引言Introduction
BAM比对信息 是二代测序数据分析里最常见、也最容易被忽略的一环。很多人拿到BAM文件,只会看比对率,却不知道每一列字段代表什么,更难判断数据是否可用于后续定量、差异分析和注释。
1.BAM比对信息是什么
1.1 从SAM到BAM,先理解文件本质
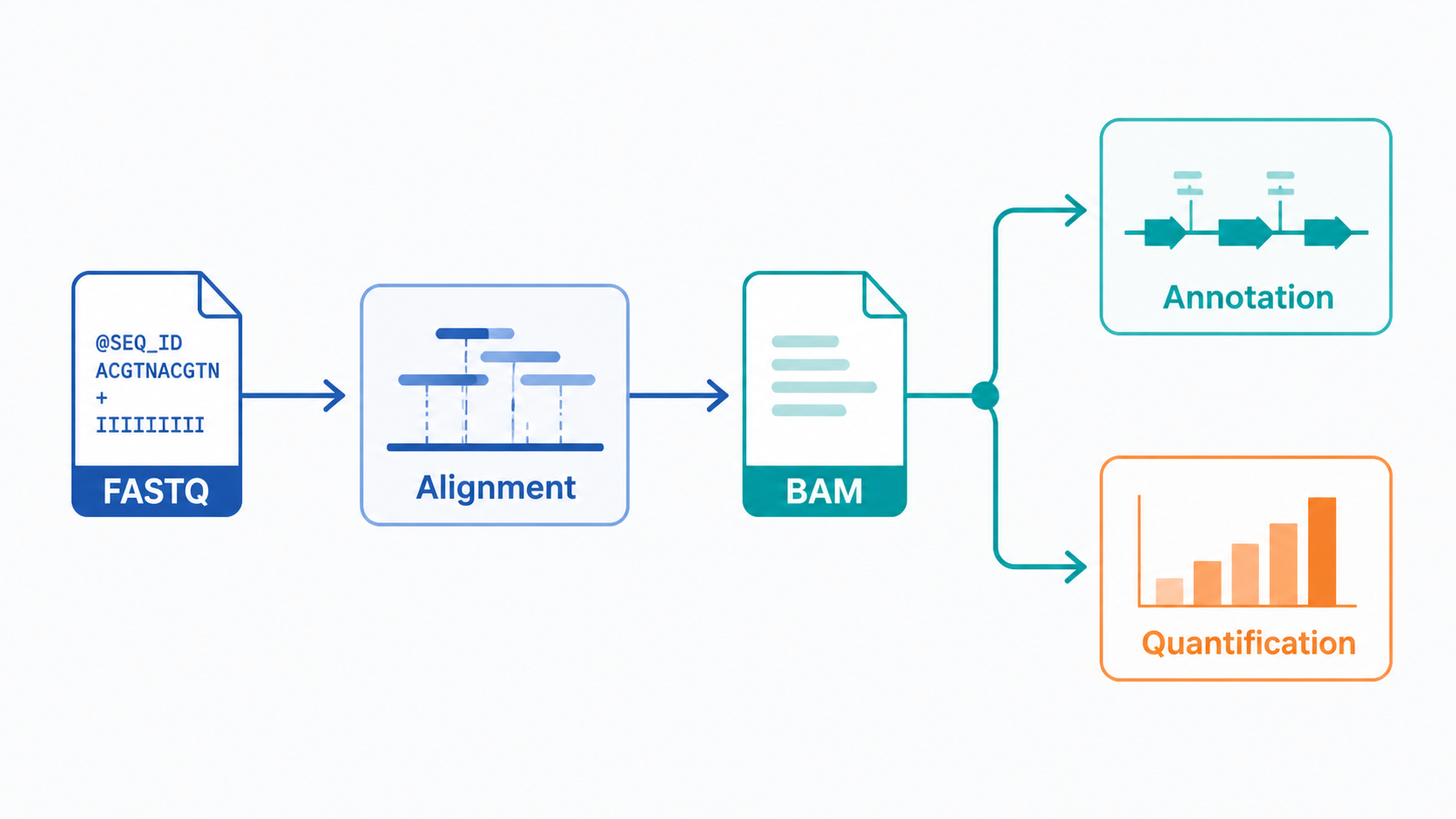
BAM文件是SAM文件的二进制压缩形式。两者都用于保存短片段序列与参考基因组的比对结果 。在高通量测序中,参考序列、比对位置、质量值和比对方式,都需要被统一记录,这就是比对信息存在的原因。
从实际分析看,BAM文件更适合存储和传输,体积更小,读取更快。很多流程先生成SAM,再转换为BAM,并按基因组位置排序。对医学生和科研人员来说,理解BAM比对信息,核心不是记住格式,而是知道这些字段如何影响下游分析结论。
1.2 为什么BAM文件是下游分析的起点
比对完成后,常见结果包括 accepted_hits.bam、sorted.bam 等文件。它们记录了哪些reads成功比对、比对到哪里、比对质量如何,以及是否存在未比对、反向比对或双端配对信息。
这些信息直接决定后续能否做:
- 基因表达定量
- 变异检测
- 转录本注释
- 重复序列去除
- 可变剪切分析
如果BAM比对信息不准确,后面的Counts、差异表达和SNP结果都会受影响。
2.BAM比对信息里最关键的字段
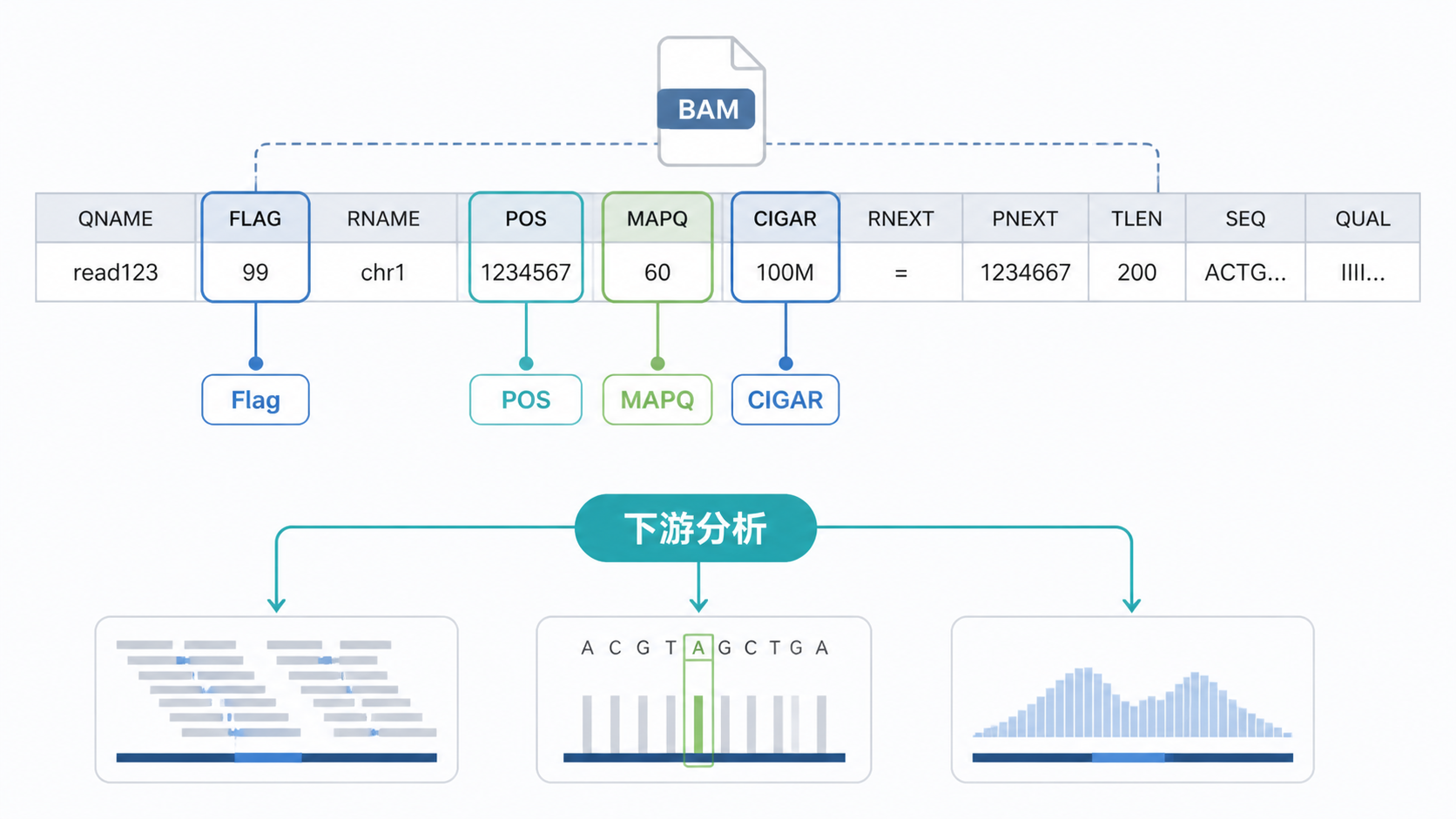
2.1 11个字段中,先抓住前8列
SAM/BAM的详细比对部分由11个Tab分隔字段组成。实际分析中,最常用的是前8列,其中Rname、POS、MAPQ、Cigar最关键 。
常见字段含义如下:
- Qname :查询序列名称,来自FASTQ中的read名。
- Flag :整数编码,表示比对状态。
- Rname :比对到的染色体或参考序列。
