引言Introduction
VCF变异信息是WES和肿瘤测序报告的核心,但很多人拿到文件后只会看“有没有突变”,不会判断“这条变异是否可信、是否有临床意义”。本文围绕VCF变异信息 ,拆解5个最关键的解读要点,帮助医学生、医生和科研人员快速建立标准化判断框架。
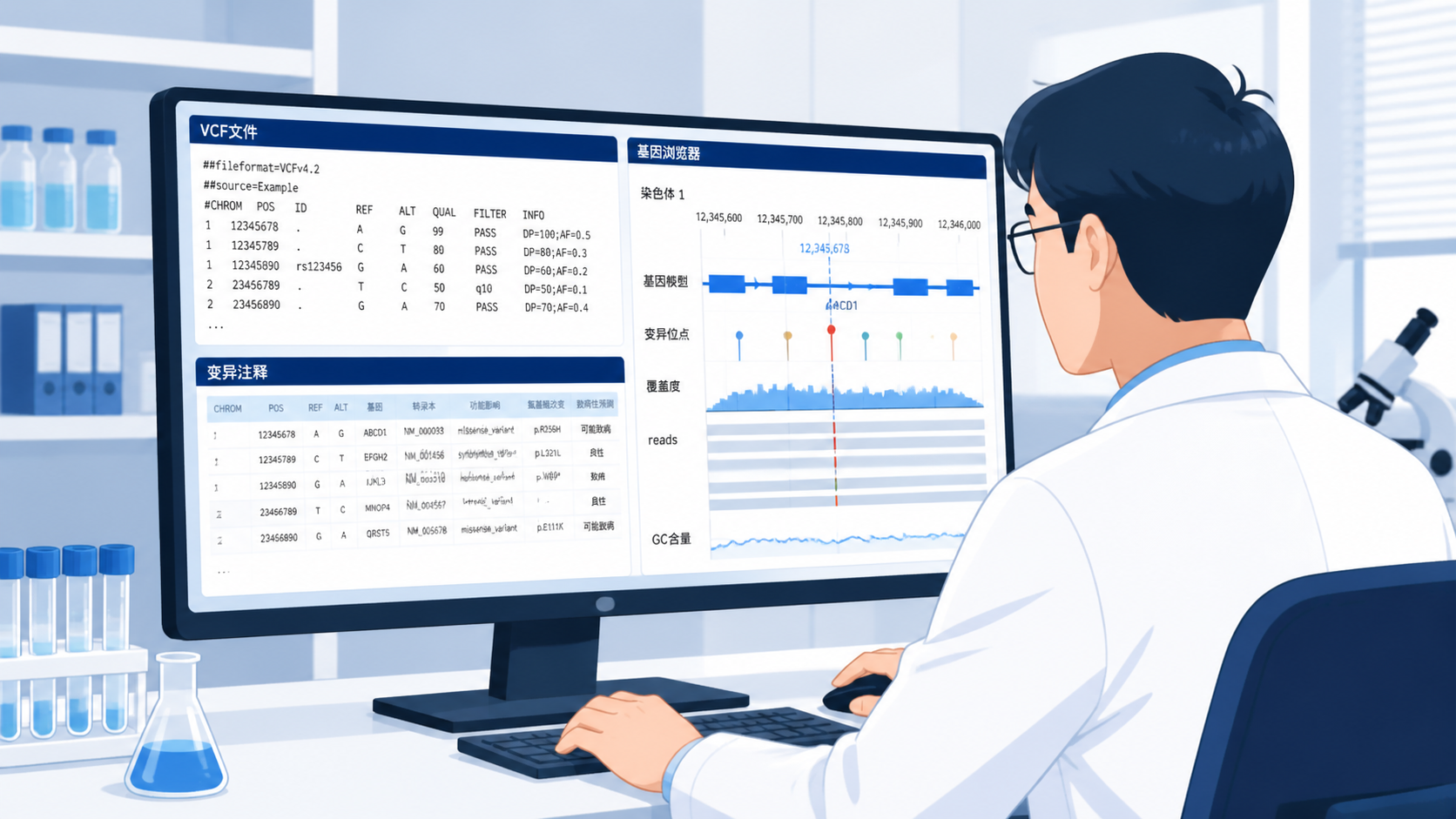
1. 先看变异是否通过质控
1.1 VCF里的PASS不是装饰字段
VCF变异信息进入报告前,首先要过质控。调用软件会给每条变异一个过滤标签。常见的就是PASS。PASS通常表示该变异满足当前软件设定的阈值,可进入后续分析。
但PASS不等于绝对真实。它只是说明这条变异在当前算法框架下“更值得保留”。
GATK等工具会结合多个指标判断真假变异,包括碱基质量、比对质量、是否靠近read边界、是否存在clustered mutations、污染信号、PCR重复相关模式,以及群体频率等。VCF变异信息的第一步,不是直接看基因名,而是先看它是否通过过滤。
1.2 关注MAPQ、覆盖度和比对率
在上游BAM质控中,覆盖度、mapping rate和MAPQ都会影响最终VCF质量。覆盖度决定某个位点是否被足够多的reads支持。mapping rate反映reads中有多少能比对到参考基因组。MAPQ则代表比对质量,区分唯一比对和多重比对。
如果这些基础指标差,后面的VCF变异信息就容易出现假阳性或漏检。尤其是肿瘤样本异质性高,低覆盖或低MAPQ会直接影响体细胞变异检出率。因此,读VCF前必须先回看上游测序质量。
2. 再看变异类型,而不是只看基因名
2.1 变异类型决定生物学含义
VCF变异信息最常见的解读误区,是只盯着基因名,不看变异类型。实际上,missense、frameshift、stop gain、splicing、synonymous等类型,对蛋白功能的影响差异很大。
