引言Introduction
TPM数据怎么分析 ,是RNA-seq下游最常见的问题之一。很多人拿到矩阵后,会困惑:能不能直接做组间比较,哪些指标该看,什么时候该先做标准化。答案很明确,TPM更适合展示和探索,不等同于差异分析输入。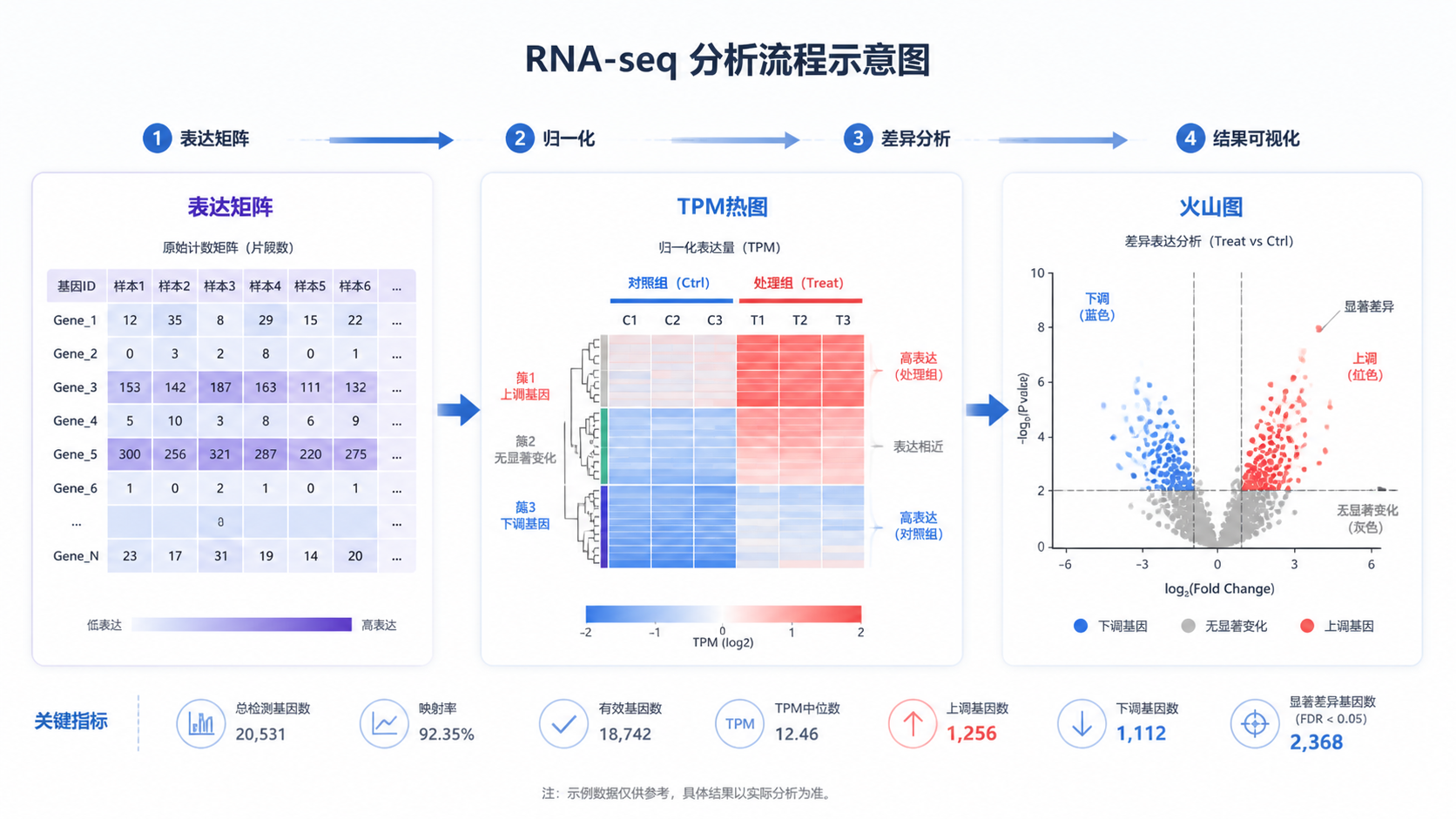
1.TPM数据是什么,适合做什么
1.1 TPM的核心定义
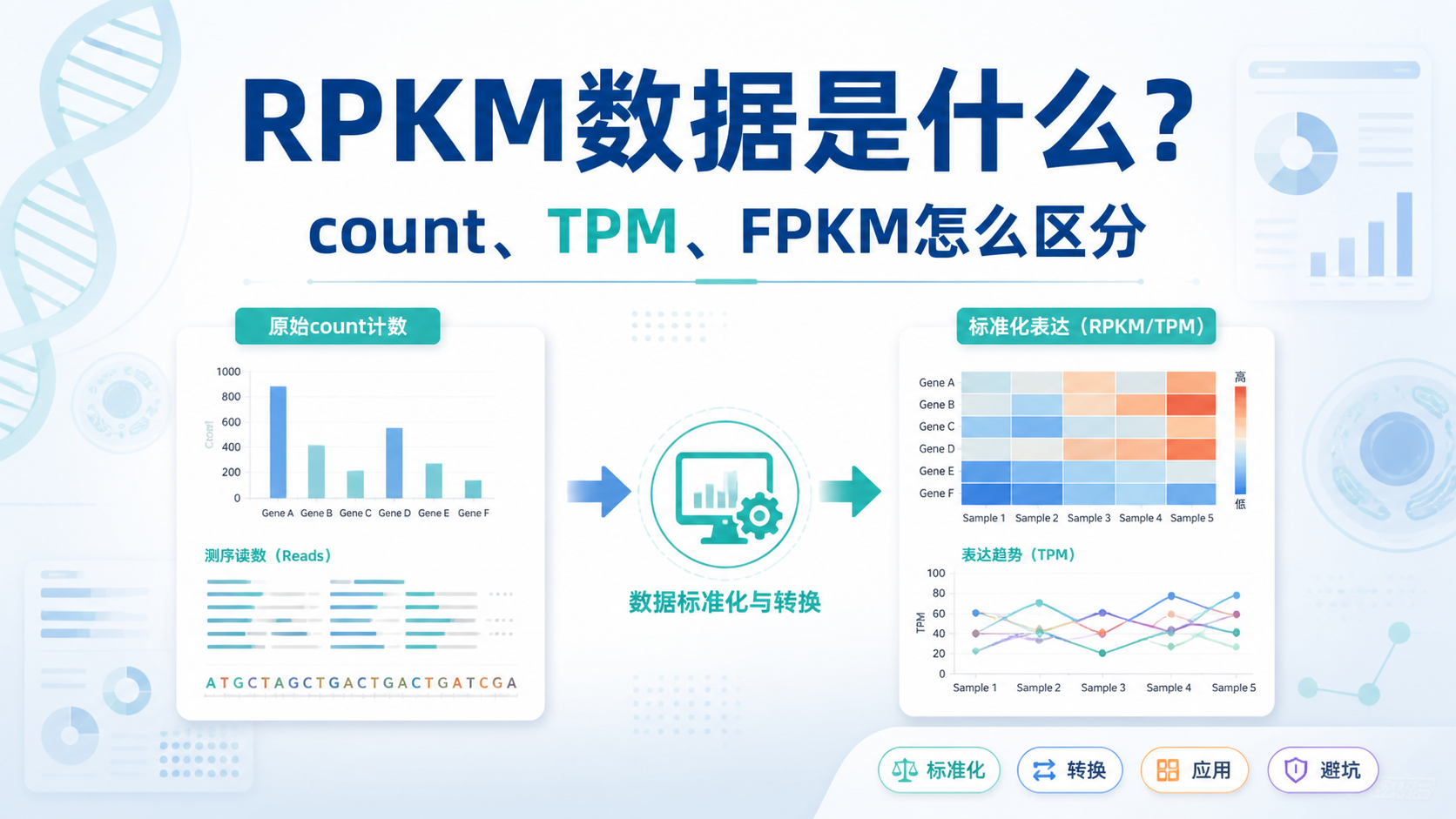
TPM,全称是 Transcripts Per Million。它的设计目的,是同时校正基因长度 和测序深度 。和COUNT相比,TPM更适合看表达占比。和FPKM相比,TPM在样本间更便于横向展示。
TPM数据的一个核心特点是,每个样本内所有基因的TPM总和固定为100万。 这让不同样本的表达谱更容易直观比较,但不代表它适合直接替代差异分析。
1.2 TPM适用场景
从实际分析看,TPM数据更适合以下场景。
- 基因表达可视化。
- 热图展示。
- 样本间整体表达谱对比。
- GSEA前的排序参考。
- 论文图表中的表达量展示。
如果你的目标是做差异分析,TPM通常不是首选输入。 DESeq2、edgeR这类工具更依赖原始COUNT数据。
1.3 为什么不建议直接用TPM做差异分析
原因很简单。TPM已经做了长度和深度的归一化,数值不再服从原始计数分布。差异分析工具需要利用COUNT数据的离散特征来估计方差。
