引言Introduction
Chip-seq数据质控是决定后续峰识别、差异结合分析能否可靠的第一步。很多项目失败,不是因为生物学问题,而是前期样本、建库或比对质量不过关。如果你想快速判断Chip-seq数据是否可用,先看这5个核心指标。
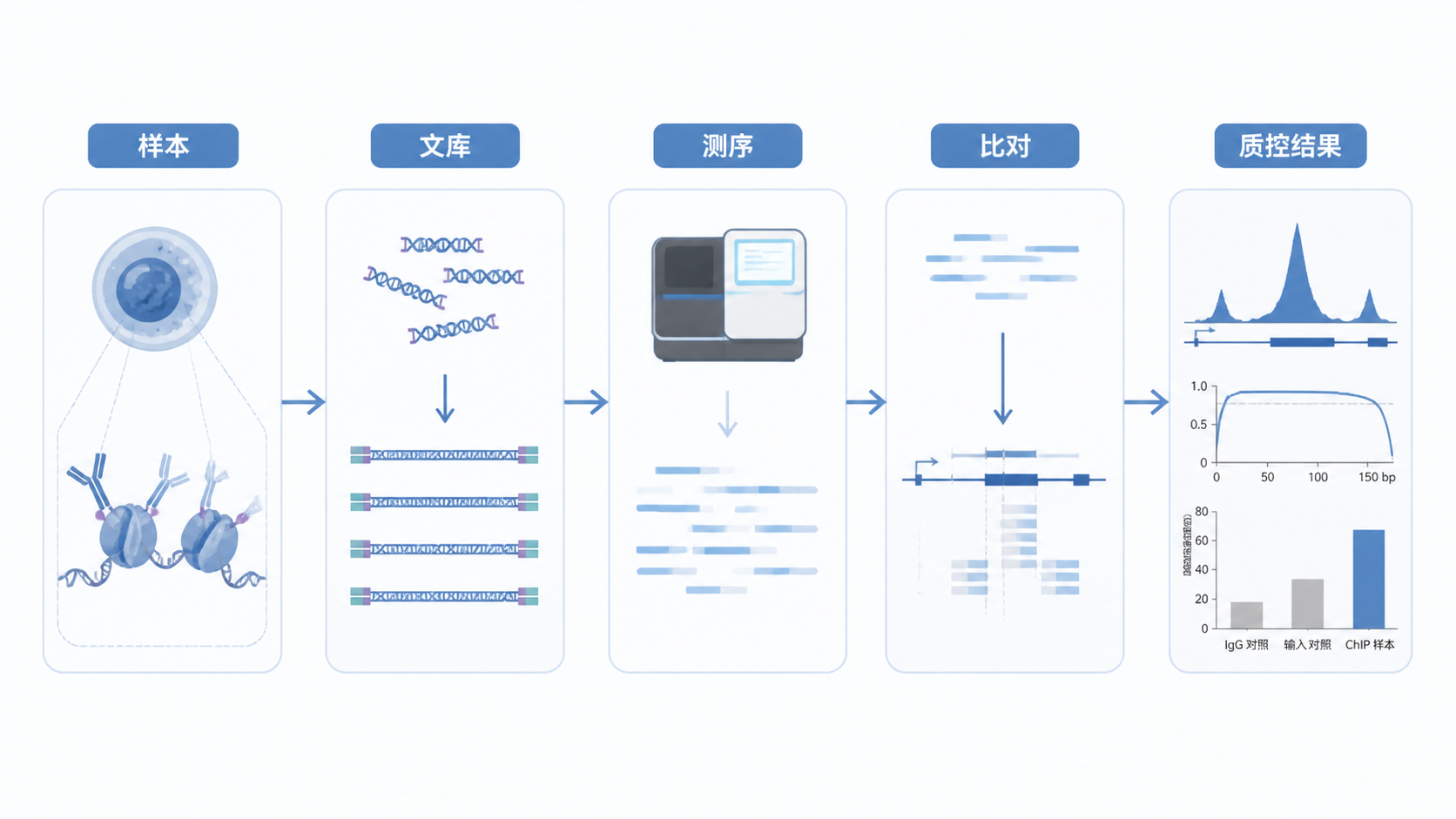
1. 测序深度与有效比对率
1.1 测序深度是否足够
Chip-seq数据首先要看测序量。对转录因子类样本,通常需要更高深度;对组蛋白修饰类样本,所需深度也会因靶标丰富度而变化。深度不足时,峰会变少,重复性也会下降。
判断时不能只看总reads数,更要结合研究目的。 如果是窄峰靶标,低深度往往直接影响峰检出。如果是宽峰靶标,低深度会让信号边界更模糊。
1.2 有效比对率是否理想
比对率反映reads能否成功映射到参考基因组。一般来说,有效比对率越高,数据越值得进一步分析。 但要注意,单看比对率还不够,还要排除重复率过高、污染和低复杂度文库。
常见检查点包括:
- 总reads数
- uniquely mapped reads比例
- multiple mapped reads比例
- 未比对reads比例
如果未比对reads异常高,优先排查物种污染、接头残留和参考基因组版本是否匹配。
2. 文库复杂度与重复率
2.1 重复率高,往往提示文库复杂度不足
Chip-seq数据中,PCR重复过多是常见问题。重复率高说明文库里可用片段有限,测到的信号可能更多来自扩增偏倚,而不是真实富集。
在实际分析里,重复率过高会导致:
- 峰数量虚高或虚低
- 峰强度不稳定
- 组间比较偏差增大
文库复杂度是Chip-seq数据质控的关键。 高重复率通常意味着起始材料不足、免疫沉淀效率不稳定,或PCR循环数过多。
2.2 如何理解复杂度
复杂度高的文库,reads分布更分散。相同位置被大量独立片段覆盖,说明信号更可信。相反,如果大量reads完全重叠,就要谨慎。
建议结合以下信息判断:
- PCR duplicate比例
- unique fragment比例
- library complexity指标
- 片段覆盖分布
3. 插入片段长度分布
3.1 片段长度是否符合实验设计
Chip-seq文库的插入片段长度分布,直接反映打断和建库是否合理。片段过短或过长,都会影响富集区域定位。
对标准Chip-seq来说,理想情况通常表现为:
- 主峰集中
- 分布相对单一
- 无明显异常拖尾
片段长度分布异常,常常提示超声打断不稳定,或者文库选择步骤不规范。
3.2 为什么这个指标重要
片段长度会影响:
- 峰的分辨率
- 结合位点定位精度
- 下游motif分析结果
尤其在转录因子Chip-seq中,片段长度过大可能让窄峰变宽,降低定位能力。对组蛋白修饰样本,宽峰信号本就连续,更需要片段分布稳定。
4. 富集信号与背景噪音
4.1 是否真正富集到目标区域
Chip-seq数据质控不能只看“有没有reads”,更要看“信号是否富集”。富集信号通常体现在目标区域峰值明显高于背景。
高质量Chip-seq数据应当表现为目标位点信号清晰,背景相对平稳。 如果全基因组到处都像高信号,往往说明非特异结合或背景污染偏高。
4.2 常用判断方式
实际分析中,常会看以下内容:
- 峰区域与非峰区域的信号差异
- IP样本与Input样本对比
- 信号覆盖图
- metaplot或profile图
如果IP和Input差异很小,说明富集效率可能不足。
如果背景过高,则可能是抗体特异性差、洗脱不充分,或样本制备环节存在问题。
没有明确富集,就很难得到可信的峰。
5. 样本重复一致性与可重复性
5.1 生物学重复是否一致
Chip-seq数据质控的最后一关,是看重复样本之间是否一致。技术上再漂亮的数据,如果重复之间差异很大,也不适合直接进入正式分析。
常见检查方式包括:
- Pearson相关性
- Spearman相关性
- PCA聚类
- 峰重叠率
- IDR分析