例如,missense mutation可能改变一个氨基酸,但不一定损害功能。frameshift和stop gain更可能导致蛋白截短或功能丧失。在肿瘤研究中,frameshift、nonsense、splice site等更常被视为高优先级事件。
2.2 不能忽略indel和移码效应
VCF变异信息不仅包括SNV,也包括indel。若插入或缺失的碱基数不是3的倍数,就会造成移码突变。移码后,后续密码子阅读框改变,常常带来提前终止。
同一基因的不同变异类型,其临床价值可能完全不同。 比如同样落在EGFR,不同外显子、不同类型的改变,可能对应截然不同的治疗决策。因此,解读时必须同时看基因、位置和变异类型。
3. 分清胚系变异和体细胞变异
3.1 配对样本是最重要的判断依据
VCF变异信息里,最关键的一步是区分germline和somatic。胚系变异存在于机体大多数细胞,可遗传;体细胞变异则是后天获得,通常只出现在肿瘤组织中,不能遗传给后代。
在配对测序中,真正的体细胞变异应当不出现在正常样本中 。如果同一位点在正常样本也存在,就要考虑它可能是胚系变异,或者是污染、比对偏差、数据库常见多态性。
3.2 tumor-only模式要更谨慎
在没有正常对照的tumor-only模式下,VCF变异信息的判断难度更高。此时需要结合人群数据库、PON、变异丰度和已知致病证据来过滤。ClinVar、dbSNP、gnomAD等数据库都可用于辅助判断,但不能机械套用。
没有正常样本时,不能把“肿瘤里看到的变异”直接等同于“体细胞驱动突变”。 这一步是临床和科研中最容易出错的地方。
4. 看变异丰度和支持证据
4.1 变异丰度影响可信度
VCF变异信息通常会记录或推导变异丰度,也就是variant allele frequency,简称VAF。VAF并不等于肿瘤纯度,但能反映突变在测序reads中的占比。对于体细胞突变,VAF受肿瘤纯度、拷贝数变化、亚克隆结构和测序深度共同影响。
