引言Introduction
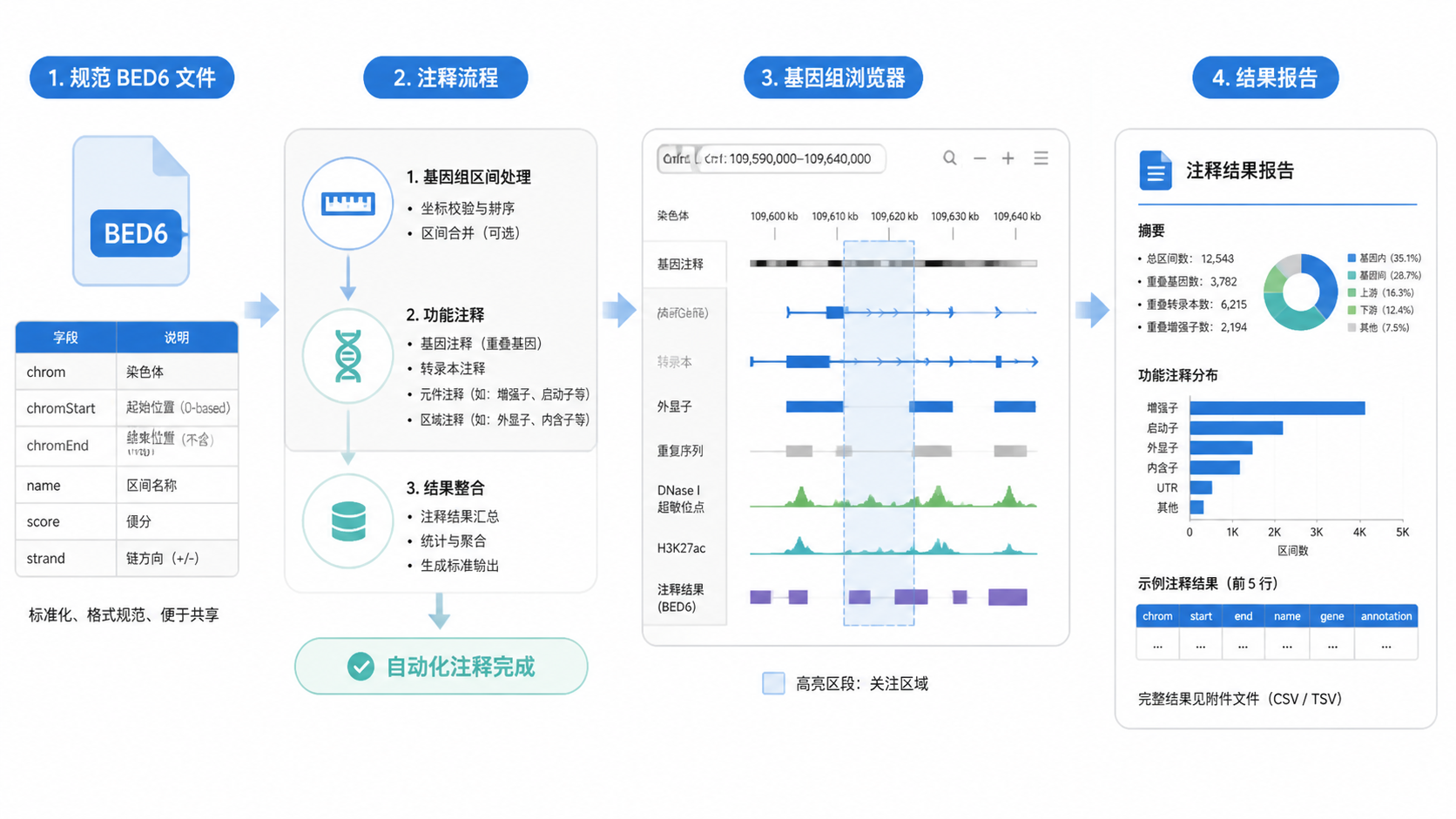
在基因组学分析中,BED6格式 常被用来记录区间、方向和注释信息,但很多人只会“写文件”,不会“用文件”。结果是坐标不统一、链信息丢失、下游分析出错。本文围绕BED6格式 应用,梳理4种高效方法,帮助医学生、医生和科研人员更快完成标准化分析。
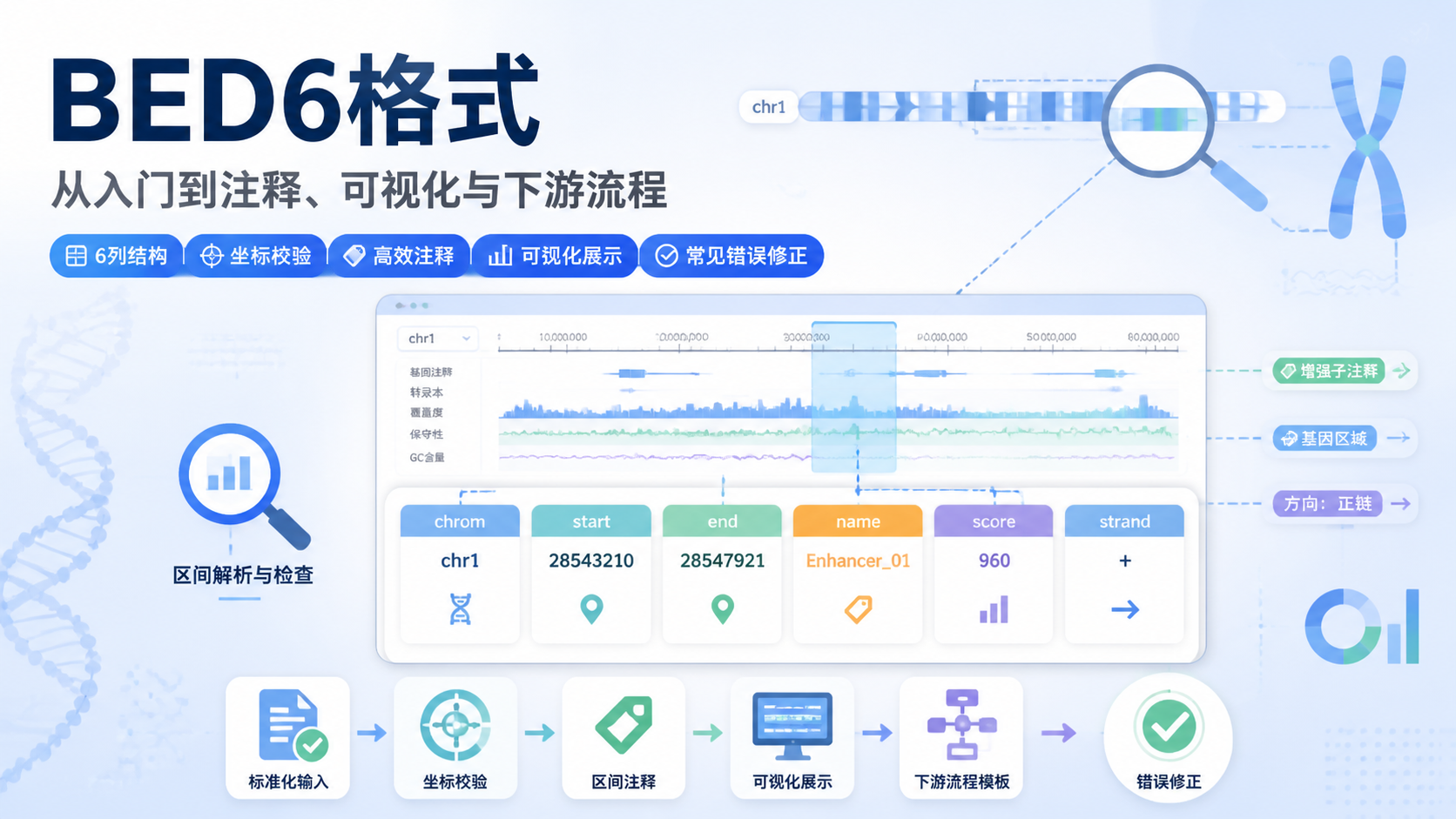
1. 先理解BED6格式的核心结构
1.1 BED6格式包含哪6列
BED6格式 是在BED基础上扩展出的6列文本格式,常用于描述基因组区间。标准6列分别是:
- chrom,染色体名称。
- chromStart,起始坐标。
- chromEnd,终止坐标。
- name,区间名称。
- score,得分。
- strand,链方向。
其中,chromStart采用0-based起点,chromEnd采用半开区间表示 。这是最容易出错的地方。很多临床和科研数据来自不同平台,如果不统一坐标体系,后续注释会偏移1个碱基。
1.2 为什么BED6格式比BED3更实用
BED3只有染色体、起点、终点,适合最基础的区间表示。
但在真实分析中,仅靠三列通常不够。BED6格式多了名称、分值和链信息,更适合表达功能区、转录本片段、峰区和引物设计结果 。
对科研人员来说,这带来两个直接好处。
第一,区间可追踪。
第二,下游工具更容易筛选和排序。
例如在转录因子结合位点分析中,链信息和名称字段都可能影响结果解释。
2. 方法一,标准化输入,先保证坐标无误
