引言Introduction
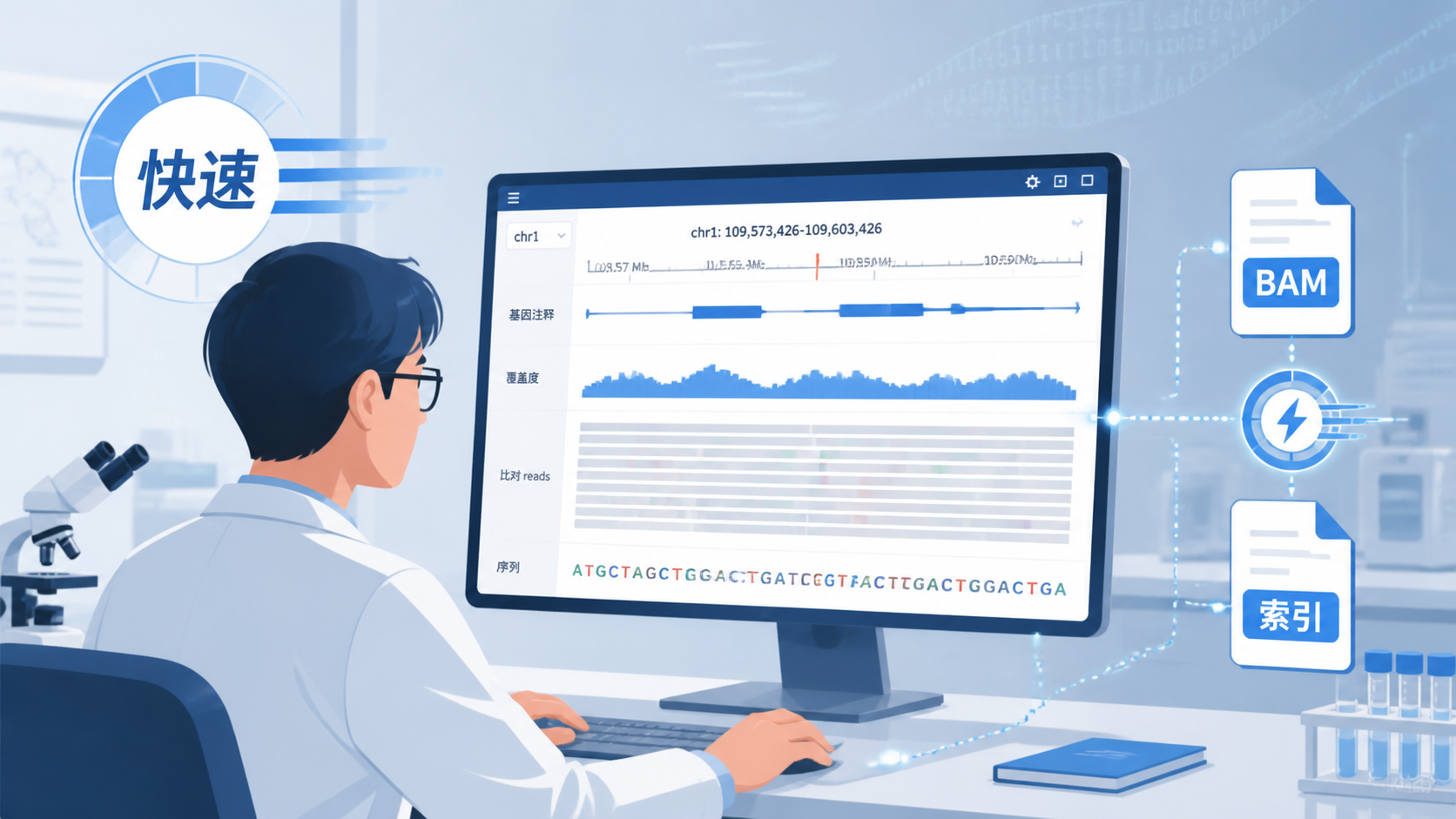
在高通量测序分析中,BAM索引 常被忽视,但它直接决定了你能否快速、精准地访问海量比对数据。没有索引,查看局部区域、提取目标片段、加载浏览器轨道都会明显变慢。对医学生、医生和科研人员来说,理解BAM索引 ,就是理解测序数据高效分析的底层逻辑。
1.BAM索引是什么,为什么必须有
1.1 BAM索引的核心作用
BAM是SAM格式的二进制压缩版本,适合存储大规模比对结果。但BAM文件本身是顺序存储的。若没有索引,系统要定位某个染色体区间,只能从头扫描到尾。BAM索引 的价值就在于建立“坐标到文件位置”的映射,让软件可以直接跳转到目标区域。
这意味着,研究者不必每次都读取整个文件。对于几十GB甚至上百GB的BAM文件,这种差异非常明显。BAM索引本质上是提升区域访问效率的关键基础设施。
1.2 常见索引文件形式
临床和科研中最常见的是 .bai 和 .csi。两者都用于支持BAM的随机访问,但适用范围不同。一般情况下,.bai足以满足大多数常规分析需求;当参考序列或坐标范围更大时,.csi更灵活。
实际工作中,索引文件必须与BAM文件对应。文件名、路径或内容不匹配,都会导致浏览器无法正常加载,或区域查询失败。这也是BAM索引管理中最容易被忽略的问题之一。
2.BAM索引为何重要
2.1 提升数据访问速度
基因组数据的典型特点是“文件大、查询细、重复访问多”。如果没有BAM索引 ,每次打开一个局部区域都要顺序遍历整份BAM,效率极低。加入索引后,IGV、samtools、bcftools 等工具可以快速跳到目标位置。
对于需要反复查看某个基因、外显子或变异位点的场景,这种加速不是“优化”,而是“刚需”。BAM索引直接影响分析流程的响应速度。
2.2 支持基因组浏览器可视化
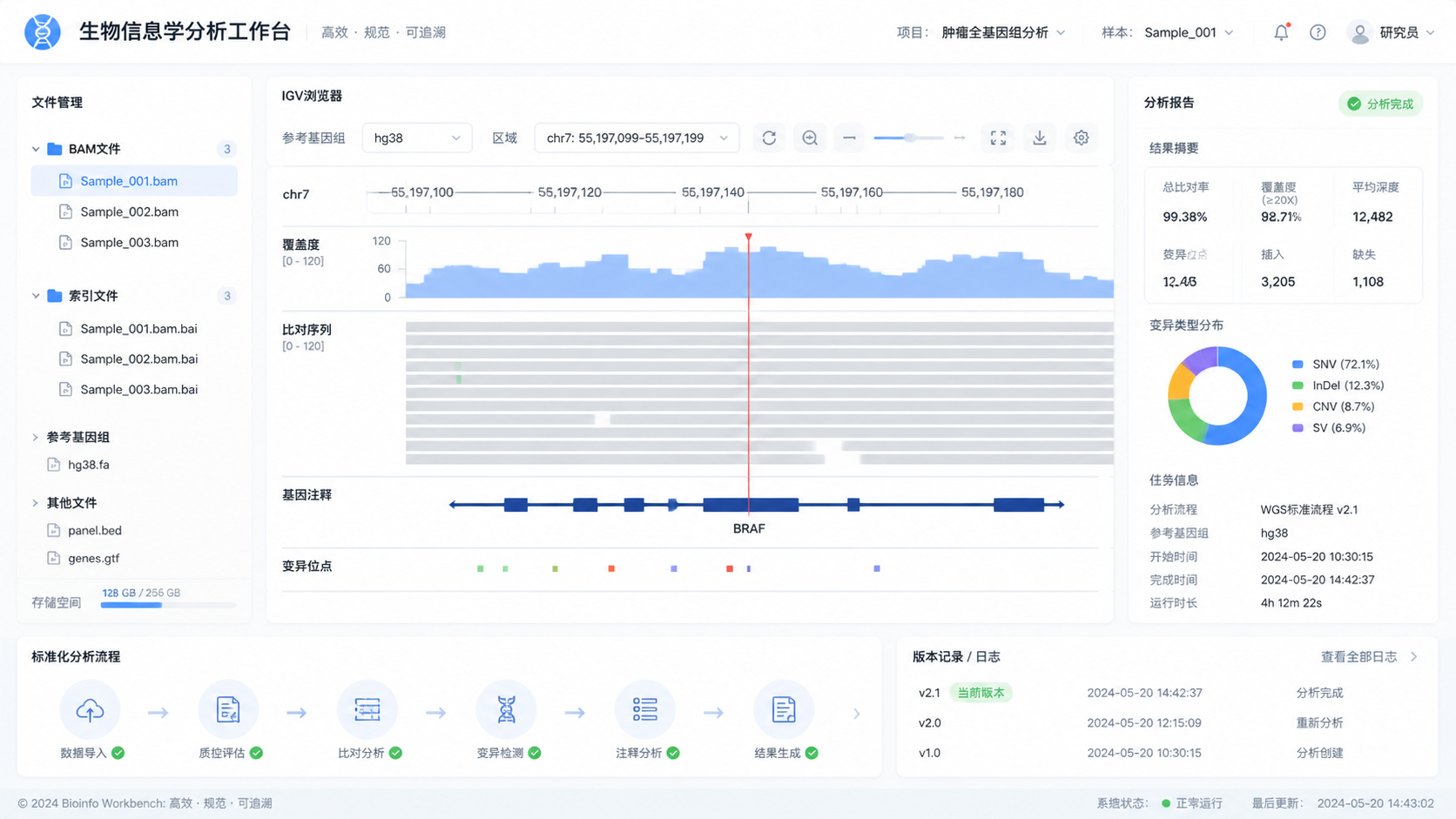
临床研究、变异验证、转录组展示中,基因组浏览器是核心工具。它依赖BAM索引 按需加载局部reads。没有索引,浏览器要么无法显示区域轨道,要么加载时间过长,严重影响交互体验。