如果VAF很低,就要考虑它是否只是少数reads支持的低频事件。若支持reads少、碱基质量低、位点靠近read末端,可信度会进一步下降。因此,VAF要和深度、碱基质量、比对质量一起看,不能单独解读。
4.2 证据级别比“有无突变”更重要
在临床相关解读中,VCF变异信息最终要落到证据层面。不同变异的临床意义并不相同。
可参考的思路包括:
- 该变异是否见于ClinVar等数据库。
- 是否有明确疾病关联。
- 是否有药物敏感性或耐药性证据。
- 是否有指南、临床研究或前临床研究支持。
同一个基因,不同位点的证据等级可能完全不同。 这也是为什么变异注释和人工审核不能省略。
5. 学会把VCF变异信息转成可用结论
5.1 先注释,再筛选,再归类
原始VCF只是一份位点表。真正有价值的是把VCF变异信息变成可解释、可比较的注释结果。常用工具包括VEP、Annovar和SnpEff。它们可以把基因、转录本、氨基酸改变、功能分类、群体频率和数据库注释整合起来。
实际分析时,建议按以下顺序处理:
- 先做功能注释。
- 再做数据库过滤。
- 再看致病性和药物关联。
- 最后结合样本背景和研究目的判断。
没有注释的VCF,只是一堆坐标。 注释后,VCF变异信息才真正进入生物医学分析阶段。
5.2 结合ClinVar等数据库提高可解释性
ClinVar是NCBI维护的人类疾病相关变异数据库,适合用于变异临床意义查询。它支持按基因、RS号、蛋白改变、疾病名称和提交者搜索,也支持VCF、XML和Tab格式下载。
在实际工作中,可以先确认变异是否已被数据库收录,再看其临床意义分类。如果一条VCF变异信息能在ClinVar中找到明确记录,解读效率会明显提升。 但对于新变异、低频变异或肿瘤特异变异,仍需回到原始证据和文献。
