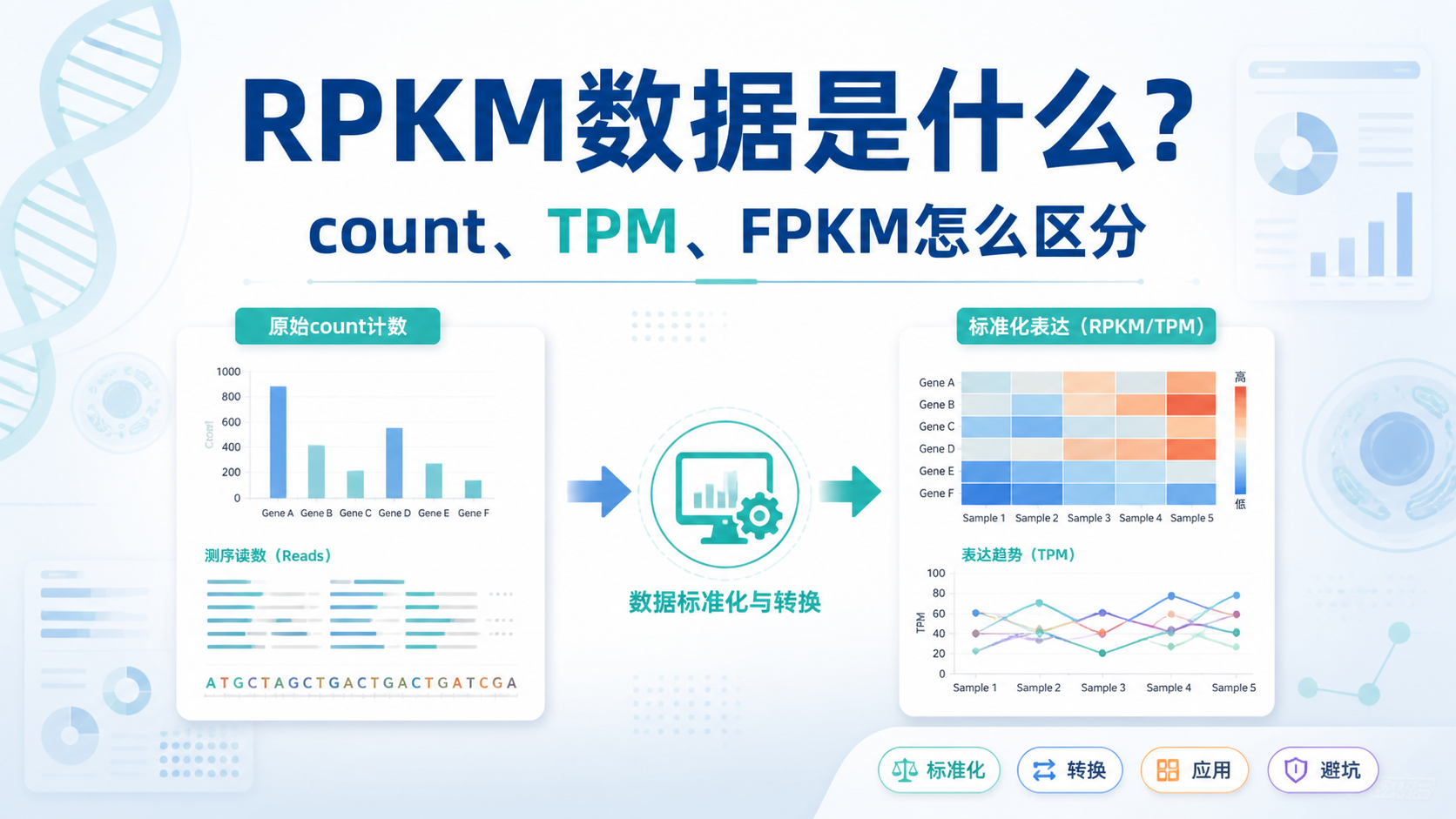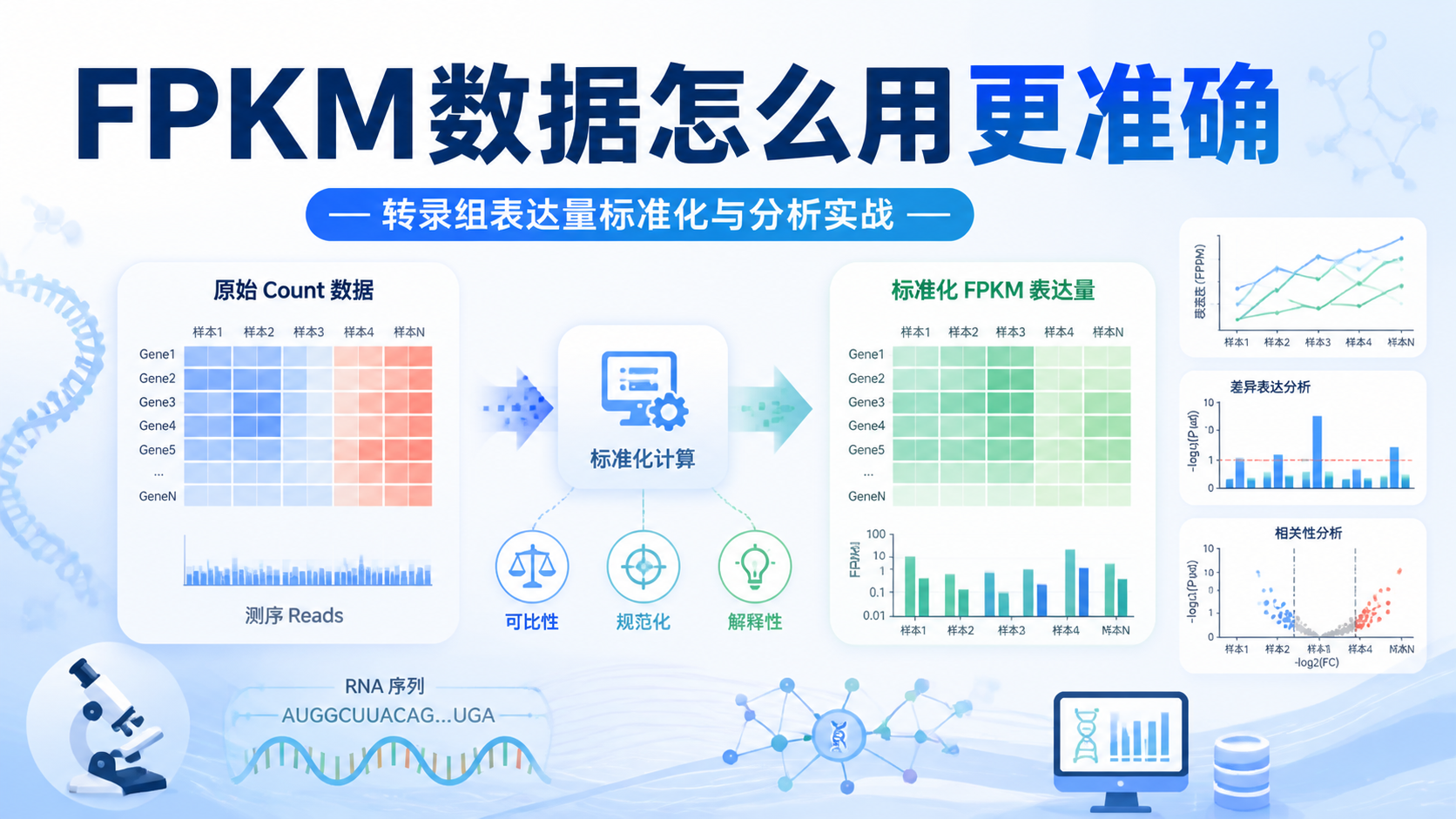
引言Introduction
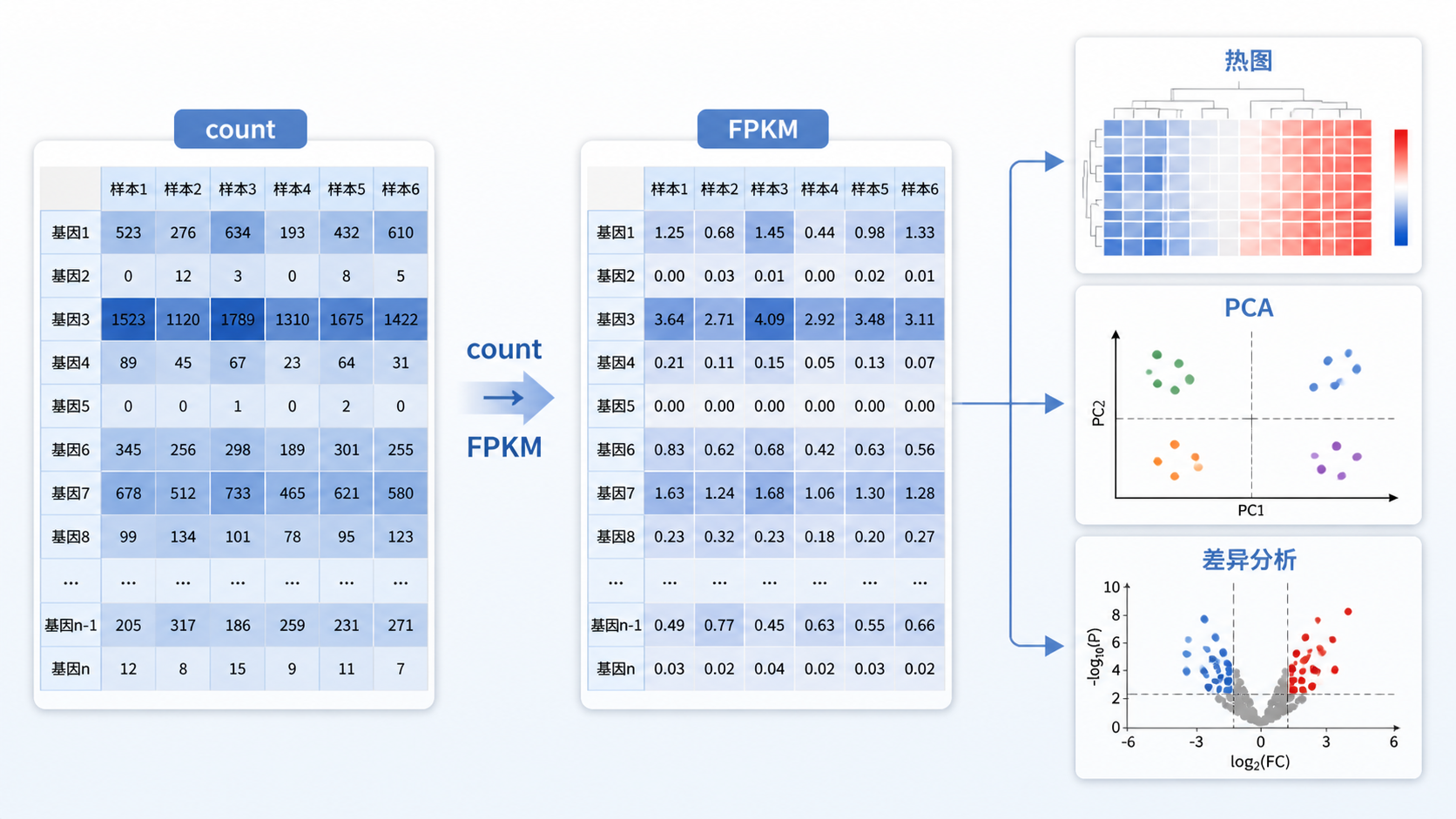
FPKM数据 常被用于转录组分析,但很多人会卡在两个问题上。第一,样本测序深度不同,结果能不能比。第二,基因长度差异很大,表达量会不会失真。要想把RNA-seq数据用对,先要理解FPKM数据的标准化逻辑。
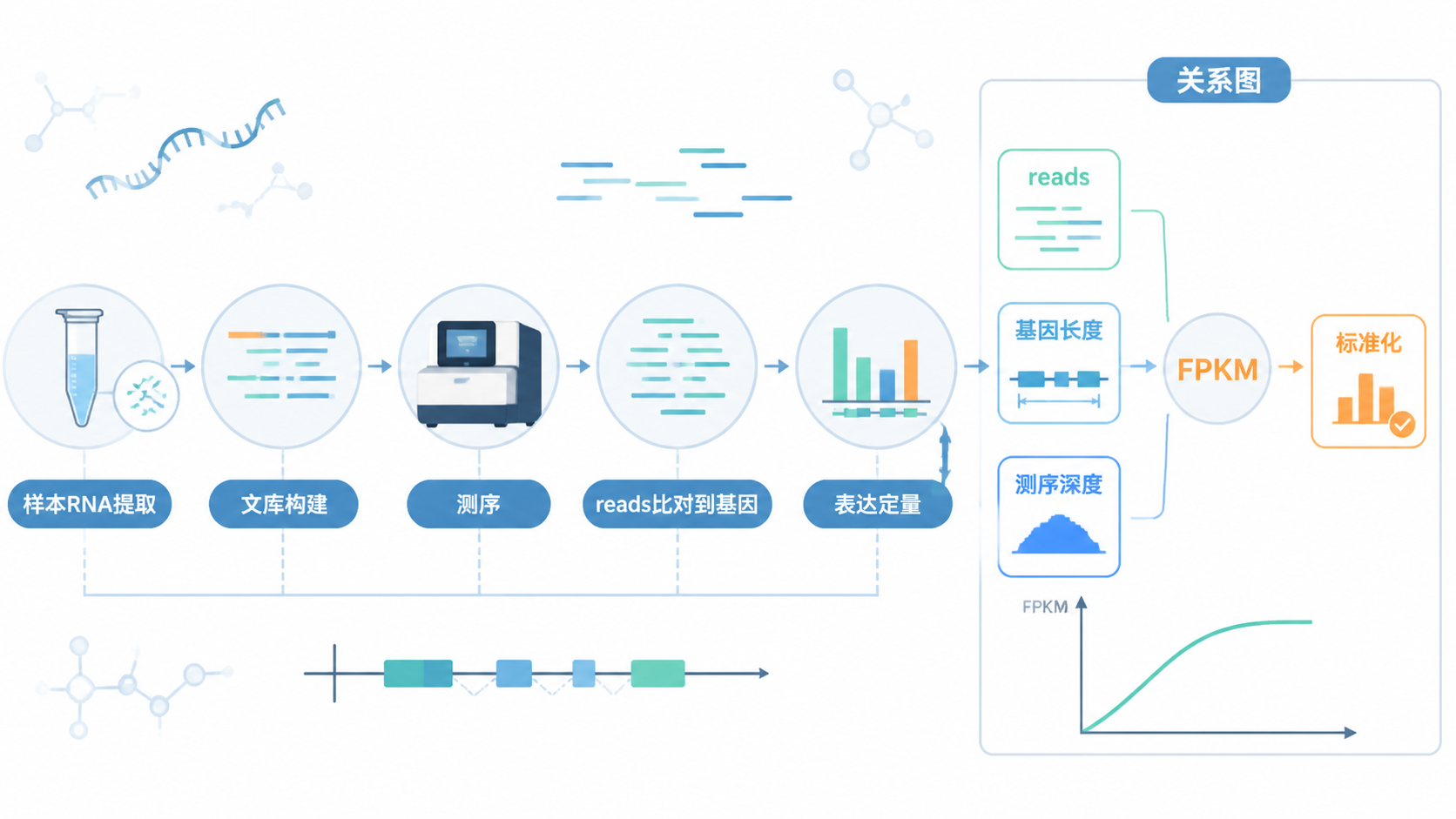
1.FPKM数据的核心作用
1.1 为什么原始count不够用
原始count只反映测到多少条reads。它没有同时修正测序深度和基因长度。
这会带来一个直接问题。长基因更容易被测到更多reads,深测序样本也会天然更高。如果直接比较count,样本之间的表达差异很容易被技术因素放大。
1.2 FPKM数据解决了什么问题
FPKM数据的核心价值,是同时消除测序深度和基因长度带来的偏差。
在转录组分析中,这一步很关键。因为只有先标准化,后面的差异表达、聚类、可视化,才更接近真实生物学差异。
从知识库给出的逻辑看,FPKM的计算顺序是先按样本总reads做标准化,再按基因长度做标准化。这样得到的值,才更适合用于样本间比较。
1.3 FPKM和RPKM、TPM的区别
