






引言Introduction
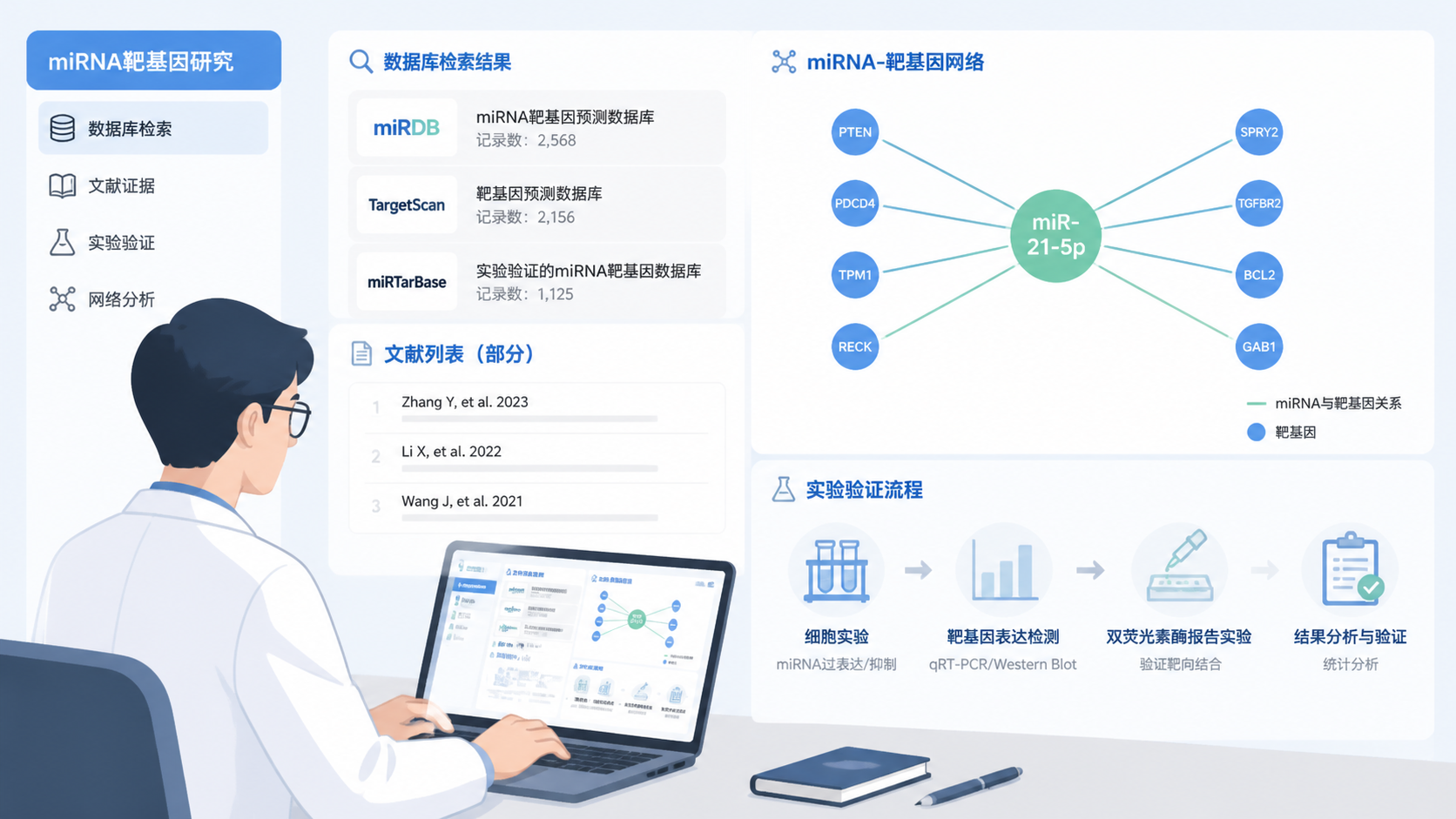
做miRNA研究,最怕靶基因预测“看起来很多,真正能用的很少”。如果你正在找mirtarbase数据库 的入门方法,这篇文章会直接帮你抓住重点:它能做什么、怎么查、结果怎么用。

1. 先弄清mirtarbase数据库是什么
1.1 它不是普通预测库,而是实验验证库
mirtarbase数据库的核心价值,在于收录了“有实验支持的miRNA-靶基因相互作用”。
这和只做计算预测的数据库不同。对于医学生、医生和科研人员来说,这意味着它更适合做机制研究、课题立项和结果佐证。
从使用场景看,mirtarbase数据库常用于三类工作。
- 验证某个miRNA是否已有已知靶基因。
- 为靶基因富集分析筛选高可信证据。
- 为文章讨论部分补充文献支持。
1.2 为什么它值得优先使用
在miRNA研究中,单纯依赖预测库容易产生假阳性。mirtarbase数据库的优势,是把“预测可能性”往前推进到了“实验确认”。
这让它在论文写作和结果解释中更有说服力。
对于转化医学研究尤其重要。因为你往往需要回答的不是“可能调控什么”,而是“已有哪条证据证明它确实调控过 ”。这正是mirtarbase数据库的长处。
2. 认识mirtarbase数据库的适用场景
2.1 适合做课题起点筛查
如果你手头只有一个miRNA名称,比如hsa-miR-100,第一步可以先用mirtarbase数据库查看它是否已经有已验证靶点。
这样能快速判断这个miRNA是否值得继续深入。
常见问题包括:
- 该miRNA是否有明确靶基因。
- 是否有多种实验方法支持。
- 是否涉及特定物种或组织背景。
2.2 适合和预测数据库联用
mirtarbase数据库最适合与TargetScan、RNAhybrid、starBase等工具联合使用。
策略很清晰。先用预测库扩大候选范围,再用mirtarbase数据库筛选已验证靶点。
这样做的好处有两个。
- 降低假阳性。
- 提高结果的可发表性和可解释性。
2.3 适合文献写作和机制讨论
在论文结果或讨论部分,很多人需要一句可靠的支持语句。
比如“该miRNA可能通过调控某靶基因参与疾病进展”。如果你能在mirtarbase数据库找到对应的实验验证记录,这句话的可信度会明显提高。
3. mirtarbase数据库怎么检索
3.1 用关键词快速查询
最直接的方法,是在mirtarbase数据库首页输入miRNA名称或靶基因名称。
例如输入miR-100或某个基因符号,就可以得到相关记录。
检索时要注意以下几点。
- 名称尽量标准化。
- 优先使用官方命名。
- 同时留意物种信息,避免跨物种混淆。
如果你查的是人类研究,建议优先确认是否为hsa开头的条目。这样能减少误读。
3.2 用结果页筛选关键信息
检索到结果后,不要只看名称。
真正要看的是证据类型、实验方法和文献来源。
通常需要重点关注:
- miRNA名称。
- 靶基因名称。
- 物种。
- 证据支持方式。
- 发表文献。
这些信息决定了你能不能把这条记录用于后续分析。特别是在写论文时,实验方法比单纯的“存在记录”更重要。
3.3 记录导出前先做一次人工核对
数据库结果可以很快,但不能完全省略人工核对。
建议你在导出前确认三件事。
- 是否为目标物种。
- 是否为你关注的实验系统。
- 是否与研究方向一致。
mirtarbase数据库能节省时间,但不能替代判断。
这是科研工作中很关键的一步。
4. 看懂mirtarbase数据库里的证据类型
4.1 实验支持是核心