2.1 统一参考基因组版本
BED6格式 应用的第一步,不是写文件,而是确认参考基因组版本。
hg19、hg38、GRCh37、GRCh38之间存在坐标差异。若版本不一致,哪怕文件格式完全正确,结果也可能全部偏移。
建议在项目开始时固定三项信息:
- 参考基因组版本。
- 染色体命名方式,如chr1或1。
- 坐标体系,是否已转换为BED标准。
这一步看似基础,但对结果可靠性影响最大。很多“注释失败”问题,本质上不是算法问题,而是输入不规范。
2.2 检查起止坐标是否符合BED规则
BED文件要求起点小于终点,且不得使用1-based习惯直接写入。
例如,若某区域在生物学意义上是第100到200位点,转成BED6格式 时通常应写为99到200。
建议在导入前做三项检查:
- 起点是否为非负整数。
- 终点是否大于起点。
- 是否存在超出染色体长度的记录。
对大规模数据,建议先抽样核查,再批量处理。 这样能快速发现系统性错误,避免整批分析返工。
3. 方法二,借助BED6格式做高效区间注释
3.1 用name字段提高结果可读性
在区间注释中,name字段并不只是“标签”。
它可以承载基因名、峰名、转录本ID或样本编号。这样在基因组浏览器或结果表中,研究者能更快识别每条记录的生物学意义。
例如,单纯的chr坐标不利于人工阅读。
但若在BED6格式 中加入标准化名称,后续比对、筛选和展示都会更高效。
建议name字段保持统一命名规则。
如“GENE1_promoter”“peak_001”“exon_3”。
统一命名能显著减少人工核对时间。