- POS :比对起始位置,从1开始计数。
- MAPQ :比对质量,数值越高,特异性通常越强。
- Cigar :记录比对细节,如插入、缺失、错配、剪切和拼接。
- Rnext :双端测序中,下一条read比对到的参考序列名。
- Pnext :双端测序中,下一条read比对位置。
对单端测序而言,Rnext通常为“*”,Pnext通常为0。
2.2 Flag怎么读,先看几个常见值
Flag是BAM比对信息中最容易让初学者困惑的部分。它不是一个简单编号,而是编码了多个比对属性。
常见示例如下:
- 4 :序列没有比对到参考序列
- 16 :单端序列比对到参考序列反向链
- 83 :双端序列中的第一条read,并且有特定方向信息
在真实数据里,Flag常与是否成对、是否重复、是否反向比对等状态一起出现。判断BAM比对信息是否正常,Flag是最先要核查的字段之一。
2.3 CIGAR决定了比对结构是否可靠
CIGAR记录了read如何与参考序列对齐。它包含插入、删除、错配、剪切和拼接等信息。对RNA-seq数据尤其重要,因为外显子之间存在内含子,常见的拼接比对会直接反映在CIGAR里。
如果CIGAR显示大量异常剪切、缺失或错配,需要结合MAPQ和比对软件参数进一步判断。CIGAR不是装饰字段,而是判断比对是否符合生物学预期的重要依据。
3.如何快速读懂BAM比对信息
3.1 先看比对率,再看分布
很多人拿到BAM文件后,第一步只看总体比对率。这个习惯是对的,但不够。比对率能告诉你数据是否大体可用,例如某些案例中比对率可达96%以上,说明原始数据质量较好。
但只看比对率还不够,还要继续看:
- reads是否主要集中在预期染色体
- 是否存在大量未比对reads
- MAPQ是否普遍偏低
- 是否有明显的双端配对异常
- 是否存在过多重复比对
比对率高,不等于BAM比对信息一定完全正常。
3.2 再看唯一比对和多重比对