例如,在IGV中查看某个突变位点时,系统会先读取参考信息,再根据索引定位对应BAM片段,只加载该区域内的比对结果。这使得可视化从“全量读取”变成“按需读取”。
2.3 保障下游分析流程稳定
很多下游分析都以区域访问为前提。比如查看覆盖度、验证候选变异、提取某段reads、生成局部统计图。如果没有BAM索引 ,这些操作不仅慢,还可能因内存和I/O压力而失败。
对生信流程来说,索引缺失会带来连锁问题。上游比对虽然完成了,但下游质控、展示、局部分析无法顺利展开。因此,BAM索引不是附属文件,而是流程可运行的必要条件。
3.4个关键应用场景,理解BAM索引的实际价值
3.1 场景一,快速定位目标基因区域
最常见的应用,是查看某个基因或位点附近的测序比对情况。无论是研究突变、剪接事件,还是评估覆盖深度,都会频繁用到区域查询。BAM索引让软件只读取目标区间,避免整文件扫描。
这对大队列样本尤其重要。样本一多,哪怕单次节省几秒,累计下来也是显著效率提升。对于需要批量分析的科研团队,这种优势会直接影响项目进度。
3.2 场景二,支持IGV等浏览器的局部加载
基因组浏览器的本质是“图形化的区域访问工具”。它不会把整个BAM一次性全部载入,而是依赖BAM索引 动态请求当前视窗内的数据。用户放大、拖动、切换位点时,系统都根据索引重新定位。
这也是为什么同样一个BAM文件,在不同工具里体验差异很大。是否有正确的索引,是否与参考版本匹配,都会直接影响浏览器的流畅度和结果准确性。
3.3 场景三,提取局部reads做再分析
在实际研究中,研究者常需要把某个区域的reads单独导出,进行二次比对、统计或图形展示。比如提取某个外显子附近的reads,检查是否存在错配、插入缺失或覆盖异常。BAM索引可以让这一过程直接跳转到目标区域。
如果没有索引,只能从整份BAM中筛选,速度慢且资源消耗大。对服务器环境、共享计算节点或临床时效要求高的场景,这会成为明显瓶颈。
3.4 场景四,提升临床与科研报告效率
在临床验证和科研汇报中,很多结论需要回到原始比对层面确认。比如某个变异位点是否有足够支持reads,是否存在偏倚,是否在局部区域出现异常比对。BAM索引让这类确认工作更快完成。