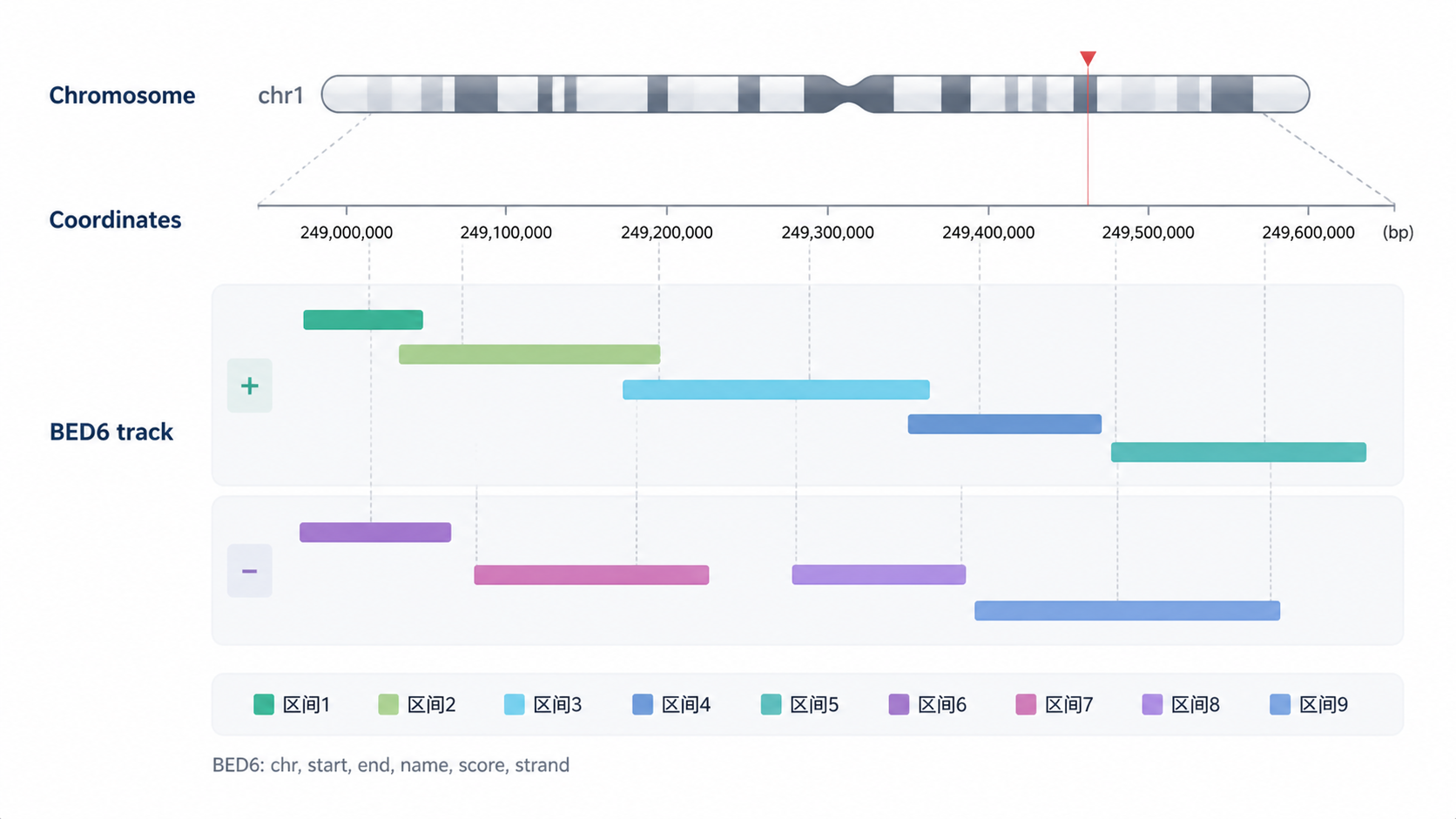
3.2 用strand字段辅助方向性分析
strand字段是BED6格式 最有价值的扩展列之一。
它支持“+”“-”方向标记,在转录组、引物设计和调控区分析中都很关键。
例如:
- 分析启动子区域时,链方向影响上游下游定义。
- 研究转录本结构时,正负链决定外显子排序。
- 做序列提取时,方向信息会影响是否需要反向互补。
如果忽略strand,很多结果只能停留在“区间存在”,无法进入“生物学解释”。
3.3 结合注释工具提升批量处理效率
在实际工作中,BED6格式 通常要与注释工具联用。
比如把区间与基因、外显子、启动子或增强子数据库匹配,再输出可解释结果。
高效做法是先准备干净的BED6文件,再进行以下步骤:
- 去除重复区间。
- 统一染色体命名。
- 按坐标排序。
- 再执行交集、覆盖率或邻近关系分析。
这样不仅提高运行效率,也能减少注释歧义。
先清洗,再注释,是提高准确率的关键。
4. 方法三,利用BED6格式进行可视化展示
4.1 在基因组浏览器中快速定位区间
BED6格式 非常适合导入基因组浏览器,如UCSC Genome Browser、IGV等。
相比纯文本表格,浏览器可以直接把区间显示为轨道,便于判断峰值分布、外显子覆盖和候选变异区域。
对医生和科研人员来说,可视化的价值在于:
- 直观看到区间是否落在目标基因附近。
- 判断多个样本的区间是否重叠。
- 检查异常峰、空白区或重复记录。
如果研究对象是临床相关基因,浏览器展示还能帮助快速沟通。