在表达定量中,唯一比对非常重要。因为一条read如果同时落在多个基因组位置,就会增加注释歧义。HTSeq一类工具通常会优先提取唯一比对的reads,用于后续基因水平Counts统计。
这一步的逻辑很明确:
- 唯一比对,适合定量
- 多重比对,容易引入歧义
- 未比对reads,需要排查原因
对转录组分析来说,BAM比对信息不仅要“对上”,还要“对得清楚”。
3.3 排序后的BAM更适合下游处理
BAM文件在进入定量前,通常需要按基因组位置排序。排序后的文件更利于索引、可视化和后续统计。很多流程里,排序后的BAM是标准输入格式。
常见操作流程是:
- 比对生成SAM
- 转换为BAM
- 按基因组位置排序
- 必要时建立索引
- 进入定量或注释
排序不是格式性步骤,而是BAM比对信息可读、可检索、可复用的基础。
4.BAM比对信息如何服务于转录组分析
4.1 从BAM到基因表达量
在有参考基因组和GTF注释文件的前提下,BAM比对信息可以进一步用于基因表达定量。HTSeq、featureCounts、subread等工具,都是基于比对结果和注释信息,统计每个基因对应的reads数。
这里最关键的是:
- 输入必须有BAM/SAM文件
- 还需要对应的GTF注释
- 通常用于不同样品间比较
- 需要优先保留唯一比对reads
如果GTF文件设计不合理,或者包含过多可变剪切信息,HTSeq可能会把reads判为Ambiguous,影响Counts结果。所以BAM比对信息的质量,直接影响表达矩阵的可信度。
4.2 UMI数据还要考虑PCR重复
如果实验设计中加入了UMI,BAM比对信息还要结合UMI去重。因为相同UMI、相同位置的reads,很可能来自PCR扩增重复,而不是独立转录本。
常见思路是:
- 统计每个细胞、每个基因的UMI种类数
- 将相同UMI视为重复扩增的可能来源
- 去重后再做标准化和下游分析
这一步对单细胞转录组尤其重要。没有UMI校正的BAM比对信息,容易高估真实表达量。
4.3 标准化前,先确认数据结构