FPKM和RPKM本质上是同类思路。都用于修正长度和测序深度影响。
二者在不同测序场景下叫法不同。实际分析中,主流趋势更偏向TPM,但FPKM数据依然非常常见。 知识库也明确提到,研究中不必过度纠结命名,关键是根据数据质量和分析目的选择合适指标。
2.FPKM数据如何提升分析质量
2.1 提高样本间可比性
转录组研究最常见的需求,是比较不同样本中的表达变化。
如果两个样本测序深度差异明显,原始reads不能直接比。FPKM数据把总reads和基因长度纳入标准化后,可比性会明显提高。
例如,一个样本总reads是35,另一个是106。若不标准化,结果会被测序量主导。标准化后,表达值才能更接近真实的相对丰度。
2.2 让基因表达更符合生物学解释
在基因表达分析里,长基因本来就更容易获得更多reads。
如果不修正长度,长基因会被高估,短基因会被低估。FPKM数据通过长度归一化,减少了这种系统性偏差。
这对于通路分析、候选基因筛选、表达热图展示都很重要。
2.3 便于下游分析展示
很多下游任务都希望输入的是已经标准化的表达矩阵。
例如:
- 表达热图
- PCA或聚类
- 候选基因筛选
- 共表达趋势观察
- 文献复现
在这些场景里,FPKM数据可以作为更直观的表达层级指标。 它比原始count更便于做整体判断,也更容易和已有研究结果对接。
3.FPKM数据的计算逻辑
3.1 计算顺序很关键
根据知识库,FPKM的计算可以概括为两步。
