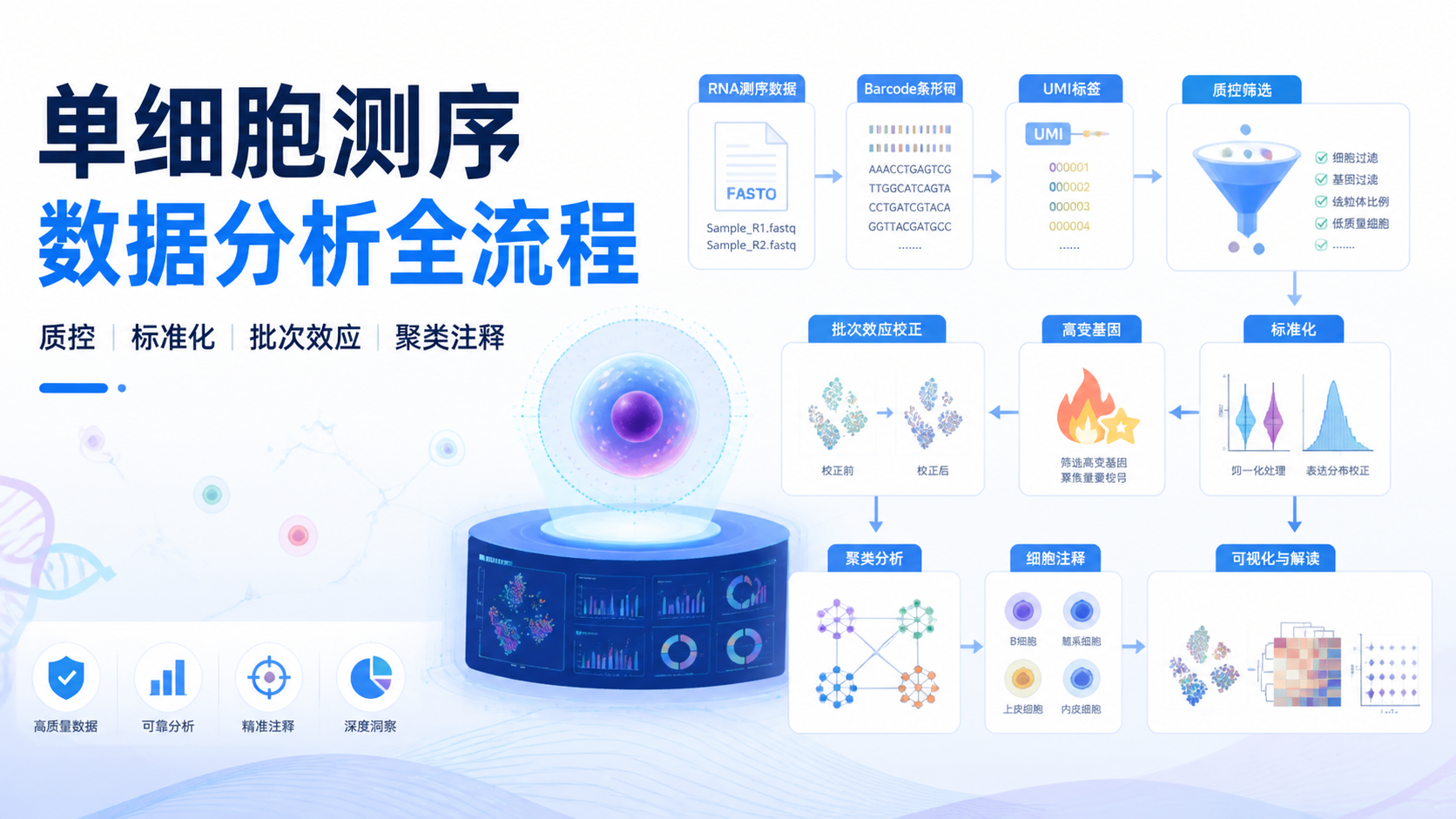
引言Introduction
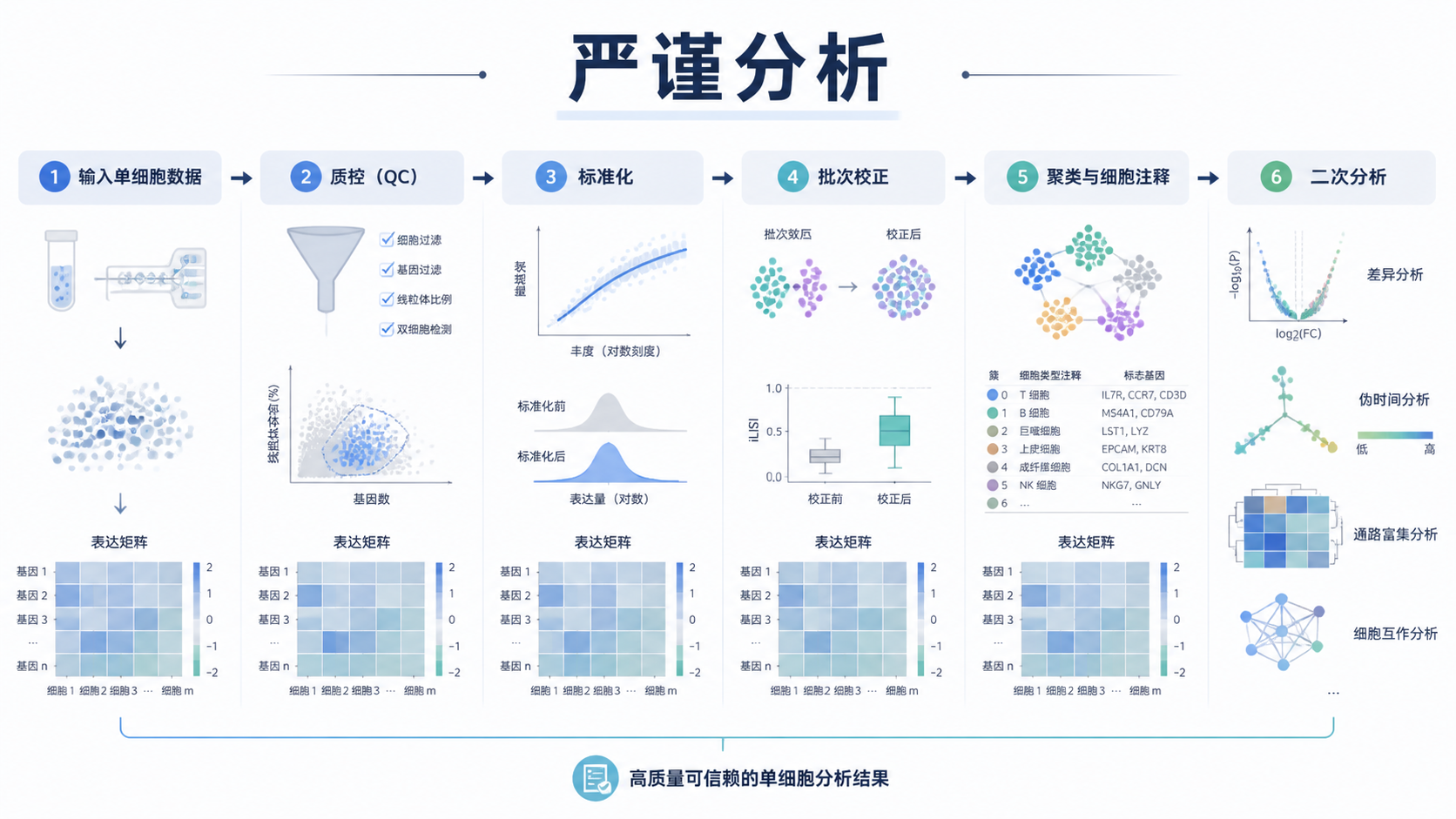
单细胞测序数据看起来只是“拿到矩阵就能分析”,但真正容易出错的,是前处理和质控。一个样本里可能混有空滴、双细胞、低质量细胞和批次效应,任何一步处理不严谨,后面的聚类和注释都会偏。想把单细胞测序数据做扎实,必须先把数据结构、清洗逻辑和分析顺序理顺。
1. 先弄清楚单细胞测序数据到底是什么
1.1 三个基础文件不能少
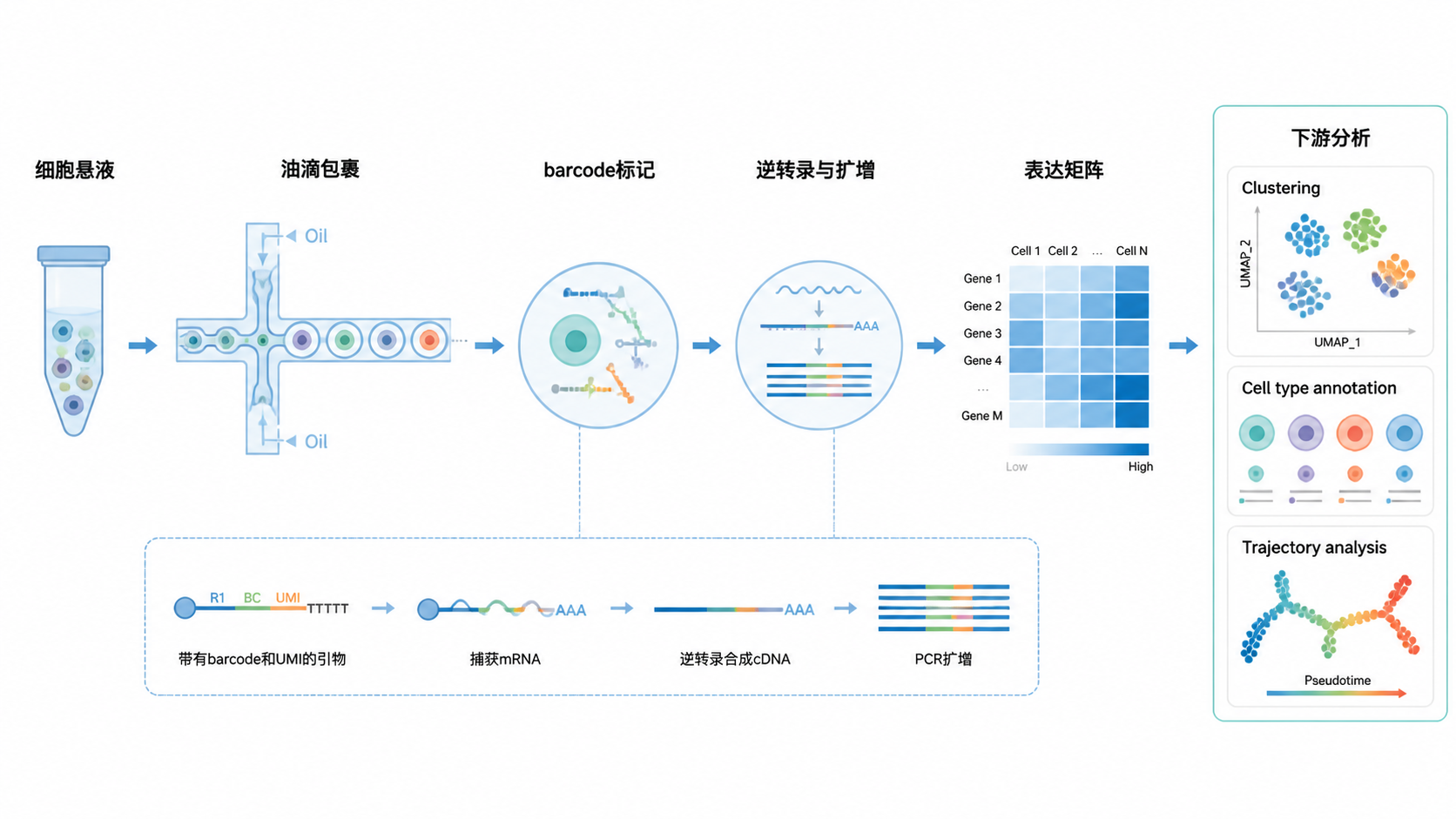
做10x单细胞下游分析时,最基础的是三类数据。第一是表达矩阵,行是基因,列是细胞 barcode。第二是基因信息表,对应基因 symbol 和 Ensembl 编号。第三是细胞信息表,初始阶段通常只有 barcode。这三类数据齐全,才谈得上后续构建 Seurat 对象和标准分析流程。
很多初学者会把单细胞测序数据和 bulk RNA-seq 混为一谈。其实两者的核心差异在于解析粒度。bulk 得到的是混合细胞的平均表达,而单细胞可以直接看到每个细胞的表达轮廓。因此,单细胞测序数据的分析目标,不只是“看谁高谁低”,而是识别细胞类型、亚群和状态。
1.2 Barcode 和 UMI 的意义
单细胞测序依赖 barcode 区分细胞,依赖 UMI 区分分子。barcode 解决“这条 reads 来自哪个细胞”,UMI 解决“这条 reads 来自哪个 RNA 分子”。如果不理解这两者,就很难理解后面为什么要去重、为什么要过滤低质量条目。