因此,分析TPM数据时,要先分清目的。
- 看表达趋势,用TPM。
- 做统计检验,用COUNT。
- 做图表展示,常用TPM。
- 做通路排序,TPM可作为参考输入。
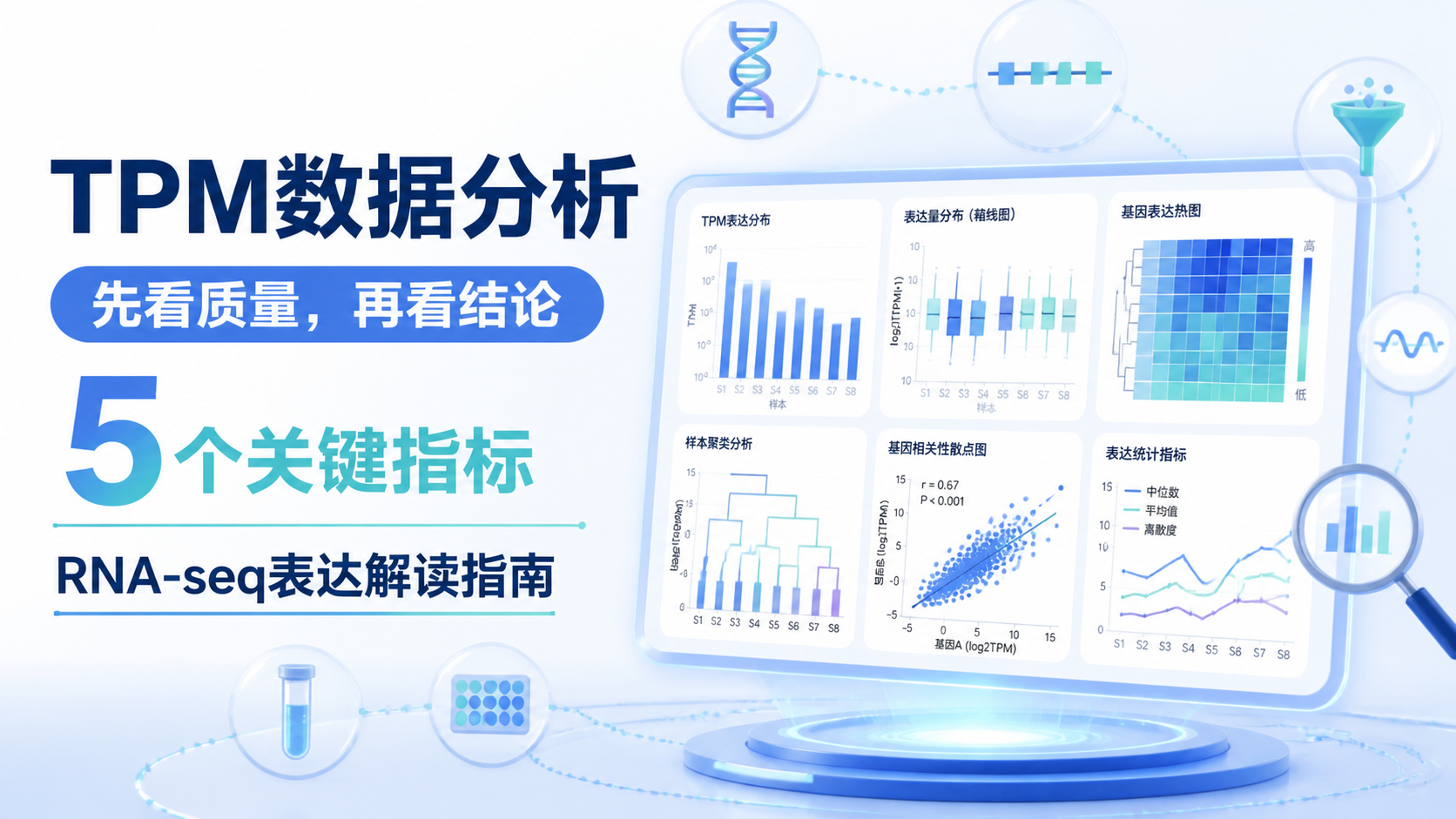
2.先看3个基础质量指标
2.1 样本内总和是否稳定
分析TPM数据时,第一步不是找差异基因,而是看样本整体是否异常。因为TPM经过标准化,每个样本的总和理论上接近100万 。如果偏差特别大,往往提示数据导入、注释或转换流程存在问题。
你可以先做这类检查。
- 查看每个样本TPM总和。
- 统计最小值、最大值和四分位数。
- 检查是否存在全零样本。
- 检查是否有明显离群样本。
2.2 基因表达分布是否合理
TPM数据通常呈现长尾分布。少数高表达基因占据较大比例,大量基因表达较低。这是正常现象,不是错误。
建议重点看三件事。
- 每个样本的表达分布。
- 高表达基因是否过于集中。
- 低表达基因是否大量为零。
如果多个样本的分布形态完全不同,就要优先排查批次效应或样本质量问题。
2.3 样本间相关性
做TPM数据分析时,样本相关性是非常实用的指标。它能快速发现重复样本、标签错误或异常样本。
常用方法包括:
- Pearson相关系数。
- Spearman相关系数。
- 样本相关性热图。
- PCA初筛。
一般来说,同组样本应有较高相关性。若组内相关性明显低于组间差异,说明样本分层、批次或生物学异质性可能很强。
3.看表达差异前,先做这2步筛选