第一步,按样本总测序深度做标准化。
第二步,再按基因长度做标准化。
这也是FPKM和TPM的重要差异之一。FPKM先按样本标准化,再按基因长度标准化。
而TPM则相反,先长度归一化,再做总量归一化。
3.2 一个简化例子
假设某样本总reads为35,换算成百万级后为3.5。
某个基因测到10条reads,先除以3.5,再按基因长度修正。
如果基因长度是2 kb,标准化后的值再除以2,就得到该基因的FPKM值。
这个过程说明了一个关键点。FPKM不是简单的计数,而是“计数加权后的表达量”。
因此它更适合表达水平比较,而不是直接代表绝对拷贝数。
3.3 基因长度必须准确
知识库里特别强调了一点。
在从count转FPKM时,要先读取GTF文件,再提取外显子区间,并用reduce去除重叠部分。原因很简单。如果不去掉冗余重叠,基因长度会算错,FPKM数据也会随之偏移。
这一步对严谨分析尤其重要。
基因ID要和注释文件一致,表达矩阵和GTF文件要有交集。否则就无法正确换算。
4.FPKM数据在实战中的使用建议
4.1 什么场景适合用FPKM
FPKM数据适合用于以下场景:
- 单样本或多样本的表达概览。
- 论文复现时,和已有FPKM结果对照。
- 需要考虑长度偏差的表达展示。
- 不方便直接使用count矩阵的可视化分析。
如果你的目标是展示表达趋势,FPKM数据很实用。
4.2 什么场景不建议只用FPKM
