





引言Introduction
lncRNA研究常卡在第一步,找不到可靠转录本、注释混乱、版本不一致。lncipedia数据库 正是为解决这些问题而生。它像一个人源lncRNA百科全书,适合快速查找转录本、结构、编码潜力和保守性。
1. 先理解lncipedia数据库是什么
1.1 它收录了什么
lncipedia数据库 是一个面向人源lncRNA的综合注释库。当前版本信息显示,它收录了120353条转录本,来自51382个lncRNA基因。其中,46604个基因的104489条转录本被认为可信度较高,多个预测方法均支持其不编码蛋白。
这意味着,研究者不用从零拼接多个数据库,就能先获得较完整的lncRNA基础信息。对医学生和科研人员来说,这一步很关键。它能减少重复劳动,也能降低后续分析偏差。
1.2 它适合解决什么问题
lncipedia数据库 尤其适合做以下工作。
- 快速确认某个lncRNA是否存在。
- 查看转录本编号、长度、外显子数和位置。
- 判断其蛋白编码潜力。
- 了解基因座保守性。
- 获取可直接引用的文献信息。
如果你研究XIST、HOTAIR、MALAT1这类经典分子,lncipedia数据库会比单纯检索通用数据库更高效。
2. 进入主页后先看版本和参考基因组
2.1 为什么版本选择重要
打开lncipedia数据库主页后,先确认参考基因组。网站默认使用GRCh38,也支持GRCh37。版本不同,坐标会不同。 如果论文、芯片探针或测序结果来自旧版本,必须先统一坐标体系。
lncipedia数据库在5.0版本中更新了Ensembl 90和NCBI Annotation Release 106,并删除了带ORF序列、长度小于200 nt、以及GRCh38/hg38中未注释的转录本。这说明它在质量控制上做了筛选,适合做基础注释起点。
2.2 首页信息怎么读
主页通常会展示数据总量、文献数量和工具入口。你可以先看三个点。
- 数据总量。判断数据库覆盖度。
- 文献入口。判断能否快速追溯证据。
- 下载和提交功能。判断能否进一步做批量分析。