3.1 去掉低表达基因
TPM数据分析中,低表达基因会干扰可视化和统计解释。很多基因在多数样本中接近0,这类基因对生物学结论贡献有限。
常见做法是先设定过滤规则,例如:
- 在至少一定数量样本中TPM大于1。
- 或者保留中位数TPM超过阈值的基因。
- 或者先按研究问题选择目标基因集。
过滤不是删数据,而是减少噪音,提高后续分析效率。
3.2 处理极端高表达基因
有些基因会异常高表达,可能是生物学真实信号,也可能是技术偏倚。比如核糖体相关基因、血红蛋白相关基因,常会在特定样本中占比很高。
建议先确认这类基因是否符合研究背景,再决定是否保留。不要为了“让图更好看”随意删除。E-E-A-T 视角下,可解释性永远优先于视觉效果。
4.TPM数据分析最值得看的5个关键指标
4.1 指标一,均值与中位数
均值适合看整体水平,中位数适合看典型水平。对于偏态分布明显的TPM数据,中位数往往比均值更稳健。
你可以这样理解。
- 均值高,说明整体表达水平高。
- 中位数高,说明多数基因表达都较高。
- 均值和中位数差距很大,提示分布偏斜严重。
在TPM数据中,中位数常常比均值更能代表真实情况。
4.2 指标二,变异系数
变异系数,通常用于衡量表达波动程度。它能帮助你筛出组内不稳定、组间差异明显的基因。
适合关注的情况包括:
- 同组样本内部波动小。
- 不同组之间波动大。
- 候选生物标志物优先排序。
如果一个基因在所有样本中都稳定接近同一水平,它对分组区分的价值通常有限。
4.3 指标三,组间折叠变化
