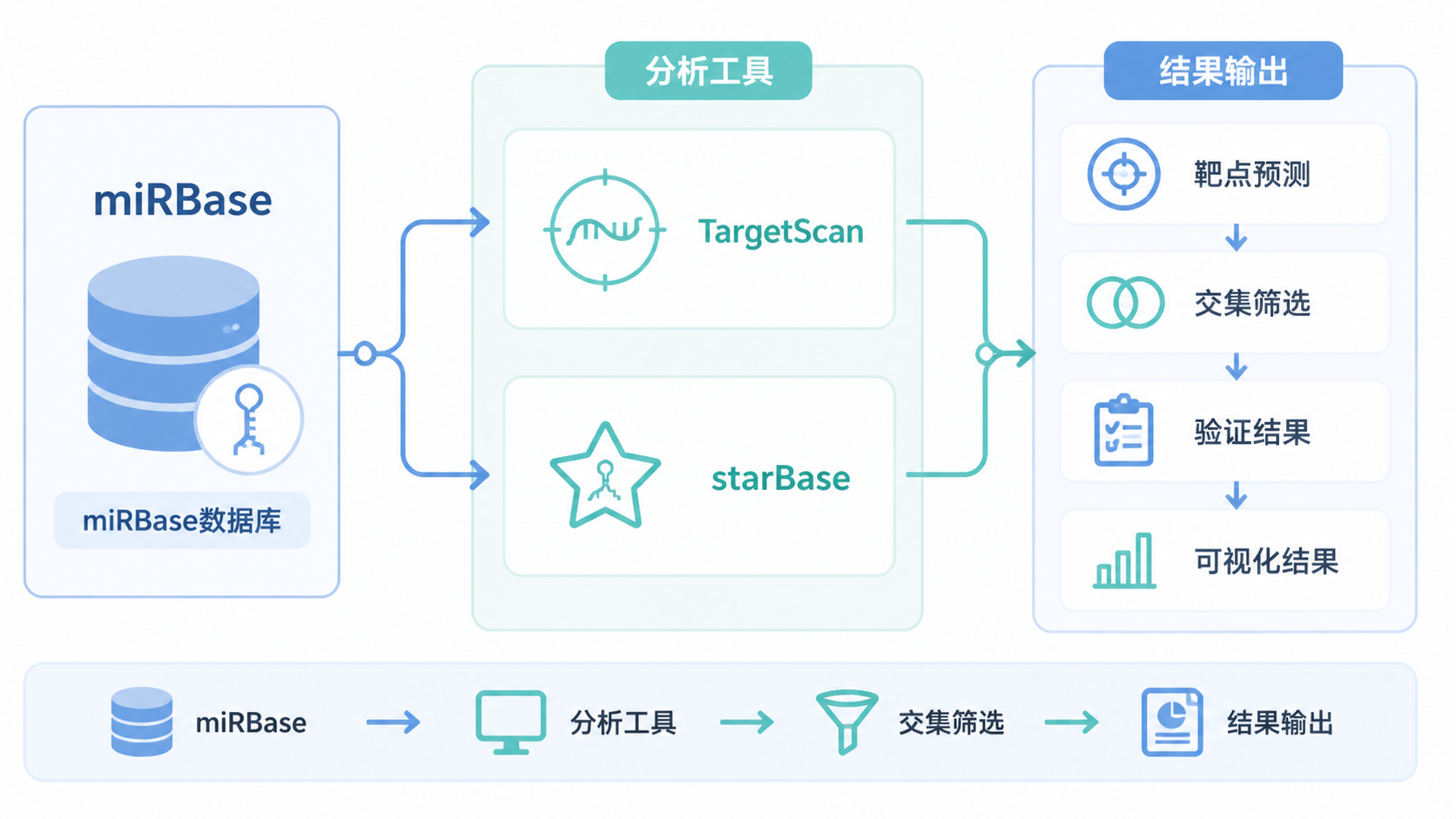
但它会在成熟miRNA信息页中提供到其他数据库的链接,也会显示相关的已验证靶基因和预测靶基因入口。你可以从这里再进入TargetScan、starBase等平台继续分析。
这意味着,miRBase数据库更像是起点,而不是终点。
先用它确认miRNA身份,再去做靶基因预测,逻辑会更稳。
6.2 研究写作时要注意引用
课程资料特别提醒,使用miRBase数据库结果发表文章时,要注意引用相关文献。
也就是说,数据库结果不是“随便截图就能写进文章”的。你需要保留来源、版本和检索路径。
对医学生、医生和科研人员来说,这是保证论文规范性和可追溯性的关键一步。
7. 实际操作时,怎样把miRBase数据库用得更高效
7.1 先统一问题,再开始检索
推荐你按这个顺序操作:
- 先确认研究对象的物种。
- 再确认miRNA名称或ID。
- 然后查前体和成熟体信息。
- 再看基因组位置、基因簇和文献。
- 最后跳转到其他数据库做靶基因分析。
这个流程虽然简单,但能显著减少重复检索和命名错误。
7.2 适合和哪些数据库联用
在miRNA研究中,miRBase数据库通常会和其他数据库联用。
比如先用它确认标准名称,再结合TargetScan、RNAhybrid或starBase看预测靶标。这样可以把“身份确认”和“功能预测”分开,分析会更清楚。
如果你做的是外泌体miRNA或靶基因相关课题,这种串联式检索尤其重要。它能帮助你减少假阳性,也能让结果解释更有依据。
7.3 解决“查到了但不会用”的痛点
很多初学者的问题不是不会打开miRBase数据库,而是不知道查到的信息该怎么接到实验和论文里 。
这正是解螺旋课程和工具的价值所在。你可以把miRBase数据库当作标准入口,再配合解螺旋的miRNA靶基因预测教程,把检索、筛选和验证串成完整路径,少走弯路。
总结Conclusion
miRBase数据库是miRNA研究的基础工具。它能帮你快速确认名称、ID、前体与成熟体序列、基因组位置、基因簇和文献证据。对做miRNA靶基因预测的人来说,先用miRBase数据库把“身份”查准,再进入功能分析,才是更稳妥的研究路线。
如果你希望把miRBase数据库和靶基因预测真正用顺,建议直接结合解螺旋的miRNA研究课程和数据库实操内容,建立一套可复用的检索流程。这样无论是写论文、做课题,还是整理数据,效率都会更高。
- 引言Introduction
- 1. miRBase数据库是什么,为什么值得先学它
- 2. 在miRBase数据库里,最先查什么信息
- 3. miRBase数据库如何按名字或关键词检索
- 4. miRBase数据库的信息页能看哪些关键内容
- 5. miRBase数据库如何按基因组位置、基因簇和序列检索
- 6. miRBase数据库能不能直接帮助靶基因分析
- 7. 实际操作时,怎样把miRBase数据库用得更高效
- 总结Conclusion