FPKM并不是所有分析的最优输入。
对于差异表达分析,很多统计模型更偏好原始count,因为它们需要基于离散分布建模。
所以要注意:FPKM数据更适合展示和比较,不等于所有下游统计都应直接用它。
这也是专业分析里最容易混淆的地方。
表达矩阵标准化了,不代表就适合所有检验。研究设计不同,输入也应不同。
4.3 数据来源也会影响结果
知识库提到,TCGA等项目中可以直接下载FPKM或FPKM-UQ数据。
如果不想自己从count转换,也可以从UCSC Xena等数据库直接获取。
这对临床队列分析、公开数据库整合分析很方便。但前提是你要确认数据版本和标准化方式一致。
5.如何把FPKM数据用得更规范
5.1 先确认分析目的
在开始前,先问自己一个问题。你是要做差异分析,还是做表达展示。
如果是差异统计,count往往更合适。
如果是表达量比较、热图、样本概览,FPKM数据更直观。
5.2 保持注释文件一致
同一批分析中,基因注释版本必须一致。
否则,基因长度、基因ID、外显子定义都会变化。
注释文件不一致,是FPKM数据偏差的重要来源之一。
5.3 优先检查结果分布
在正式下游分析前,建议先看表达值分布。
检查是否有极端值,是否存在大量零值,是否样本间整体偏移明显。
这一步能帮助你判断数据是否适合继续分析,也能避免后面画图或聚类时出现异常。
6.FPKM数据与转录组研究的实际价值
6.1 提升结果解释性