对临床转化和机制研究来说,先看版本,再看数据来源,是使用lncipedia数据库的第一原则。
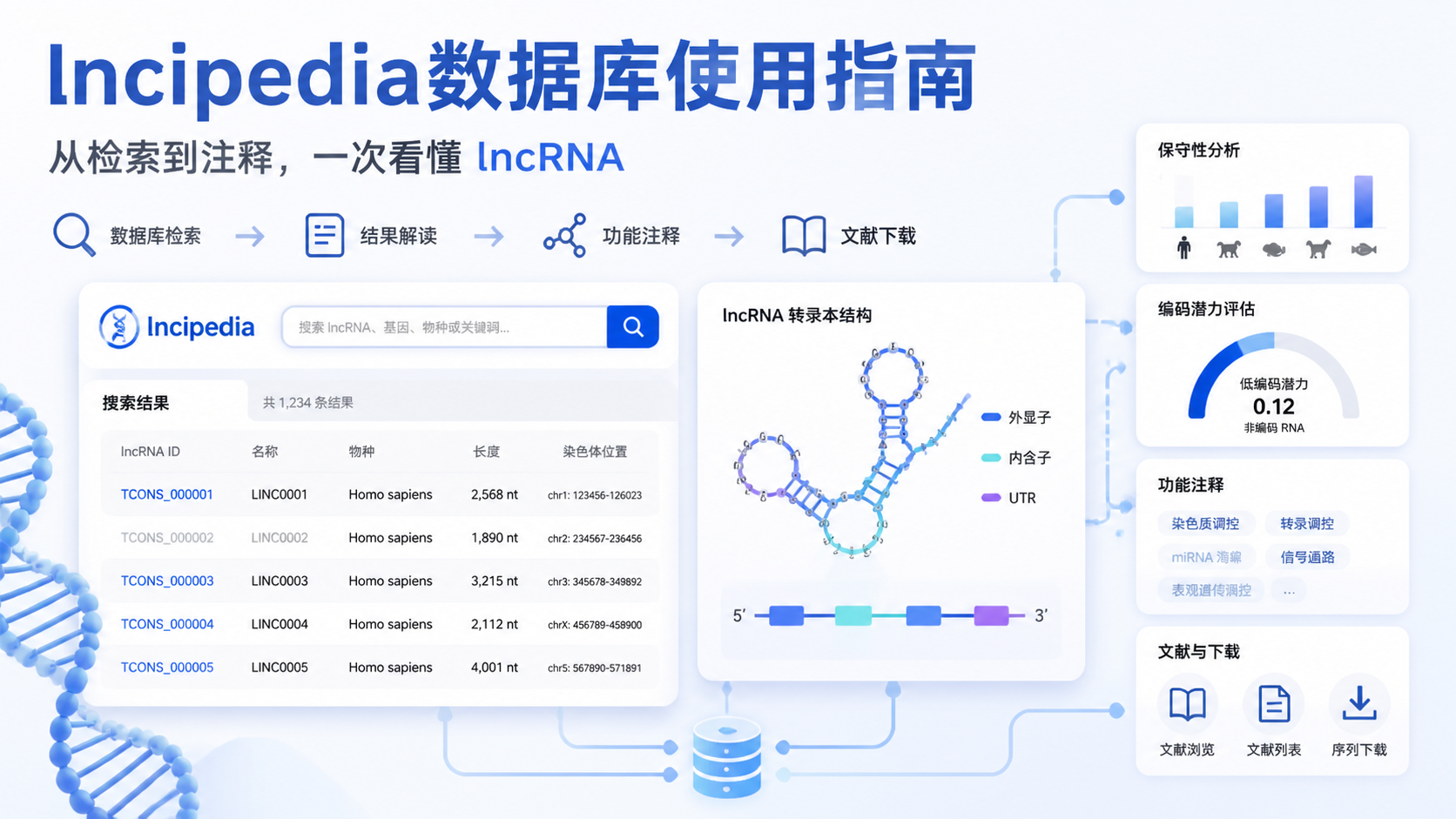
3. 用SEARCH检索目标lncRNA
3.1 支持哪些检索方式
进入检索页后,lncipedia数据库支持多种输入方式。常用的有。
- Name/ID:基因名或转录本编号。
- Source:按来源筛选。
- Chromosomal location:按染色体位置检索。
- Class:按lncRNA类型筛选。
- Abstract/title keyword(s):按关键词检索。
- Partial sequence:按序列检索。
这对实验室中信息不完整的项目非常实用。比如你只有一段引物扩增到的序列,也可以尝试反查目标转录本。
3.2 实战例子:检索XIST
以XIST为例,在lncipedia数据库中输入“XIST”后,结果可能返回多个转录本。教程显示,XIST可检索到72条结果,涉及70条XIST转录本和2条TSIX转录本。这提示我们,同名检索不等于单一转录本。
因此,检索后不要只看基因名。要继续看具体转录本编号。这样才能避免把不同剪接异构体混为一谈。在lncRNA研究中,转录本层面的准确性比基因名更重要。
4. 学会看结果列表,先抓住4个核心字段
4.1 结果页最该看的信息
结果列表中,最值得优先查看的是以下4项。
- Transcript ID:lncipedia编号。
- Gene ID:基因名。
- Location:基因组位置。
- Strand:链方向。
- transcript size:转录本长度。
这些字段能帮助你快速区分不同转录本,也能判断是否与实验设计一致。比如同一基因可能存在多个长度不同、外显子组成不同的转录本,qPCR或RNA探针设计时必须先确认目标区域。
4.2 为什么链方向很重要
链方向直接影响机制判断和实验设计。
“+”代表正义链,“-”代表反义链。对于反义lncRNA,链方向错误会导致引物设计偏离目标区域,甚至得到完全不同的扩增产物。