尤其在组会、论文图和项目汇报中,一张标准轨道图比一页表格更容易传达重点。
4.2 用score字段增强展示层次
score字段原本用于表示分值,但在可视化场景中,它还能帮助区分优先级。
例如可以用不同强度的颜色或高度展示高低分区间。
在BED6格式 中,score虽不是必须用于所有分析,但在可视化时很实用。
如果你有多个候选区域,可以把统计显著性、富集强度或表达变化映射到score,从而形成更清晰的图形表达。
不过要注意,score应该有明确来源,不能随意赋值。
否则会影响结果解释的可信度。
5. 方法四,围绕下游流程建立BED6格式模板
5.1 建立固定模板,减少重复劳动
很多实验室的数据管理效率低,不是因为数据少,而是因为没有模板。
对BED6格式 而言,最实用的办法是建立统一模板,把常用字段预先规范好。
模板建议包括:
- 染色体命名规则。
- 起止坐标校验规则。
- name字段命名规范。
- strand填写标准。
- score取值规则。
模板化的最大好处,是让不同人员输出的数据保持一致。
无论是实验员、分析员还是合作单位,都能按同一标准写入,减少返工。
5.2 让BED6格式服务于下游统计与复现
真正高效的分析,不只是“能跑通”,而是“可复现”。
如果输入文件长期保持同一结构,后续的统计、交叉验证和版本回溯都会更顺利。
对于科研项目,建议保留以下内容:
- 原始BED6文件。
- 清洗后的BED6文件。
- 注释脚本和参数记录。
- 参考基因组版本说明。
这套流程能显著提升结果复现率。
尤其在多中心合作或论文返修时,规范化文件会节省大量沟通成本。