当你需要向导师、审稿人或临床合作者解释数据时,FPKM数据往往更容易理解。
因为它已经把“测了多少”和“基因有多长”这两个问题考虑进去了。
这让表达结果更接近真实生物学差异。
6.2 便于跨样本、跨项目比较
在同类平台、相近注释版本下,FPKM数据有较好的可读性。
尤其在公开数据库整合时,它能帮助研究者快速建立初步判断。
不过仍要注意平台差异、批次效应和注释版本问题。
6.3 适合做标准化表达输出
对很多项目来说,最终交付的不只是统计结果,还有表达矩阵。
FPKM数据常被用作中间层或展示层。
它既保留了表达信息,也减少了原始count的技术噪音。这就是它在转录组分析中的实用价值。
总结Conclusion
FPKM数据提高转录组分析的关键,在于修正测序深度和基因长度偏差,从而提升样本间可比性和结果解释性。 它适合表达展示、热图、聚类和文献复现,但不应机械替代所有下游统计输入。
如果你正在处理RNA-seq数据,想把count、GTF注释、FPKM转换和下游分析串起来,可以结合解螺旋的生信内容与工具支持,减少试错成本,提高分析效率。
- 引言Introduction
- 1.FPKM数据的核心作用
- 2.FPKM数据如何提升分析质量
- 3.FPKM数据的计算逻辑
- 4.FPKM数据在实战中的使用建议
- 5.如何把FPKM数据用得更规范
- 6.FPKM数据与转录组研究的实际价值
- 总结Conclusion