虽然TPM不适合作为严格差异分析输入,但组间fold change仍然有参考意义。你可以用它先看表达趋势,判断候选基因是否值得深入。
建议关注:
- 肿瘤组相对正常组上调多少倍。
- 是否存在稳定的一致方向变化。
- 变化幅度是否足够支持后续验证。
fold change 适合做筛选,不适合单独作为统计结论。
4.4 指标四,表达覆盖率
表达覆盖率,是看一个基因在多少样本中被检测到。这个指标非常适合TPM数据,因为它能反映基因是否具有普遍表达特征。
常见解释如下。
- 覆盖率高,说明基因在多数样本中可检测。
- 覆盖率低,说明基因可能是特异表达。
- 覆盖率极低,说明它更适合作为探索对象,而不是稳定指标。
对于临床队列分析,覆盖率高的基因通常更稳健。
4.5 指标五,样本分组可分性
这是TPM数据分析中最重要的整体验证指标之一。一个好的表达矩阵,应该能让相似样本聚在一起,不同表型拉开距离。
常用方法包括:
- PCA。
- 层次聚类。
- 样本热图。
- UMAP或t-SNE,用于探索性展示。
如果分组完全分不开,先不要急着找差异基因,先检查样本注释、批次效应和过滤阈值。
5.从TPM数据到可解释结论,推荐这样做
5.1 标准分析顺序
对医学生、医生和科研人员来说,最实用的TPM数据分析流程是先探索、后筛选、再验证。
推荐顺序如下。
- 检查样本总和和分布。
- 看相关性和聚类。
- 过滤低表达基因。
- 计算均值、中位数、CV和fold change。
- 做候选基因可视化。