6. 常见错误与修正思路
6.1 最常见的三个问题
在实际使用中,BED6格式 最常见的错误有三个:
- 坐标使用1-based。
- 染色体命名不统一。
- strand信息缺失或写错。
这些问题看似简单,但会直接影响注释结果。
如果输出中出现大量“未匹配”或“空结果”,优先检查这三项。
6.2 发现问题后如何快速修正
修正时建议按以下顺序处理:
- 先核对参考基因组版本。
- 再统一染色体前缀。
- 然后修正起止坐标。
- 最后检查strand与name字段。
不要一开始就改分析参数。
多数情况下,真正需要修正的是输入文件,而不是后续软件。
总结Conclusion
BED6格式并不复杂,但它决定了区间数据是否能被准确、稳定、可复现地使用。
无论是标准化输入、批量注释、可视化展示,还是构建下游模板,核心都在于先规范,再分析。对医学生、医生和科研人员来说,掌握BED6格式 ,意味着能更少出错、更快读图、更稳产出。
如果你希望把区间数据处理流程做得更标准、更高效,可以结合解螺旋 的专业内容与工具支持,进一步优化从文件整理到结果输出的全流程。用对方法,BED6格式就不只是文本文件,而是高质量组学分析的基础入口。
- 引言Introduction
- 1. 先理解BED6格式的核心结构
- 2. 方法一,标准化输入,先保证坐标无误
- 3. 方法二,借助BED6格式做高效区间注释
- 4. 方法三,利用BED6格式进行可视化展示
- 5. 方法四,围绕下游流程建立BED6格式模板
- 6. 常见错误与修正思路
- 总结Conclusion