从数据角度看,barcode 是细胞身份,UMI 是分子身份。这个设计决定了单细胞测序数据天然适合做细胞级分析,但也更敏感。因为一旦前端建库或上机质量不佳,空滴、双细胞和低 RNA 含量细胞都会被带入矩阵,影响后续结果。
2. 质量控制是严谨分析的第一道门
2.1 空滴、双细胞和受损细胞都要剔除
单细胞分析中,最先要处理的是不真实或低质量信号。一个油滴可能没有细胞,读数接近 0。一个油滴也可能包裹多个细胞,导致 RNA 含量异常升高。受损细胞则常表现为线粒体比例偏高。这三类问题不处理,聚类结果很容易被假信号带偏。
常规 QC 会关注三个方向。
- 每个细胞检测到的基因数。
- 每个细胞的总 UMI 数。
- 线粒体基因比例。
这些指标不是越高越好,也不是统一阈值一刀切。 应结合样本类型、组织来源和测序深度设定。比如碎片多、应激强的组织,线粒体比例往往更高,阈值设置必须更谨慎。
2.2 过滤阈值要结合项目而不是照搬
严谨不是“过滤得越狠越好”。过滤过度会丢掉真实稀有细胞,过滤过松又会保留大量噪音。真正合理的做法,是先看分布,再定阈值,再回头检查保留细胞是否符合生物学常识。
常见做法是先画出基因数、UMI 数、线粒体比例的分布图,再根据拐点和异常尾部设定过滤标准。之后还要复查保留的细胞比例,以及不同样本间是否存在明显偏差。如果某个样本在过滤后剩余细胞数异常低,要先查技术问题,再谈生物学结论。
3. 标准化和高变基因筛选决定后续解析质量
3.1 标准化是为了让细胞可比