- 再进入实验验证或多组学整合。
这个流程能减少误判,也更符合论文写作的逻辑。
5.2 和差异分析的衔接
如果你最终目的是找差异基因,建议回到COUNT数据,用DESeq2或edgeR完成统计分析。TPM更适合作为展示层。
实际工作中常见做法是:
- COUNT用于差异分析。
- TPM用于热图和表达图。
- log2(TPM+1)用于可视化。
- GSEA前用排序值辅助展示。
这样分工更清晰,也更容易通过审稿。
5.3 结合注释信息一起看
TPM数据本身只是表达值。真正的生物学解释,离不开注释信息。比如基因功能、通路、组织特异性和疾病背景。
没有注释的TPM,只是数字。
结合注释的TPM,才是可解释的数据。
总结Conclusion
TPM数据分析的关键,不是单纯看数值,而是看分布、相关性、覆盖率和组间趋势。对于科研和临床转化场景,TPM更适合做展示、筛选和探索,差异分析仍建议回到COUNT数据。只要先判断数据质量,再提炼关键指标,结论就会更稳健。
如果你希望更高效地完成TPM数据分析、表达矩阵整理和可视化,可以使用解螺旋 的生信内容与工具支持,帮助你更快定位问题、减少重复劳动,并把结果整理到更适合发表和汇报的形式。
- 引言Introduction
- 1.TPM数据是什么,适合做什么
- 2.先看3个基础质量指标
- 3.看表达差异前,先做这2步筛选
- 4.TPM数据分析最值得看的5个关键指标
- 5.从TPM数据到可解释结论,推荐这样做
- 总结Conclusion