传统转录组常用RPKM或FPKM。单细胞和UMI数据则更强调原始Counts和后续归一化。无论哪种方法,前提都是BAM比对信息已经正确整理,并能稳定映射到基因层面。
简言之:
- 比对正确,才能注释正确
- 注释正确,才能计数正确
- 计数正确,才有资格谈差异分析
5.做BAM比对信息分析时最容易犯的错
5.1 只看软件结果,不看原始字段
很多初学者只关注比对软件输出的汇总表,却不看BAM文件本身。这样容易漏掉关键问题,比如低MAPQ、异常Flag、CIGAR结构不合理,或者未比对reads过多。
5.2 混淆单端和双端逻辑
单端测序和双端测序在Rnext、Pnext、Flag上有明显差异。单端数据不应强行按双端逻辑解释。先确认文库类型,再解读BAM比对信息,是最基本的前提。
5.3 用不合适的注释文件
BAM比对信息要进入定量,离不开GTF/GFF注释。若注释文件版本与参考基因组不匹配,结果会明显偏差。人类数据常见参考版本如hg19、hg38,必须与比对时使用的参考保持一致。
总结Conclusion
BAM比对信息本质上是测序reads与参考序列之间的“对齐记录”。它包含染色体位置、方向、质量、配对关系和比对结构等关键信息。真正决定下游结果可靠性的,不是你是否生成了BAM文件,而是你是否读懂了BAM比对信息。
对于医学生、医生和科研人员来说,建议优先掌握三点:看懂Flag,理解CIGAR,判断MAPQ和唯一比对情况。这样才能把BAM文件从“黑箱结果”变成“可解释数据”。
如果你希望把BAM比对信息进一步用于表达定量、注释和单细胞分析,解螺旋 可以帮助你把复杂流程拆成可执行步骤,减少踩坑,提高分析效率。
- 引言Introduction
- 1.BAM比对信息是什么
- 2.BAM比对信息里最关键的字段
- 3.如何快速读懂BAM比对信息
- 4.BAM比对信息如何服务于转录组分析
- 5.做BAM比对信息分析时最容易犯的错
- 总结Conclusion