6. 结合肿瘤场景看解读重点
6.1 体细胞变异更关注功能和治疗关联
肿瘤研究中,VCF变异信息的重点通常不是“是否遗传”,而是“是否驱动肿瘤进展”和“是否影响治疗”。因此,解读时要特别关注:
- 变异类型是否提示功能破坏。
- 突变丰度是否足以支持真实存在。
- 是否属于已知肿瘤相关基因。
- 是否有靶向治疗或耐药相关证据。
例如,BRCA1、BRCA2、TP53、EGFR、KRAS等基因,在不同癌种中都有较高关注度。但临床结论必须建立在具体位点、具体样本和具体证据之上。
6.2 报告生成要尽量标准化
在真实项目中,VCF变异信息往往还要进入自动化报告系统。因为一个WES报告可能非常长,人工整理效率低,也容易漏项。标准化流程应包括质控、变异检测、注释、证据归类和结果汇总。
这一步对科研和临床都很关键。只有把VCF变异信息结构化,结果才适合复现、审阅和转化。
总结Conclusion
VCF变异信息的解读,不是简单看见突变就下结论,而是要按顺序完成质控、类型判断、胚系与体细胞区分、丰度和证据评估,再进入临床或科研解释。对医学生、医生和科研人员来说,掌握这5个要点,能显著提高变异解读的准确性和效率。
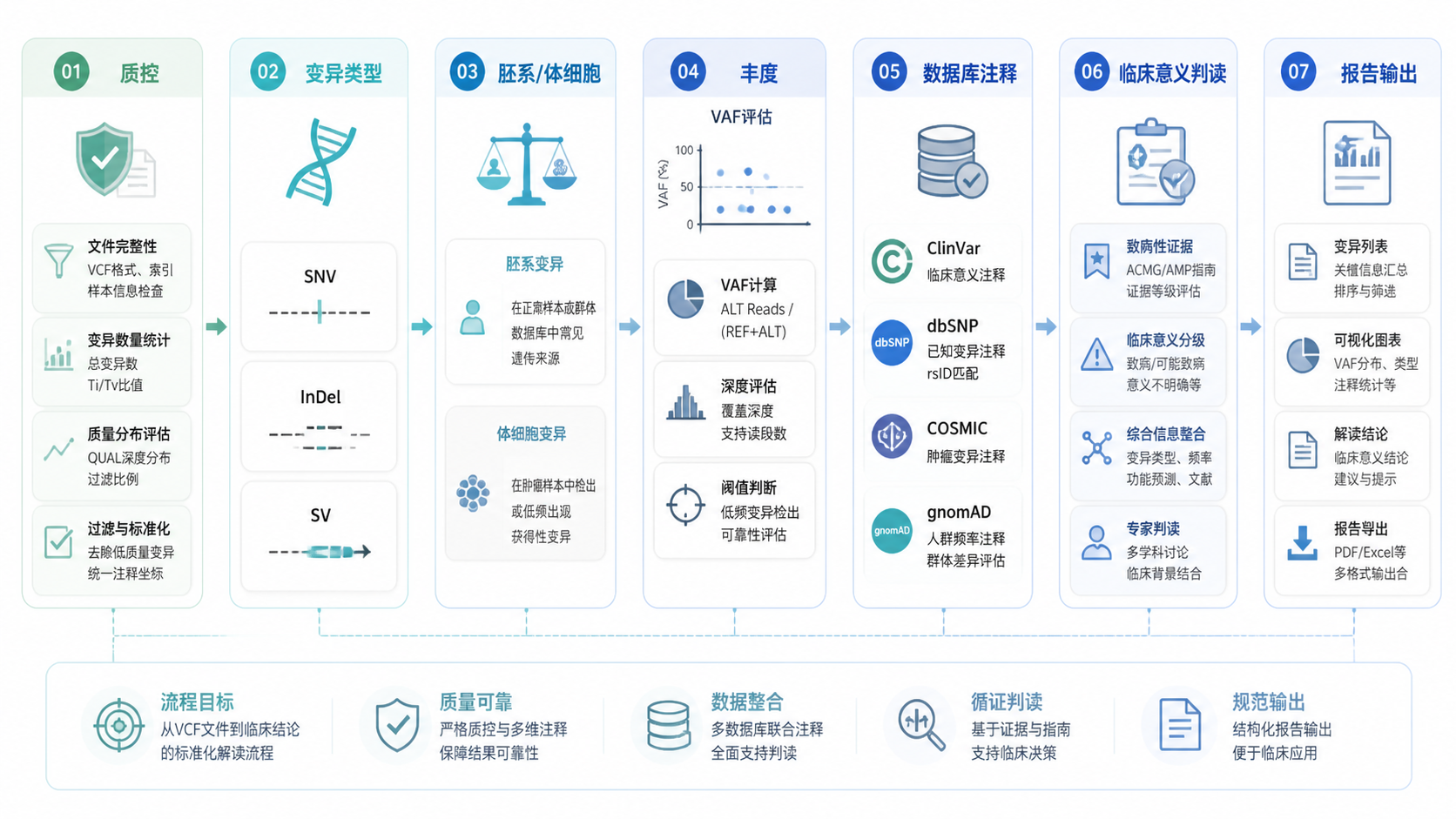
如果你希望把VCF变异信息从“看懂”升级到“高效分析和自动出报告”,可以进一步使用解螺旋 品牌的课程与工具,帮助你建立更规范的WES和变异注释流程,减少重复劳动,提高结果一致性。
- 引言Introduction
- 1. 先看变异是否通过质控
- 2. 再看变异类型,而不是只看基因名
- 3. 分清胚系变异和体细胞变异
- 4. 看变异丰度和支持证据
- 5. 学会把VCF变异信息转成可用结论
- 6. 结合肿瘤场景看解读重点
- 总结Conclusion