重复样本应尽量聚在一起。 如果同组样本彼此分散,而不同组反而更接近,往往提示批次效应或实验偏差。
5.2 低一致性意味着什么
重复一致性差,常见原因有:
- 免疫沉淀效率波动
- 细胞状态不一致
- 文库构建批次差异
- 测序深度不均衡
- 样本污染
对于研究型项目,建议在正式差异分析前先完成重复评估。
对于发表级数据,更要确保重复间具有较高一致性,否则结论可信度会明显下降。
6. 实际分析中如何快速判断
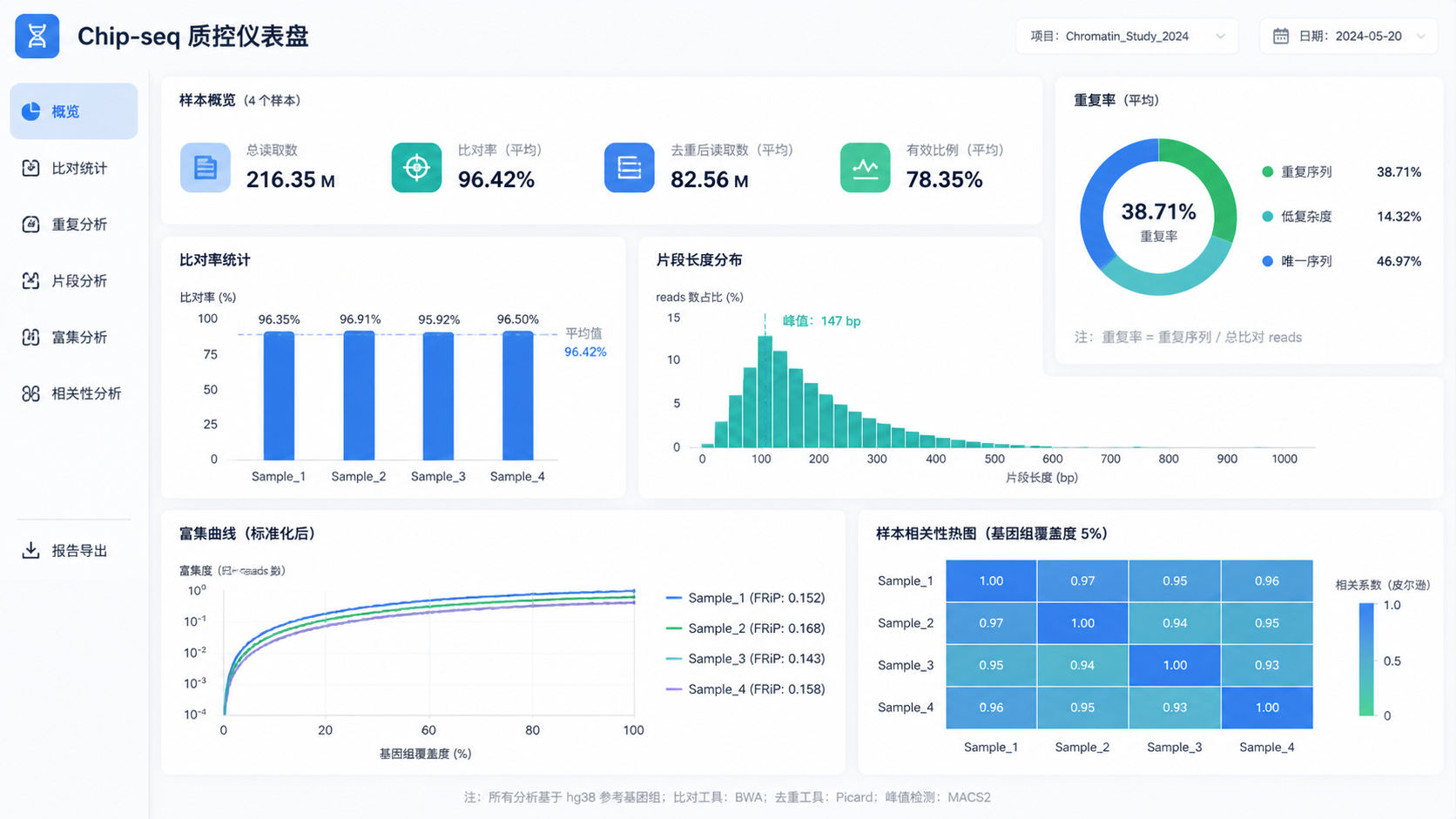
6.1 先看这几个文件和图
一个完整的Chip-seq数据质控流程,通常会先看:
- 测序统计表
- 比对统计表
- 重复率报告
- 插入片段分布图
- 峰图或富集图
- 样本相关性图或PCA图
这几项基本可以判断数据是否值得继续往下做。
6.2 质控不过关怎么办
如果发现Chip-seq数据存在明显问题,不建议直接进入峰调用。先回溯原因:
- 原始样本是否降解
- 抗体是否特异
- 文库是否过度扩增
- 测序深度是否不足
- 是否存在批次效应
问题定位后,再决定是否重做实验,或仅保留部分样本进入分析。
总结Conclusion
Chip-seq数据质控不是形式步骤,而是决定整套分析可靠性的基础。测序深度与比对率、文库复杂度与重复率、插入片段长度、富集信号、重复一致性,这5个指标缺一不可。 只要其中一项明显异常,后续峰识别和生物学解释都可能失真。
如果你希望把Chip-seq数据分析流程做得更稳、更快、更标准化,可以关注解螺旋品牌的生信内容与分析工具。它能帮助医学生、医生和科研人员更高效地完成质控判断、结果整理和下游分析,减少重复试错,把时间留给真正有价值的科研问题。
- 引言Introduction
- 1. 测序深度与有效比对率
- 2. 文库复杂度与重复率
- 3. 插入片段长度分布
- 4. 富集信号与背景噪音
- 5. 样本重复一致性与可重复性
- 6. 实际分析中如何快速判断
- 总结Conclusion