如果你做的是CRISPR干预、siRNA沉默或过表达构建,必须先把链方向和位置核对清楚。lncipedia数据库在这一点上非常直观。
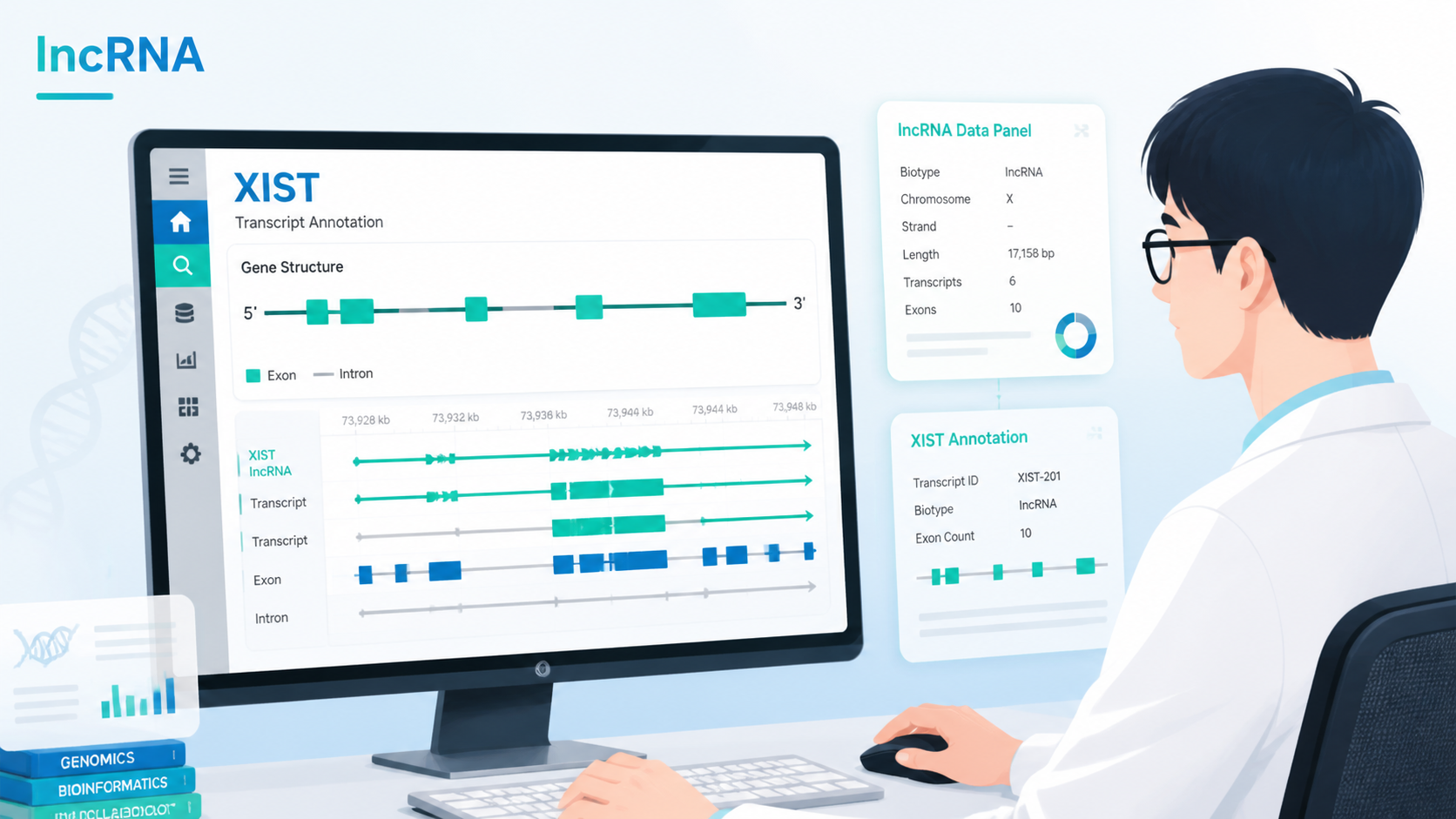
5. 打开具体转录本,看基础注释和结构
5.1 注释页包含哪些关键内容
点击某个转录本后,可以看到更完整的注释。通常包括。
- 官方简称和全称。
- 基因组位置。
- lncRNA类型。
- 转录本长度。
- 外显子数。
- 信息来源。
- 其他数据库别称。
- 序列文本框。
对于需要写基金、论文或做数据库整合的人来说,这些信息足够支撑最基础的注释描述。
5.2 结构图怎么解读
注释页还会显示转录本结构图。红色或绿色粗线代表外显子,灰色部分代表内含子,箭头表示转录方向。这个图能快速帮助你判断转录本是否具有多外显子结构,以及结构是否与已有实验设计一致。
例如,XIST:1的注释中可见其外显子数目和结构布局。对机制研究而言,这类信息能直接影响后续RACE验证、表达载体构建和剪接变体分析。
6. 看蛋白编码潜力和保守性
6.1 编码潜力怎么判断
lncipedia数据库的重要价值之一,是提供蛋白编码能力预测。它使用多种模型综合评估,并给出“严格非编码”的总体判断。这比单一算法更适合作为初筛依据。
对于lncRNA研究,这一步很关键。因为并非所有长转录本都是真正的非编码RNA。若编码潜力未排除,后续功能解释会受到影响。
6.2 基因座保守性说明什么
数据库还提供基因座保守性信息。这里说的是基因座,而不是单纯序列。它关注的是该基因及其邻近区域在不同物种中的保守情况。教程中提到,鼠类和斑马鱼等物种会按不同阈值判断是否保守。
这对进化比较和动物模型选择非常有用。
如果某个lncRNA在人类与小鼠基因座保守性较高,动物实验的可转化性通常更好。反之,如果保守性弱,就需要更谨慎地解释模型结果。
7. 利用文献、下载和提交功能完成研究闭环
7.1 文献和历史编号怎么用
在注释页里,lncipedia数据库会列出现有文献,点击即可跳转PubMed。它还会显示该转录本在不同版本中的历史编号。这对追踪旧文献和统一命名非常重要。