mirtarbase数据库之所以重要,就在于它强调实验验证。
常见证据通常来自报告基因实验、Western blot、qPCR等研究证据。不同条目的支持强度可能不同。
做科研时不要只看“有无记录”,还要看“证据是否足够强”。
如果一个靶点只被低通量方法支持,和被多种方法重复验证,可信度显然不同。
4.2 文献来源决定可追溯性
每一条可用的mirtarbase数据库结果,最好都能追溯到原始文献。
这对你后续写作、汇报和同行交流都很重要。
建议养成一个习惯。
- 先看数据库条目。
- 再点文献。
- 最后回到原文确认实验细节。
这样能避免把二手信息直接当成最终证据。
4.3 不同条目之间可能存在重复和差异
同一个miRNA对应多个靶基因时很常见。
同一个靶基因也可能被多个miRNA调控。
这不是错误,而是miRNA调控网络本身的特点。
因此,使用mirtarbase数据库时,重点不是“找一个答案”,而是建立一个可解释的调控网络 。这也是它在组学分析中常被采用的原因。
5. 用mirtarbase数据库时最容易犯的3个错误
5.1 把预测当验证
这是最常见的误区。
mirtarbase数据库收录的是实验验证关系,不应和纯预测结果混为一谈。
如果你在写作中不区分这两类证据,容易被审稿人质疑。
5.2 忽略物种差异
人、鼠、其他模式生物的miRNA命名和验证背景并不总是完全一致。
所以检索时一定要核对物种。
尤其在转化研究中,这一步非常关键。
5.3 只看数据库,不看原文
数据库能提高效率,但不能替代原始文献。
如果你要把结果用于论文、课题申请或机制图,最好回到原文确认实验体系、样本来源和验证方法。
6. 如何把mirtarbase数据库真正用进你的课题
6.1 作为筛选候选靶点的第一步
你可以先从差异miRNA入手,再用mirtarbase数据库筛出已验证靶点。
然后结合表达数据、通路富集和临床相关性,逐层缩小范围。
一个实用流程如下:
- 获取差异miRNA。
- 用mirtarbase数据库查已验证靶点。
- 交叉比对表达变化。
- 做通路分析。
- 锁定优先验证靶点。
6.2 作为机制图的证据来源
机制图最怕“链条空”。
如果某个miRNA调控某基因的关系能在mirtarbase数据库中找到支持,你的机制图就更稳。
但要记住,数据库支持不等于你的研究结论已经成立。
它只是为你的假设提供高质量起点。
6.3 作为论文写作的引用依据
在结果或讨论中引用mirtarbase数据库,有助于提升专业性。
尤其在介绍已有研究基础时,它可以快速说明某个miRNA-靶基因关系并非空想,而是有实验记录支持。
这对提升文章可信度很有帮助。
也更符合E-E-A-T所强调的证据链表达。
总结Conclusion
如果你想快速判断一个miRNA是否已有可靠靶基因证据,mirtarbase数据库是非常值得优先掌握的工具 。它的价值在于实验验证、文献可追溯、适合与预测库联用。对医学生、医生和科研人员来说,学会用它,能明显提高课题筛选效率和论文证据质量。
如果你希望把miRNA检索、靶基因验证和数据库联用一步做对,可以进一步使用解螺旋 的科研技能课程与工具资源,减少试错时间,快速搭建更规范的分析路径。
- 引言Introduction
- 1. 先弄清mirtarbase数据库是什么
- 2. 认识mirtarbase数据库的适用场景
- 3. mirtarbase数据库怎么检索
- 4. 看懂mirtarbase数据库里的证据类型
- 5. 用mirtarbase数据库时最容易犯的3个错误
- 6. 如何把mirtarbase数据库真正用进你的课题
- 总结Conclusion