不同细胞的测序深度和捕获效率不一样,原始 count 不能直接比较。标准化的目的,是让表达量回到可比尺度。 这一步做不好,后面的差异分析和聚类都容易受技术噪音影响。
在单细胞分析里,标准化不是可选项,而是必经步骤。完成后,表达矩阵才能更适合做降维、聚类和 marker 筛选。对于医学生和科研人员来说,最重要的是理解:标准化不是“美化数据”,而是减少测序深度差异带来的偏差。
3.2 高变基因通常控制在 1000 到 5000 个
标准化之后,还要做 feature selection,也就是筛高变基因。高变基因通常建议保留 1000 到 5000 个,很多实际项目里 2000 到 3000 个就足够。 这不是绝对数值,但已经是较常见、较稳妥的范围。
为什么不能无限增多?因为太多基因会引入更多噪音,也会增加计算负担。为什么不能太少?因为信息不足会让聚类不稳定。严谨的做法,是在保证信息量的前提下控制特征维度。 对常规项目而言,3000 个左右往往是一个平衡点。
4. 批次效应和协变量处理决定结果是否可信
4.1 多样本分析必须考虑批次
单细胞研究很少只看一个样本。无论是实验组和对照组,还是不同时间点、不同患者样本,批次效应几乎无法完全避免。如果不做批次校正,聚类时很可能先按样本分开,而不是按细胞类型分开。
批次来自很多环节。取材时间不同、处理温度不同、消化条件不同、上机时间不同,都会引入差异。Seurat 等工具可以做整合和校正。严谨的原则是:先尽量在实验设计上减少批次,再用算法做补偿。 不能把算法校正当成实验设计的替代品。
4.2 细胞周期和 UMI 数也可能成为干扰项