这不仅提高效率,也提升结论可信度。因为审阅者可以快速复核原始证据,而不是等待漫长加载。对强调可追溯性的科研和医学场景来说,这一点很重要。
4.如何正确使用BAM索引
4.1 确保BAM已排序且与索引匹配
BAM索引通常要求文件按染色体坐标排序。若BAM未排序,索引生成会失败,或者结果不可用。常见做法是先排序,再建立索引。排序是索引可用的前提。
同时,BAM和索引必须一一对应。更新了BAM却没重建索引,常会导致浏览器报错或查询异常。这个问题在批量处理时尤其常见,值得在流程中明确检查。
4.2 使用标准工具生成索引
常用工具包括 samtools index。它能快速为BAM生成可用索引。对于大多数标准流程,建议在比对完成并排序后立即生成索引,避免后续重复操作。
在自动化管线中,最好把“排序、建索引、校验”作为固定步骤。这样可以减少人工遗漏。稳定的流程设计,比事后排错更高效。
4.3 检查参考版本与坐标体系
即便BAM索引 本身正确,如果参考基因组版本不同,区域定位仍可能出错。比如 hg19 与 hg38 的坐标不一致,浏览器显示的区域就可能偏移。索引解决的是“快速定位”,不是“版本统一”。
因此,分析前要确认参考版本、染色体命名方式和坐标体系一致。对临床样本和多中心研究尤为重要。索引正确,不等于结果一定可解释。
总结Conclusion
BAM索引 是高通量测序分析中的基础能力,不只是提升速度,更关系到区域访问、可视化展示、局部提取和下游分析稳定性。对医学生、医生和科研人员而言,理解它的作用,有助于更高效地阅读测序证据,也能减少流程中常见的报错与等待。
如果你正在搭建测序分析流程,或需要更系统地理解 BAM、BAM索引、基因组浏览器和下游分析之间的关系,可以借助解螺旋品牌 提供的专业内容与工具支持,快速补齐生信实操中的关键一环。把复杂流程标准化,才能把时间用在真正的科研问题上。
- 引言Introduction
- 1.BAM索引是什么,为什么必须有
- 2.BAM索引为何重要
- 3.4个关键应用场景,理解BAM索引的实际价值
- 4.如何正确使用BAM索引
- 总结Conclusion