很多老文章使用的是旧版本编号。如果你要做综述、Meta分析或数据库整合,这个功能可以帮你避免漏检。
7.2 下载和提交适合谁
如果你需要批量分析,下载页非常实用。你可以把数据导出后,与表达矩阵、差异分析结果、富集结果做交叉整合。对于实验室团队,这一步能显著提高效率。
若你有新的lncRNA证据或相关文献,也可以通过提交功能向数据库递交信息。这体现了lncipedia数据库不仅是查询工具,也是持续更新的知识平台。
7.3 最后一步,如何把查询结果用到论文里
在真实研究中,建议按以下顺序使用lncipedia数据库。
- 先统一参考基因组版本。
- 再检索基因名或序列。
- 核对转录本编号、链方向和长度。
- 查看编码潜力。
- 判断基因座保守性。
- 追踪PubMed文献。
- 结合实验目的筛选最终目标转录本。
如果你希望把lncipedia数据库真正变成科研提效工具,而不是只停留在“查一下”,可以结合解螺旋的lncRNA数据库教程和实操课程,按标准流程完成注释、筛选和文献追踪。 这样更适合医学生、医生和科研人员做高质量选题与机制验证。
总结Conclusion
lncipedia数据库的核心价值,是把复杂的lncRNA信息变得可检索、可比较、可追溯。 掌握版本、检索方式、结果字段、注释页、编码潜力、保守性、文献追踪这7步,就能较系统地完成lncRNA基础查询。

如果你正在做lncRNA相关课题,建议把lncipedia数据库作为起点,再配合解螺旋的数据库教程与实操资源,能更快把信息检索转化为可发表的研究设计。
- 引言Introduction
- 1. 先理解lncipedia数据库是什么
- 2. 进入主页后先看版本和参考基因组
- 3. 用SEARCH检索目标lncRNA
- 4. 学会看结果列表,先抓住4个核心字段
- 5. 打开具体转录本,看基础注释和结构
- 6. 看蛋白编码潜力和保守性
- 7. 利用文献、下载和提交功能完成研究闭环
- 总结Conclusion