除了批次效应,单细胞数据里还有协变量。最典型的是细胞周期。不同周期的细胞会呈现明显不同的表达模式。如果研究目标不是细胞周期本身,就应把这类信号作为协变量处理。
UMI 数也可能影响聚类。因为它反映的是捕获效率和测序深度的综合结果。若不处理,细胞可能按 UMI 高低聚类,而不是按真实生物学状态聚类。严谨分析的核心,不是把所有变化都保留下来,而是把与研究目标无关的变化尽量剥离。
5. 从聚类到注释,必须回到生物学问题
5.1 聚类只是起点,不是终点
完成清洗、标准化、特征筛选和批次处理后,才进入聚类。聚类的意义,是把表达模式相近的细胞分组,但分组本身不等于结论。 后续还要做 marker 基因识别、细胞注释和亚群验证。
对于医学生和医生来说,最容易犯的错误是“看到簇就直接下结论”。实际上,单细胞测序数据的严谨解释必须回到已知生物学知识。比如免疫细胞、上皮细胞、成纤维细胞的经典 marker 是否一致,才是判断注释是否可靠的关键。
5.2 需要时再做二次聚类
如果某类细胞是研究重点,比如 T 细胞或巨噬细胞,可以把对应 barcode 提取出来再做一次聚类和注释。这种二次分析能把大类中的亚型拆得更细,也更适合做机制研究。
这类思路在早期单细胞文章里很常见,现在仍然非常实用。先定位关键细胞群,再对关键群体做深挖,能让单细胞测序数据真正服务于课题设计,而不是只停留在一张图上。
6. 严谨分析的实操顺序建议
6.1 推荐按这个顺序推进
一个更稳妥的单细胞测序数据分析顺序如下。
- 获取表达矩阵、基因信息和细胞信息。
- 构建分析对象。
- 做质量控制,去掉空滴、双细胞和低质量细胞。
- 标准化表达矩阵。
- 筛选高变基因。
- 校正批次效应。
- 处理细胞周期、UMI 等协变量。
- 聚类、找 marker、做注释。
- 必要时对子群再次分析。
这个顺序的核心逻辑很简单,先清洗,再比较,后解释。 只要顺序反了,结果就容易失真。
6.2 结果解释要保留验证思维
单细胞结果再漂亮,也只是候选发现。最终仍要结合实验验证、公共数据库交叉验证,或独立队列验证。真正严谨的单细胞测序数据分析,不是追求图好看,而是追求结论可重复、可解释、可验证。
如果你做的是课题设计,后续还可以围绕 marker、差异基因、细胞通讯、拟时序、调控网络等方向继续延展。但前提永远是基础分析稳。基础不稳,后面的高级分析只会放大错误。
总结Conclusion
单细胞测序数据要做得严谨,关键不在于“用了多少高级算法”,而在于是否把前处理、质控、标准化、批次校正和协变量控制都做扎实。先保证数据干净,再谈生物学解释,才是单细胞分析的正确路径。
如果你希望把单细胞测序数据分析流程进一步落地到具体项目,解螺旋可以帮助你把分析框架、结果解读和课题逻辑串起来,减少走弯路。对于医学生、医生和科研人员来说,这种从数据到结论的规范化支持,往往比单纯堆算法更重要。
- 引言Introduction
- 1. 先弄清楚单细胞测序数据到底是什么
- 2. 质量控制是严谨分析的第一道门
- 3. 标准化和高变基因筛选决定后续解析质量
- 4. 批次效应和协变量处理决定结果是否可信
- 5. 从聚类到注释,必须回到生物学问题
- 6. 严谨分析的实操顺序建议
- 总结Conclusion